




In today’s data-driven world, web scraping is one of the most valuable techniques for gathering actionable insights. Whether you’re looking to monitor competitor prices, gather customer reviews, or track market trends, web scraping offers a systematic way to extract valuable data from the web. But it’s more than just scraping data – it’s about gathering it efficiently, ethically, and legally.
This comprehensive guide will dive deep into everything you need to know about web scraping, from the basics to advanced methods and the future of this ever-evolving technique.
Introduction to Web Scraping
What is Web Scraping?
Web scraping refers to process of automatically extracting data from websites, turning unstructured information into structured, usable insights. By using specialized software or scripts, businesses can collect vast amounts of publicly available data – such as pricing, product information, and market trends, quickly and efficiently. This technique has become invaluable across industries like e-commerce, real estate, and finance, offering a fast, automated way to gain actionable insights and maintain a competitive edge. Now, you might be clear about what does web scraping mean.
How Web Scraping Works?
Now, you have understood web scraping meaning, web scraping definition, and its basic functionality. Web scraping is a powerful tool that allows businesses to collect and analyze large amounts of data from websites. For companies in industries such as e-commerce, real estate, finance, travel, and many others, data drives strategic decision-making, pricing, and market analysis. Web scraping automates this process, saving time, resources, and offering the ability to extract vast amounts of data in real-time. But how exactly does web scraping work, and why is it so valuable to businesses?
Let’s break it down step by step.
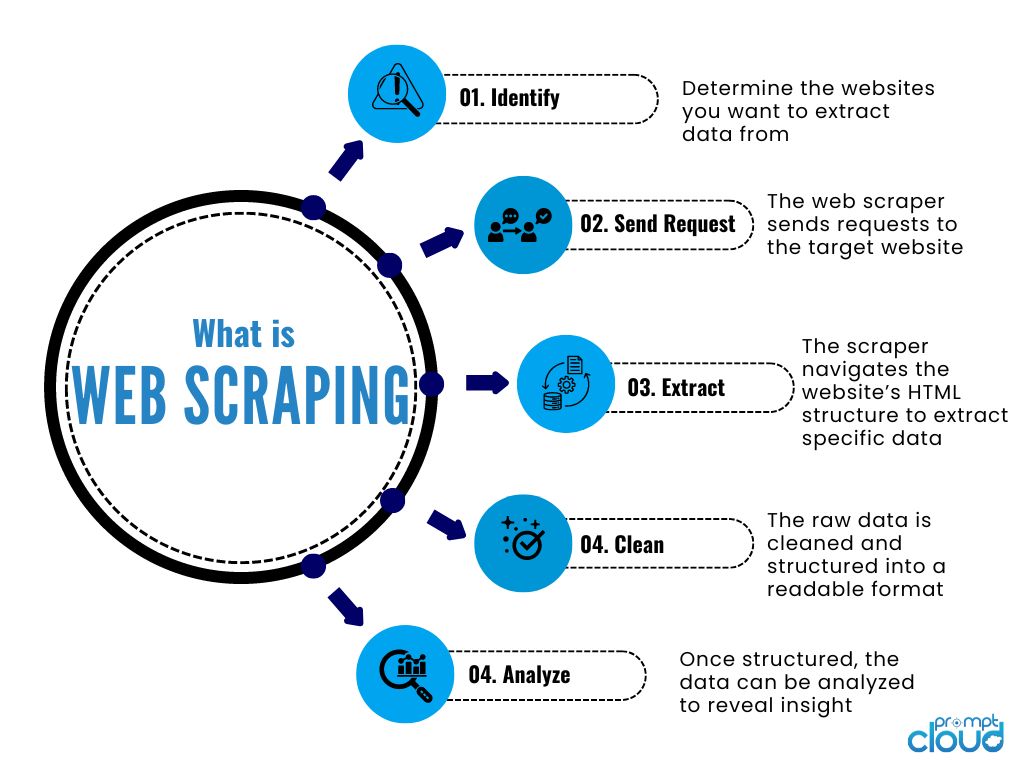
1. Sending a Request to the Website
The web scraping process begins with a request sent to a website’s server. This request is made using a scraper, which mimics the behavior of a user browsing the website. The scraper sends an HTTP request (usually GET or POST) to access the webpage you want to extract data from.
For example, if an e-commerce business wants to scrape product prices from an online retailer, the scraper sends a request to the specific product page URL. The server responds by sending back the HTML content of the page.
2. Parsing the HTML Structure
Once the server sends the HTML response, the scraper needs to parse the HTML structure of the webpage. The HTML file contains all the raw data, including text, images, and other elements.
Websites are made up of complex HTML structures, where the data you need is embedded in different tags (e.g., <div>, <span>, <table>, etc.). For example, if you want to extract product prices from an e-commerce site, the scraper will search for the specific HTML tags that contain the price information.
3. Data Extraction Using Selectors
Once the HTML is parsed, the scraper uses selectors like XPath, CSS selectors, or regular expressions to navigate the document and pinpoint the exact data it needs to extract.
- XPath: A language used to navigate through elements and attributes in an XML document (or HTML in this case).
- CSS Selectors: A pattern used to select the elements you want to extract.
4. Handling Dynamic Content
Some websites use dynamic content, meaning the data isn’t present in the static HTML but is loaded dynamically using JavaScript (AJAX). Traditional scrapers can struggle with this, as they might only capture the initial HTML, which doesn’t contain the desired data.
To overcome this challenge, scrapers can use tools like Selenium or Puppeteer that render JavaScript-heavy websites, simulating user interactions in a browser. These tools load the page in a headless browser and allow the scraper to access the dynamically loaded content.
5. Storing and Structuring the Data
After the data is successfully extracted, it’s essential to store and structure the information. Raw data scraped from websites is usually unorganized, so businesses need it in a structured format like CSV, JSON, or databases to integrate it into their existing systems for analysis.
6. Automation and Scheduling
One of the key advantages of web scraping is the ability to automate the data collection process. For businesses, it’s critical to monitor certain data in real-time or at regular intervals, such as daily, weekly, or monthly updates. By setting up automated scripts or scheduling, companies can continually collect updated data without manual intervention.
Legal Aspects of Web Scraping: How to Ensure Compliance?
As scraping becomes a critical need for businesses looking to extract valuable data from websites, understanding the legal landscape surrounding this practice is more important than ever. While web scraping offers immense benefits, its legality is complex, and companies need to navigate this territory carefully to avoid legal pitfalls.
Is Web Scraping Legal?
Well, the short answer: It depends.

Web scraping, in its most basic form—automated data collection from public websites—is generally legal when done responsibly. However, web scraping legality concerns arise when scrapers violate a website’s terms of service (ToS), breach copyright laws, or access private data without authorization. The legal framework for web scraping legal issues is still evolving, and different regions have different interpretations of its legality.
Essential Legal Considerations for Web Scraping
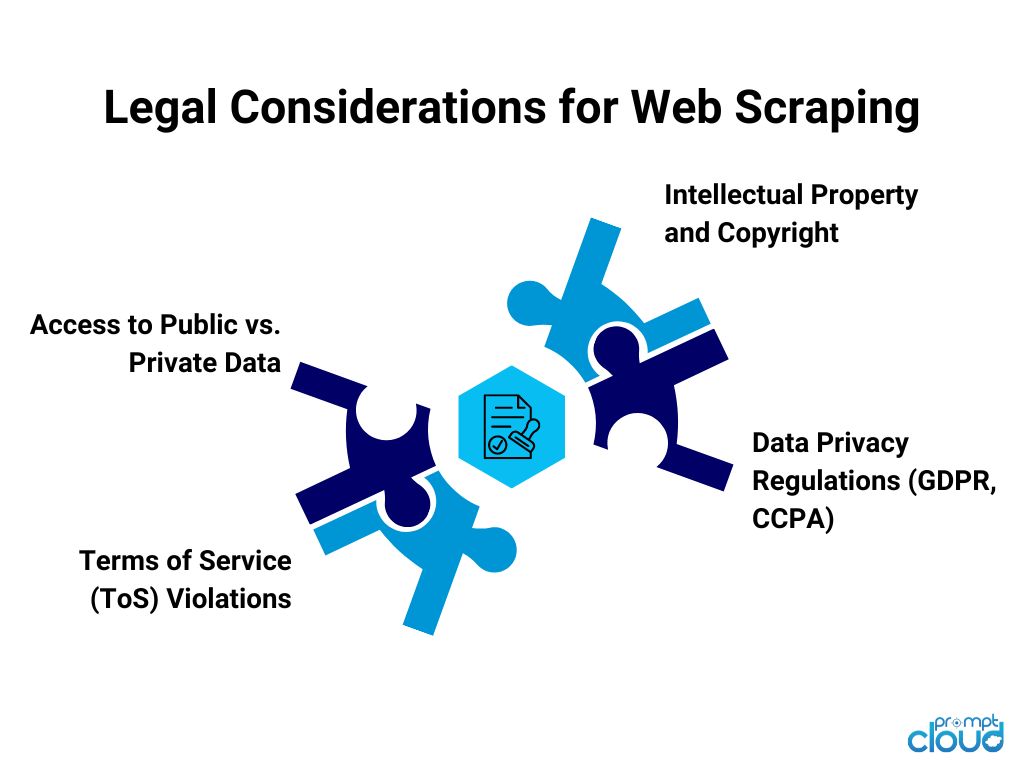
1. Access to Public vs. Private Data
- Web scraping is typically considered legal when it targets publicly available information on the web, such as product listings, prices, or public reviews.
- However, scraping data that is behind a login wall or requires authentication (e.g., private user profiles) can cross legal boundaries, especially if it involves bypassing security measures like CAPTCHAs or firewalls.
2. Terms of Service (ToS) Violations
- Many websites outline restrictions in their terms of service, prohibiting automated data collection. Violating these terms can expose companies to legal risks, as it’s considered a breach of contract.
- However, a breach of ToS on its own does not always result in a legal violation, depending on the jurisdiction.
3. Intellectual Property and Copyright
- Scraping copyrighted content (e.g., articles, images, or proprietary databases) without permission can lead to copyright infringement claims. Even though scraping data doesn’t mean reproducing it, if the content is used for commercial purposes, it can trigger legal action.
4. Data Privacy Regulations (GDPR, CCPA)
- With the rise of privacy regulations like the General Data Protection Regulation (GDPR) in Europe and the California Consumer Privacy Act (CCPA) in the United States, businesses must be cautious when scraping any data that may be considered personal information.
- Scraping personal data without consent or processing it in non-compliant ways can lead to hefty fines and penalties under these laws.
Legal Landscape of Web Scraping in Various Regions
The legality of web scraping varies significantly from one region to another. Here’s a closer look at how web scraping laws are interpreted across key regions:
United States
Is web scraping legal in US? In the U.S., web scraping exists in a legal gray area. Courts have ruled both in favor and against web scraping in various high-profile cases. The primary legal frameworks affecting web scraping in the U.S. are:
- Computer Fraud and Abuse Act (CFAA):
The CFAA is a U.S. law designed to combat unauthorized access to computer systems. It has been used in several court cases to argue against web scraping, especially in situations where the scraper bypassed security measures, such as login walls or CAPTCHAs.
In the famous hiQ Labs v. LinkedIn case, LinkedIn sued hiQ Labs for scraping public LinkedIn profiles. The court initially ruled in favor of hiQ, stating that scraping publicly accessible data did not violate the CFAA. However, this case illustrates the fine line businesses must walk—while scraping public data may be legal, bypassing access restrictions or violating ToS may result in legal consequences.
European Union
Europe is stricter when it comes to data privacy and web scraping, especially with the introduction of the General Data Protection Regulation (GDPR). Under GDPR, scraping personal data—such as user names, email addresses, or IP addresses—requires explicit consent from the individuals involved. Companies must also ensure they have a legal basis for processing this data.
- GDPR Penalties:
If web scraping involves personal data and violates GDPR, companies face penalties of up to €20 million or 4% of their annual global turnover, whichever is higher.
Example:
Suppose a company scrapes personal data from user reviews or profiles on European e-commerce websites without the users’ consent. This could potentially violate GDPR’s data privacy requirements, putting the business at risk of severe fines.
Other Regions
- Canada: The Personal Information Protection and Electronic Documents Act (PIPEDA) governs how companies handle personal data. As in the EU, scraping personal data without consent can lead to penalties.
- Australia: The Australian Privacy Act restricts the collection and use of personal information. Web scraping that involves personal data without the user’s knowledge or consent could lead to legal action.
- India: While web scraping is not explicitly illegal in India, businesses must be cautious about scraping personal data, especially with the impending Personal Data Protection Bill which aligns with GDPR principles.
Best Practices for Ethical and Legal Web Scraping
Aside from legal concerns, there are ethical considerations that businesses must take into account when engaging in scraping activities. Ethical web scraping focuses on respecting website owners’ intentions, user privacy, and the general ecosystem of the web.

- Respect Robots.txt Files:
Websites often include a robots.txt file, which indicates what parts of the site are open to being crawled by search engines and scrapers. Ethical scrapers should adhere to these instructions, avoiding pages that are explicitly disallowed. - Avoid Overloading Servers:
Web scrapers can generate a large number of requests in a short amount of time. Ethical scrapers should avoid sending too many requests in rapid succession, as this can slow down the website or even crash servers. - Avoid Scraping Personal Data Without Consent:
Even if personal information is publicly available, ethical scrapers should refrain from collecting data that could be considered sensitive without first gaining permission or ensuring compliance with data privacy laws. - Give Credit Where It’s Due:
If you’re scraping content from a website, consider giving credit or linking back to the source when possible, especially if the data is used for public-facing purposes.
Web scraping is a valuable tool for businesses, but the legal landscape requires careful navigation. To stay compliant and avoid legal issues, companies should:
- Scrape only publicly available data and avoid scraping content that is copyrighted or requires user authentication.
- Respect terms of service and be mindful of website restrictions, such as those stated in the robots.txt file.
- Ensure compliance with data privacy laws, especially when scraping personal information, and stay informed about regional regulations like GDPR, CCPA, and others.
- Adopt ethical best web scraping practices by avoiding overloading servers and respecting the privacy of individuals.
By staying within legal and ethical boundaries, businesses can harness the power of web scraping without running the risk of costly lawsuits or regulatory penalties.
How to Choose the Right Web Scraping Tool?
Web scraping is a versatile technique that can be applied across industries to gather valuable data from the web. However, the success of your web scraping efforts depends heavily on the tools and libraries you choose. From simple HTML parsing to handling dynamic content and overcoming anti-scraping measures, there’s a wide range of tools available—each suited to different needs.
Common functionalities of web scraping tools include:
- HTML parsing: Extracting specific elements or sections from the HTML of a webpage.
- Handling dynamic content: Scraping data from websites that use JavaScript or AJAX to load content.
- Dealing with anti-scraping mechanisms: Tools that use techniques like IP rotation or headless browsing to avoid detection.
Choosing the right scraping tool for your web scraping project depends on factors like the structure of the website, the data volume, the frequency of scraping, and the complexity of the content (static vs. dynamic).
Pros and Cons of Best Web Scraping Tools
Each web scraping software has its strengths and weaknesses. The key to successful scraping lies in matching the right tool to the project’s specific needs.
1. BeautifulSoup (Python)
Pros:
- Simple to use for beginners.
- Best suited for basic scraping tasks (static pages).
- Excellent for parsing HTML and XML.
- Easily integrates with other Python libraries like requests.
Cons:
- Not designed for large-scale scraping.
- Cannot handle heavy websites that uses Javascript or dynamic content.
Ideal for smaller projects and websites with static HTML. For instance, scraping simple data like product descriptions and prices from small e-commerce sites.
2. Scrapy (Python)
Pros:
- A full-fledged web scraping framework.
- Supports crawling, data extraction, and data storage.
- Highly scalable for larger scraping projects.
- Handles dynamic content when combined with other libraries like Selenium.
- Built-in support for handling requests, following links, and pagination.
Cons:
- Has a steep learning curve for beginners.
- Requires more setup and configuration compared to BeautifulSoup.
Suited for large-scale web scraping projects that require scraping multiple pages, following links, and handling large datasets. For example, scraping real estate listings across multiple regions.
3. Selenium
Pros:
- Automates browsers, making it perfect for scraping websites with JavaScript-rendered content.
- Can interact with websites (e.g., logging in, clicking buttons).
- Supports multiple languages (Python, Java, C#, etc.).
Cons:
- Slower than other scraping libraries because it opens a browser instance.
- Requires more resources (CPU, memory) to run.
Selenium is best for scraping dynamic content on complex websites, such as booking sites that load prices and availability with JavaScript after interacting with dropdowns or date pickers.
4. Puppeteer (JavaScript)
Pros:
- Provides headless browser automation, similar to Selenium but optimized for Code-heavy websites.
- Natively supports Google Chrome, offering better performance for scraping sites that heavily rely on JavaScript.
Cons:
- Requires knowledge of Node.js.
- Can be overkill for simpler scraping tasks that don’t involve dynamic content.
Great for web scraping modern web applications, such as social media platforms or single-page applications where JavaScript plays a central role in rendering content.
5. Requests and lxml (Python)
Pros:
- Requests is an HTTP library that simplifies sending HTTP requests (GET, POST).
- lxml is fast and efficient for parsing HTML and XML.
- Lightweight and easy to use for basic scraping tasks.
Cons:
- Like BeautifulSoup, it cannot handle JavaScript-rendered content.
Ideal for simple scraping tasks, such as extracting data from blogs, news articles, or product listings on sites with static content.
How to Choose the Right Web Scraping Tool Based for your Project?
Selecting the right web scraping tool is crucial to ensure your project runs efficiently, effectively, and within the necessary legal and technical boundaries. Different projects have unique requirements, and no single tool fits every scenario. To help guide your decision, here are the key factors to consider when choosing the best web scraping tool for your specific project needs:
1. Type of Website (Static vs. Dynamic Content)
- Static websites serve content directly from HTML without requiring JavaScript for rendering. Tools like BeautifulSoup or Cheerio are ideal for scraping static content, as they can easily parse and extract data from simple HTML structures.
- Dynamic websites rely heavily on JavaScript to load content dynamically, often using AJAX requests. In such cases, tools like Selenium or Puppeteer are better suited because they can interact with the website just like a real user, rendering JavaScript and scraping dynamic elements.
If you’re scraping a product catalog from a static e-commerce page, BeautifulSoup or Scrapy would suffice. For scraping live stock prices or flight availability (which often requires dynamic loading), Selenium or Puppeteer would be the better choice.
2. Scale of the Project
Consider the amount of data you need to scrape. The tool you choose must be able to handle the volume of data efficiently.
- Small-scale projects: If you’re scraping a few web pages occasionally, lightweight tools like BeautifulSoup or Cheerio are sufficient.
- Large-scale projects: For large-scale, ongoing scraping projects involving thousands or millions of pages, opt for frameworks like Scrapy, which offer asynchronous scraping and built-in support for parallel requests, making them more efficient at handling large datasets.
A small blog scraping project would work well with BeautifulSoup. However, if you’re scraping daily product listings across multiple websites with millions of pages, a tool like Scrapy or a custom web scraping service would be more appropriate.
3. Technical Expertise Required
The complexity of the tool should match the technical proficiency of your team:
- Beginners or businesses with limited technical resources should opt for user-friendly tools like Octoparse or ParseHub, which offer no-code solutions and visual interfaces, allowing non-technical users to set up scrapers with ease.
- Developers or teams with technical expertise can benefit from tools like Scrapy or Puppeteer, which offer full control and flexibility but require coding skills.
If you have a development team comfortable with web scraping with Python, Scrapy or Selenium would give you greater flexibility and customization. If you lack technical resources and need a simple solution, a no-code platform like Octoparse might be more suitable.
4. Handling Anti-Scraping Measures
Many websites implement anti-scraping measures like CAPTCHA tests, rate-limiting, or IP blocking to prevent bots from extracting data. The tool you choose should be able to navigate these web scraping challenges:
- Tools like Selenium and Puppeteer allow you to interact with the website just like a real user, which helps bypass basic anti-scraping defenses.
- For IP rotation and CAPTCHA-solving, it’s best to use a tool with built-in proxy support or a third-party service.
If you’re scraping a website with strict anti-bot measures, Selenium paired with rotating proxies and a CAPTCHA-solving service would be the best option.
5. Frequency and Automation Requirements
Some projects require one-time scraping, while others need continuous or scheduled scraping:
- For one-time scraping projects, simple libraries like BeautifulSoup or Jsoup can handle the task.
- For ongoing or regularly scheduled scraping, you’ll need a tool that supports automation and scheduling, like Scrapy with its built-in scheduling and automation features.
If you need to monitor prices on a weekly basis, Scrapy can automate the scraping schedule. For a one-time data extraction project, BeautifulSoup may be more than enough.
Comparison of Paid vs. Free Web Scraping Tools
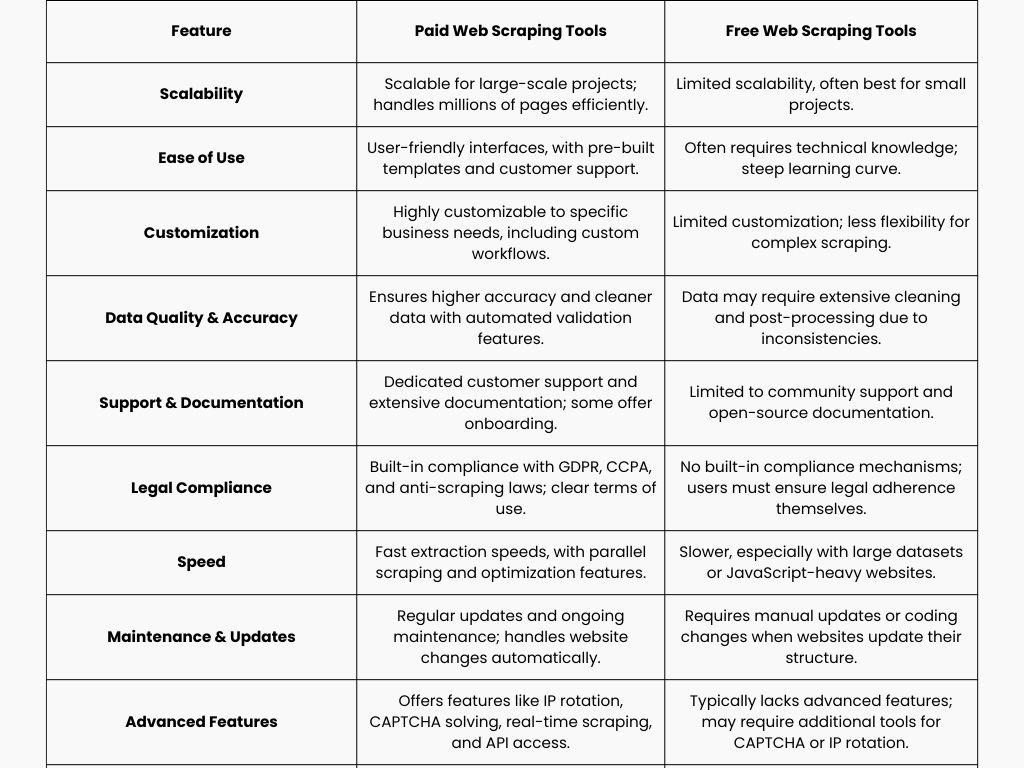
When deciding between paid and free web scraping tools, businesses must evaluate their specific needs, technical expertise, budget, and long-term goals. While free tools offer flexibility and cost savings, paid tools often provide additional features, better support, and ease of use for non-technical users. Here’s a detailed comparison to help you choose the right option for your web scraping project.
Free Web Scraping Tools
Free web scraping tools are typically open-source libraries or frameworks that allow developers to create custom scrapers tailored to their specific data needs. Popular free tools include BeautifulSoup, Scrapy, Selenium, and Puppeteer.
Advantages of Free Tools:
- Cost-Effective:
- Free tools are perfect for businesses on a tight budget since there are no licensing or subscription fees. They provide a cost-efficient way to start scraping without upfront investments.
- Flexibility and Customization:
- Open-source tools offer complete flexibility. Developers can write customized scripts, fine-tune the scraping process, and modify the tool’s code to fit their exact requirements.
- Large Developer Community:
- Free tools are often backed by active developer communities, providing support, forums, and extensive documentation. This community-driven approach also means the tool is regularly updated.
- No Usage Limits:
- With free tools, there are typically no limitations on data volume, frequency, or how many websites you can scrape. You can scale scraping projects according to your infrastructure capabilities.
Disadvantages of Free Tools:
- Steep Learning Curve:
- Free tools like Scrapy, Selenium, or BeautifulSoup require coding knowledge and technical expertise. Businesses without a development team may struggle to set up and maintain these tools.
- No Official Support:
- While free tools have active communities, they lack official customer support. If something breaks or a website changes its structure, you’ll have to troubleshoot and fix the issue on your own.
- Time-Consuming:
- Writing and maintaining scrapers from scratch can be time-consuming, especially for larger projects. Managing anti-scraping measures like CAPTCHA, IP rotation, and rate limits requires additional time and technical effort.
- Limited Advanced Features:
- Free tools don’t offer built-in solutions for common web scraping challenges like IP rotation, proxy management, or capturing dynamic content without significant custom setup.
Paid Web Scraping Tools
Paid tools, often SaaS platforms or managed services like Octoparse, ParseHub, or PromptCloud, offer a more user-friendly approach to web scraping. These tools often feature drag-and-drop interfaces, integrated support for handling anti-scraping measures, and official customer support.
Advantages of Paid Tools:
- Ease of Use (No Coding Required):
- Paid tools are designed for non-technical users, offering visual interfaces or point-and-click features that make setting up a scraper easy without writing any code.
- Official Support and Maintenance:
- One of the biggest benefits of paid tools is dedicated customer support. If issues arise, paid platforms typically offer assistance, ensuring minimal downtime and efficient troubleshooting.
- Advanced Features:
- Paid tools often include built-in solutions for IP rotation, CAPTCHA-solving, and data export in multiple formats (CSV, JSON, API). These features are essential for scraping large websites or overcoming sophisticated anti-scraping techniques.
- Automation and Scheduling:
- Many paid platforms provide automated data extraction, enabling users to schedule scrapes and receive real-time data updates without manual intervention.
- Scalability and Security:
- Paid solutions are better suited for large-scale data scraping needs. They offer robust infrastructure that can handle millions of pages efficiently, and they often include additional security measures, such as compliance with legal regulations.
Disadvantages of Paid Tools:
- Cost:
- Paid tools come with subscription fees or pricing models based on the volume of data scraped. This can become expensive, especially for businesses that require large-scale or continuous scraping operations.
- Limited Customization:
- While paid tools provide ease of use, they may lack the flexibility and customization that free, open-source tools offer. Advanced users or those with complex scraping needs may find the features of paid tools somewhat restrictive.
- Potential Data Limits:
- Some paid tools impose data limits based on the pricing plan. This can be a drawback for companies needing to scrape large volumes of data regularly.
How to Use Python for Web Scraping? Tips & Best Practices
Python web scraping is widely regarded as the go-to language, and it’s easy to see why. With its simple syntax, powerful libraries, and an extensive community, Python makes it easier for developers to extract data from the web efficiently. Whether you’re a beginner scraping a handful of web pages or an experienced developer handling large-scale scraping tasks, Python web scraping provides the flexibility and power to get the job done.
In this section, we’ll explore why Python is a preferred language for web scraping, introduce some of the most popular Python libraries used for web scraping, and provide tutorials and best practices to help you get started.
Why Python Is the Preferred Language for Web Scraping?
Python has become the best programming language for web scraping due to several key factors:
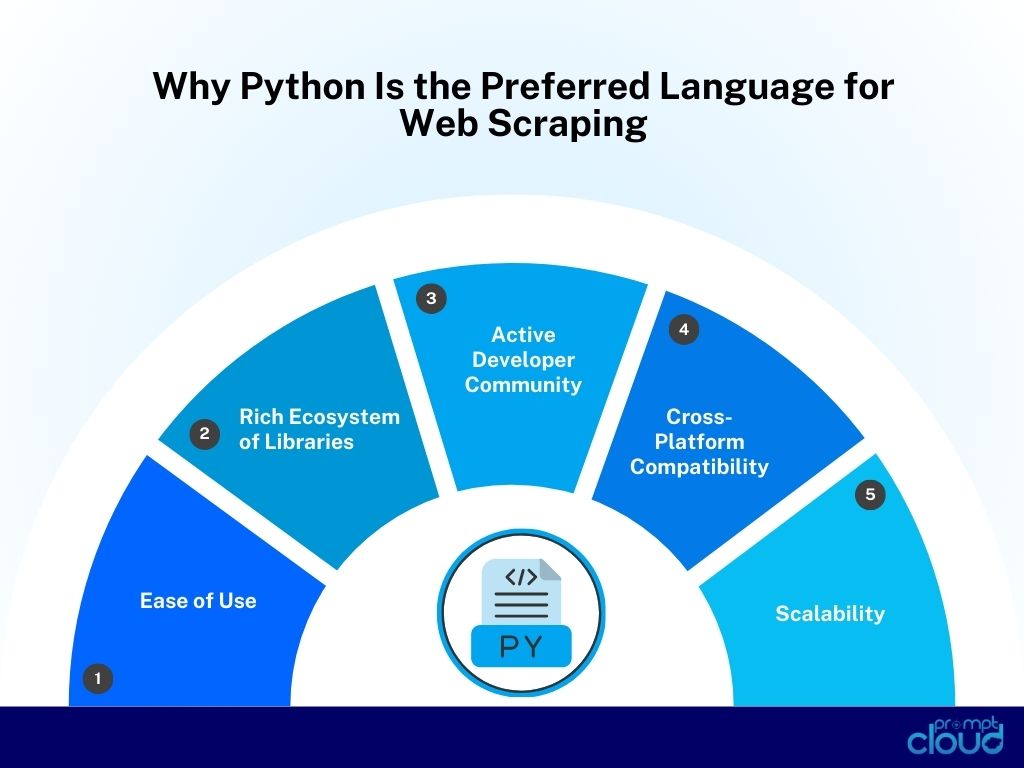
- Ease of Use: Python’s clean and readable syntax allows developers to write fewer lines of code to accomplish complex tasks, making it especially accessible for beginners.
- Rich Ecosystem of Libraries: Python boasts an extensive range of open-source libraries designed for web scraping. These libraries simplify tasks like HTML parsing, browser automation, handling dynamic content, and interacting with web APIs.
- Active Developer Community: Python has a vibrant and active community that continually contributes to the development of scraping libraries, offers support, and provides best practices.
- Cross-Platform Compatibility: Python is compatible with all major operating systems (Windows, macOS, Linux), making it versatile for different environments.
- Scalability: Python’s web scraping libraries can handle small tasks as well as large-scale, automated scraping projects, making it ideal for businesses that need to extract and analyze large datasets.
Popular Python Libraries for Web Scraping
Several Python libraries are specifically built for web scraping, each offering unique features that cater to different scraping needs. Below, we’ll provide an overview of the most widely used Python libraries:
1. BeautifulSoup: For HTML Parsing and Extraction
BeautifulSoup is one of the simplest and most widely used libraries for web scraping. It is designed for parsing HTML and XML documents, allowing users to navigate the document’s structure and extract the data they need.
- Key Features:
- Easy-to-use syntax for extracting data from HTML and XML files.
- Supports a variety of parsers, with html.parser being the most commonly used.
- Works well with smaller websites that don’t rely on JavaScript for content rendering.
2. Scrapy: For Advanced Scraping Projects
Scrapy is a powerful and fast Python framework designed for large-scale scraping projects. It allows for asynchronous scraping, which makes it highly efficient for handling multiple pages at once. Scrapy also has built-in support for crawling, following links, and storing data in various formats.
- Key Features:
- Built-in support for extracting data from websites and following links to other pages.
- Asynchronous scraping for faster data extraction.
- Integration with databases and cloud storage for data handling.
- Strong support for scheduling and automation of scraping tasks.
3. Selenium: For Automating Browsers and Handling Dynamic Content
Selenium is a popular tool for browser automation that allows you to interact with web pages in real time. It’s particularly useful for scraping large websites or pages that require user actions like clicks or logins. Selenium controls a web browser directly, simulating human behavior, which allows it to render JavaScript and access dynamically loaded content.
- Key Features:
- Simulates browser interactions such as clicking buttons, filling forms, and navigating pages.
- Ideal for scraping dynamic websites that load content using JavaScript or AJAX.
- Cross-browser support for Chrome, Firefox, and others.
4. Requests and lxml: For Simple Scraping Tasks
The Requests library is one of the most popular Python web scraping library for sending HTTP requests and retrieving the content of web pages. When paired with lxml, it becomes a lightweight solution for extracting data from static HTML pages.
- Key Features:
- Requests handles HTTP requests, providing a simple way to download web pages.
- lxml provides fast parsing of HTML and XML content, allowing for easy data extraction using XPath or CSS selectors.
- Suitable for small to medium scraping tasks on static websites.
Pros and Cons of Using Different Languages for Web Scraping
Each programming language offers unique strengths when it comes to web scraping. Here’s a quick comparison to help you choose the right one for your project:
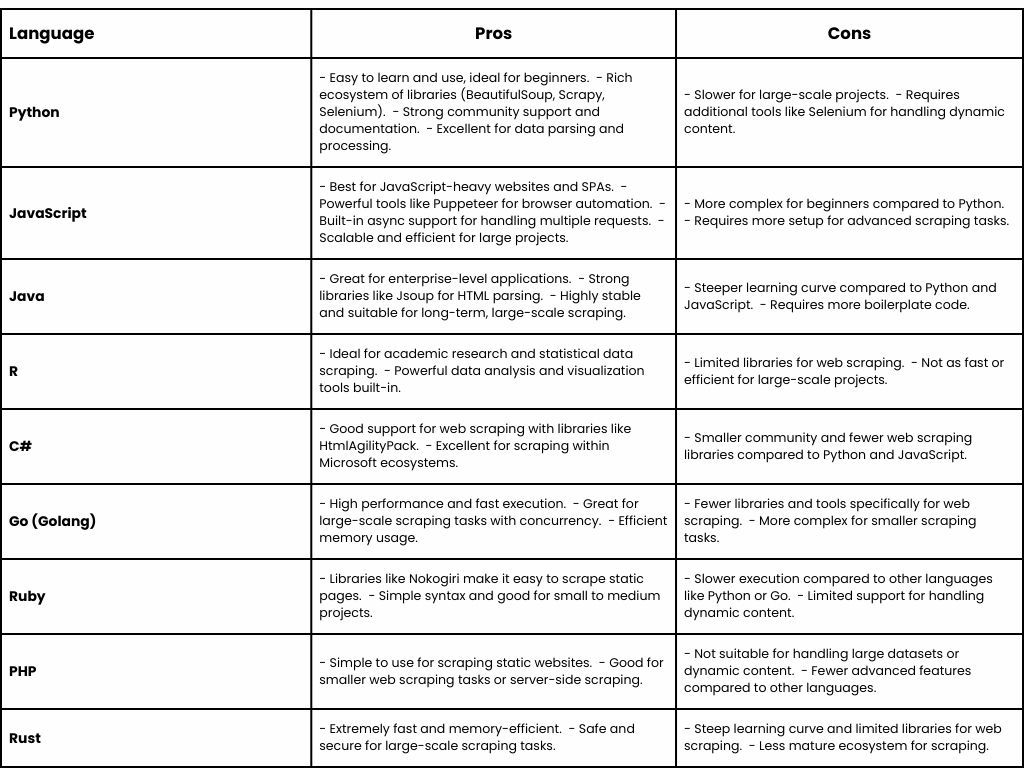
Choosing the right language depends on your specific requirements—Python and JavaScript remain the most accessible and versatile, while Go and Java offer performance and scalability for enterprise applications.
Python Web Scraping Tutorial
Here are a few step-by-step examples of how to use these Python libraries:
1. Scraping a Product Page with BeautifulSoup
import requests
from bs4 import BeautifulSoup
# Send a request to the product page
response = requests.get(‘https://example.com/product’)
# Parse the HTML content
soup = BeautifulSoup(response.text, ‘html.parser’)
# Extract product name and price
product_name = soup.find(‘h1′, class_=’product-title’).text
product_price = soup.find(‘span’, class_=’price’).text
print(f’Product: {product_name}, Price: {product_price}’)
2. Scraping Multiple Pages with Scrapy
import scrapy
class ProductSpider(scrapy.Spider):
name = ‘products’
start_urls = [‘https://example.com/category/page1’]
def parse(self, response):
for product in response.css(‘div.product’):
yield {
‘name’: product.css(‘h2.product-title::text’).get(),
‘price’: product.css(‘span.price::text’).get(),
}
# Follow pagination links
next_page = response.css(‘a.next::attr(href)’).get()
if next_page:
yield response.follow(next_page, self.parse)
3. Handling Dynamic Content with Selenium
from selenium import webdriver
from selenium.webdriver.common.by import By
# Set up the WebDriver
driver = webdriver.Chrome()
# Open the dynamic website
driver.get(‘https://example.com/login’)
# Fill the login form
username = driver.find_element(By.NAME, ‘username’)
password = driver.find_element(By.NAME, ‘password’)
username.send_keys(‘my_username’)
password.send_keys(‘my_password’)
# Submit the form
login_button = driver.find_element(By.XPATH, ‘//button[@type=”submit”]’)
login_button.click()
# Wait for the page to load and scrape data
data = driver.find_element(By.ID, ‘data-id’).text
print(data)
driver.quit()
Best Practices for doing Web Scraping using Python:
- Respect Website Rules and Policies: Always check the robots.txt file to see which parts of the website are allowed for scraping.
- Throttle Your Requests: Implement rate limiting to avoid overloading the website’s server. Sending too many requests in a short period can result in your IP being blocked.
- Use Proxies and IP Rotation: For large-scale scraping or scraping websites with anti-bot measures, using proxies and rotating IPs can help avoid being blocked.
- Handle Errors Gracefully: Always include error handling in your scraping scripts to manage potential issues like timeouts, missing data, or blocked requests.
- Keep an Eye on Legal Compliance: Ensure you’re following local laws and regulations, such as GDPR or CCPA, when scraping data
Selenium Web Scraping
Selenium is one of the most versatile and powerful tools for web scraping, especially when dealing with dynamic websites that rely on JavaScript to load content. Unlike traditional python web scraping libraries like BeautifulSoup and Scrapy, which are limited to static HTML, Selenium mimics user behavior by automating browser interactions. This makes it an ideal choice for scraping JavaScript-heavy websites, filling out forms, navigating through pages, and handling complex dynamic content.
In this section, we’ll explore Selenium’s applications in web scraping, provide a step-by-step guide to using Selenium for scraping dynamic websites, and offer tips for overcoming common challenges such as CAPTCHAs and JavaScript rendering.
Using Selenium for Scraping Dynamic Websites
Selenium is highly effective for scraping websites that rely on JavaScript to display content. This detailed guide will walk you through the process of using Selenium for web scraping.
1. Installing Selenium and Setting Up WebDriver
To get started with Selenium, you’ll need to install the Selenium package and set up the WebDriver, which acts as an interface between your code and the browser. Here’s how you can install Selenium and set up a WebDriver in Python.
Step 1: Install Selenium using pip.
pip install selenium
Step 2: Download the WebDriver for the browser you intend to use (e.g., Chrome, Firefox). For Chrome, you can download ChromeDriver from here.
Step 3: Set up the WebDriver in Python:
from selenium import webdriver
# Set up the WebDriver for Chrome
driver = webdriver.Chrome(executable_path=’/path/to/chromedriver’)
# Open a website
driver.get(‘https://example.com’)
# Extract the title of the page
page_title = driver.title
print(page_title)
# Close the browser
driver.quit()
2. Extracting Data from a Dynamic Website
Once the WebDriver is set up and you’ve navigated to the webpage, you can extract data using Selenium’s selectors. Unlike other scraping tools, Selenium works with XPath, CSS selectors, and JavaScript execution to retrieve elements from the web page.
Step 1: Access and extract elements using XPath or CSS selectors.
# Find an element by XPath
element = driver.find_element_by_xpath(‘//h1’)
# Extract and print the text from the element
print(element.text)
Step 2: Handle dynamic content with waiting.
Some dynamic websites may take time to load data after the page is first opened. Selenium provides explicit waits to ensure that the content is fully loaded before the scraping begins.
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Wait for an element to become visible
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, ‘//h1’))
)
# Extract the text once the element is visible
print(element.text)
Tips for Overcoming Common Challenges in Selenium Web Scraping
While Selenium is incredibly powerful, it comes with its own set of challenges. Below are some tips for overcoming the most common obstacles encountered when scraping with Selenium:

1. Handling CAPTCHAs
Many websites use CAPTCHA to prevent bots from accessing their data. Here are a few strategies for handling CAPTCHAs:
- Use CAPTCHA-Solving Services: Services like 2Captcha or Anti-Captcha can be integrated with Selenium to solve CAPTCHAs automatically.
- Manual CAPTCHA Solving: For smaller projects, you can prompt the user to solve the CAPTCHA manually and then resume scraping.
- Avoid CAPTCHA-Heavy Sites: If possible, avoid websites that aggressively use CAPTCHAs by scraping alternative sources or less restrictive sites.
2. Handling JavaScript-Heavy Websites
For websites that heavily uses Javascript, it’s crucial to let the page fully load before scraping. Use explicit waits to ensure the content is ready before attempting to extract data.
3. Using Headless Browsing for Faster Scraping
Running Selenium with a graphical browser can be resource-intensive and slow. To speed up the process, you can run Selenium in headless mode, where the browser runs in the background without opening a visual window.
4. Managing IP Blocks and Rate Limits
Some websites detect and block scraping activity by monitoring IP addresses or the rate of requests. To avoid this:
- Use Proxies: Rotate proxies to prevent your IP from being blocked.
- Throttle Requests: Introduce random delays between requests to avoid detection.
- Set User-Agent Headers: Change the User-Agent string to mimic different browsers and devices, making your scraper appear more like a real user.
Selenium is an indispensable tool for scraping JavaScript-heavy websites, handling dynamic content, and automating complex interactions. By simulating user actions, Selenium allows businesses to extract valuable data from websites that would be inaccessible with traditional web scraping libraries.
Whether you need to scrape content behind login forms, fill out dynamic web forms, or navigate through multiple pages, Selenium’s browser automation capabilities make it an ideal solution. By combining Selenium with other tools like BeautifulSoup and implementing best practices such as handling CAPTCHAs and using proxies, you can build efficient and scalable scraping solutions for even the most complex web environments.
JavaScript Web Scraping
JavaScript is critical for web scraping in today’s landscape due to the increasing complexity of modern web applications. Many websites now rely heavily on JavaScript frameworks (like React, Angular, and Vue) to dynamically load content via AJAX or client-side rendering. Traditional scraping methods, which simply parse HTML, often fail to capture this content. This is where JavaScript-based web scraping comes into play.
JavaScript-powered tools allow businesses to:
- Handle dynamic content: Websites using JavaScript frameworks don’t load all their data in the initial HTML. Instead, JavaScript renders the page elements after loading. JavaScript-based scrapers can execute these scripts and access dynamic data that traditional scrapers miss.
- Simulate user interactions: Many modern applications require user actions such as clicks, scrolling, and form submissions. JavaScript web scraping can replicate these actions.
- Scrape Single Page Applications (SPAs): SPAs often update their content dynamically without refreshing the page. JavaScript-powered tools can interact with SPAs and extract relevant data effectively.
Popular JavaScript Libraries and Frameworks
JavaScript offers powerful tools and libraries for scraping dynamic websites. Here are the most popular options:
1. Puppeteer: For Headless Browser Automation
Puppeteer is a high-level API for controlling headless Chrome or Chromium browsers. It allows you to simulate real browser behavior, making it perfect for scraping JavaScript-heavy websites.
- Key Features:
- Automates tasks like clicking, form submissions, and page navigation.
- Supports capturing screenshots, generating PDFs, and monitoring network activity.
- Handles pages that load content asynchronously using AJAX.
2. Cheerio: For HTML Parsing Similar to jQuery
Cheerio is a lightweight library that provides jQuery-like syntax for parsing static HTML. While it doesn’t execute JavaScript, it’s efficient for scraping static websites where content is available in the HTML structure.
- Key Features:
- Fast and simple DOM manipulation.
- Ideal for small-scale scraping of static content.
3. Node.js: For Scalable and Efficient Scraping Solutions
Node.js is a runtime environment that allows for asynchronous, non-blocking I/O operations. Combined with libraries like Axios (for HTTP requests) and Cheerio (for HTML parsing), Node.js is an excellent choice for building scalable web scrapers.
- Key Features:
- Handles multiple requests simultaneously, making it suitable for large-scale scraping.
- Can be integrated with Puppeteer for scraping JavaScript-heavy sites.
Comparison Between JavaScript and Python for Web Scraping
Both JavaScript and Python offer robust solutions for automated web scraping, but each has its strengths depending on the project’s requirements.
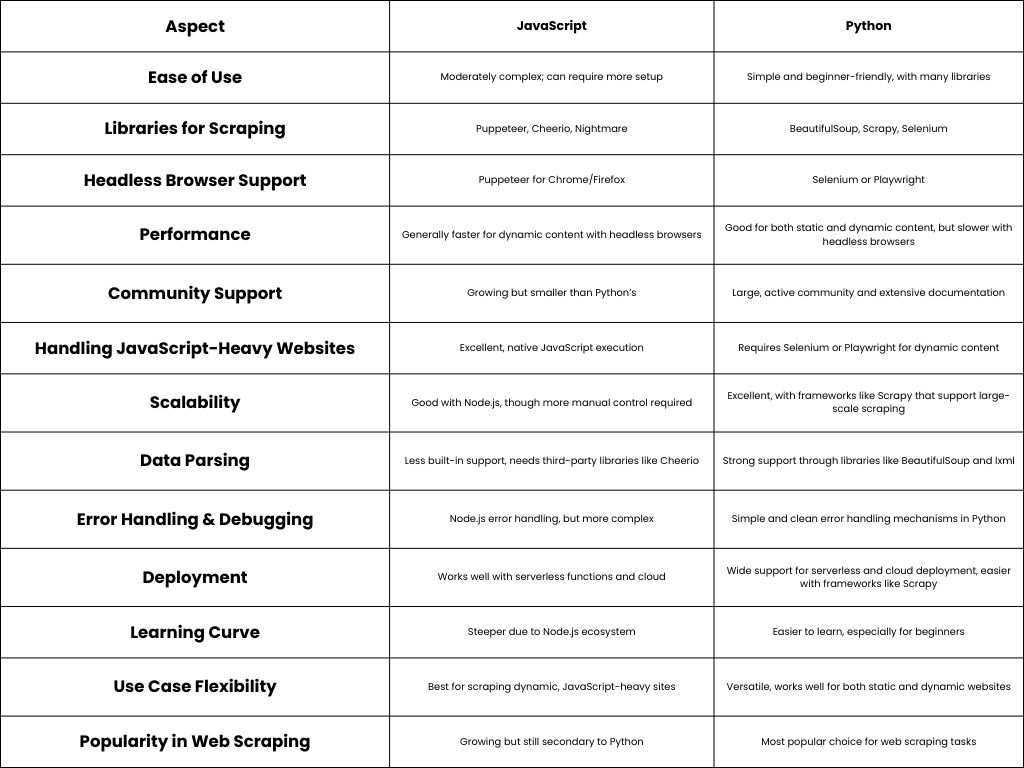
Other Web Scraping Languages
While Python and JavaScript are the most popular choices for web scraping, other programming languages also offer powerful tools and libraries for data extraction. Depending on your project’s requirements, you might find that these languages are a better fit for specific use cases.
1. Java: Java offers several robust libraries for web scraping, including Jsoup and HtmlUnit.
- Jsoup: Used for parsing HTML and manipulating web content, Jsoup is easy to use and excellent for extracting data from static websites.
- HtmlUnit: A headless browser that simulates real browser behavior, making it ideal for JavaScript-heavy sites.
2. R: For data scientists and researchers, R offers libraries like rvest and RSelenium for web scraping.
- rvest: Designed for scraping static web pages, it is commonly used for small-scale scraping projects in academic and research contexts.
- RSelenium: Provides browser automation capabilities similar to Selenium for scraping dynamic content.
3. C#: C# offers tools like HtmlAgilityPack and Selenium for C# for web scraping.
- HtmlAgilityPack: A powerful library for parsing HTML, best for static websites.
- Selenium for C#: Allows browser automation to handle dynamic content and complex interactions.
4. Go: Go has emerged as a popular choice for building high-performance, concurrent scraping solutions. Colly and Goquery are the most widely used libraries.
- Colly: A fast and efficient scraping framework for large-scale projects.
- Goquery: Offers a jQuery-like API for parsing HTML.
Web Scraping Techniques
Web scraping is a powerful tool for businesses looking to extract large volumes of data from websites. However, there are various techniques and methods involved depending on the complexity of the websites you’re targeting. From scraping static content to handling JavaScript-heavy sites, mastering the right methods is crucial for efficient and reliable data extraction.
In this section, we’ll explore a step-by-step guide to basic web scraping techniques, how to handle dynamic content and JavaScript-loaded websites, the use of advanced libraries like Selenium, and provide tips for bypassing anti-scraping mechanisms.
Step-by-Step Guide to Basic Web Scraping Techniques
Let’s start with the basic techniques that will help you get started with scraping. The following steps will guide you through setting up a basic scraper to extract data from a static website.
Step 1: Choose the Right Tool
There are many web scraping tools and libraries available. For static websites, Python libraries such as BeautifulSoup, Requests, and Cheerio (for JavaScript) are excellent starting points.
- BeautifulSoup: For parsing and extracting data from HTML or XML documents.
- Requests: For making HTTP requests to fetch the webpage content.
Step 2: Send a Request to the Website
The first step in web scraping is to fetch the HTML content of the page you want to scrape. This is done by sending an HTTP request to the server.
import requests
url = “https://example.com”
response = requests.get(url)
html_content = response.text
print(html_content)
Step 3: Parse the HTML
Once you have the HTML content, use a parser to extract the data. BeautifulSoup makes it easy to navigate through HTML tags and extract specific elements like titles, headers, or product information.
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, ‘html.parser’)
# Extract the title of the page
title = soup.title.text
print(title)
Step 4: Extract Specific Data
You can extract specific elements using CSS selectors or XPath. For example, if you want to scrape product prices or names:
# Extract all product names
products = soup.find_all(‘h2′, class_=’product-name’)
for product in products:
print(product.text)
Step 5: Store the Data
Once you have extracted the data, you can store it in a structured format like CSV, JSON, or directly in a database.
import csv
with open(‘products.csv’, ‘w’, newline=”) as file:
writer = csv.writer(file)
writer.writerow([‘Product Name’, ‘Price’])
for product in products:
name = product.text
price = product.find_next(‘span’, class_=’price’).text
writer.writerow([name, price])
Handling Dynamic Content and JavaScript-Loaded Websites
While scraping static websites is relatively simple, dynamic content—which is loaded by JavaScript after the initial page load—requires more advanced techniques. For these cases, you’ll need to use tools that can render JavaScript and interact with web pages in real time.
Step 1: Use Selenium for JavaScript-Heavy Websites
Selenium is a powerful tool that automates browser actions, allowing you to scrape content loaded by JavaScript. It’s especially useful for interacting with complex, dynamic sites.
- Installation: First, install Selenium and a WebDriver (like ChromeDriver) to simulate a browser.
pip install selenium
- Launching a Browser and Navigating to a Website:
from selenium import webdriver
# Set up the WebDriver
driver = webdriver.Chrome(executable_path=’/path/to/chromedriver’)
# Open the website
driver.get(‘https://example.com’)
# Extract the page title
print(driver.title)
# Close the browser
driver.quit()
Step 2: Wait for Dynamic Content to Load
Many dynamic websites load content asynchronously. Selenium allows you to wait until specific elements are loaded before extracting the data.
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Wait until the product list is loaded
product_list = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, ‘product-list’))
)
# Extract product names
products = driver.find_elements_by_class_name(‘product-name’)
for product in products:
print(product.text)
Step 3: Interacting with JavaScript Components
Selenium can also simulate interactions with the page, such as clicking buttons, scrolling, or filling forms, which are essential for scraping certain websites.
# Click a button to load more products
load_more_button = driver.find_element_by_id(‘load-more’)
load_more_button.click()
# Scrape additional products after they load
new_products = driver.find_elements_by_class_name(‘product-name’)
for product in new_products:
print(product.text)
Tips for Bypassing Anti-Scraping Mechanisms
Many websites implement anti-scraping measures to prevent automated bots from scraping their data. To avoid detection and continue scraping efficiently, here are some tips for bypassing these mechanisms:
1. Use Proxies and Rotate IP Addresses
Websites often block IP addresses that send too many requests. To avoid this, you can use proxy servers and rotate IPs to distribute your requests across different locations.
- Rotating Proxies: Tools like Scrapy and Selenium can be configured to send requests through different proxies, making it harder for the website to detect your scraper.
2. Implement Random Delays Between Requests
Sending too many requests in quick succession can trigger rate-limiting mechanisms. Introducing random delays between requests mimics human browsing behavior and reduces the likelihood of getting blocked.
3. Use User-Agent Rotation
Websites often detect scraping by analyzing the User-Agent header. By rotating your User-Agent strings, you can make your scraper appear as though requests are coming from different devices and browsers.
4. Handle CAPTCHAs
Some websites use CAPTCHAs to block bots. While challenging, CAPTCHAs can be bypassed using services like 2Captcha or Anti-Captcha, which solve them automatically.
Applications of Web Scraping
In today’s competitive and data-driven landscape, real-time access to actionable information is no longer a luxury – it’s a necessity. As businesses strive to stay ahead of the competition, web scraping has become an indispensable tool for gathering critical data and using it to power smarter business decisions. Whether it’s monitoring competitors, gathering market insights, or optimizing pricing strategies, web scraping offers a wide range of benefits tailored to the specific needs of your business.
Let’s dive into the top ways businesses are leveraging web scraping and how it can transform your business operations for better decision-making, efficiency, and profitability.
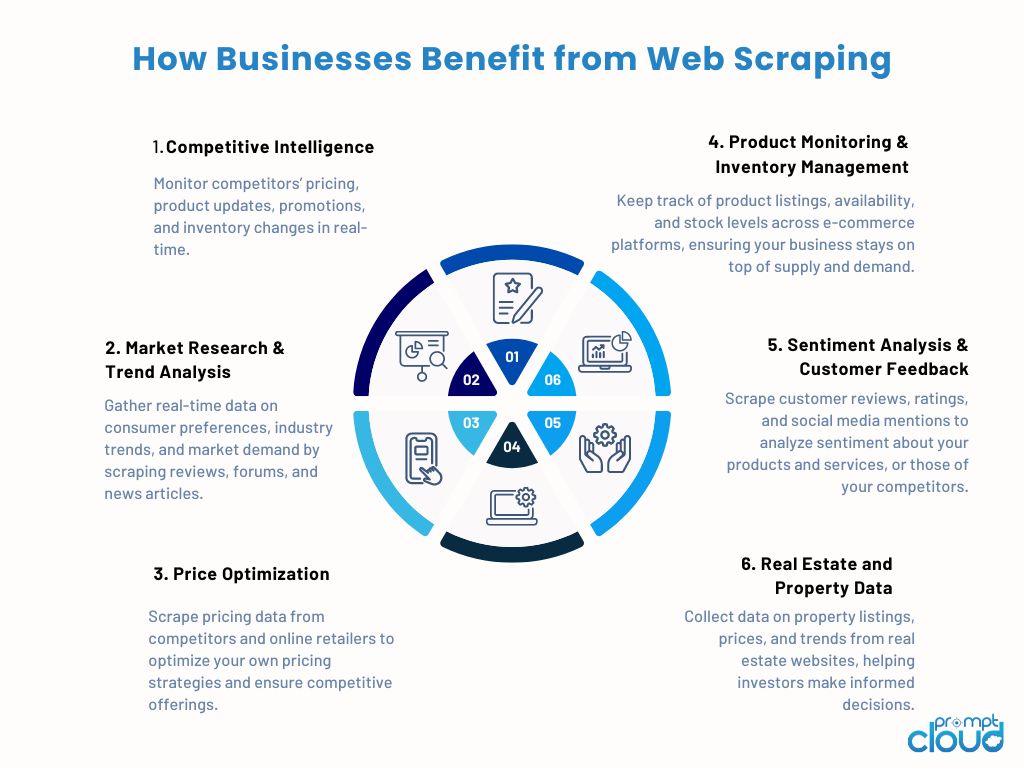
Let’s explore the key use cases of web scraping in different industries and how businesses are leveraging it to fuel growth, optimize decision-making, and unlock new opportunities. We will look into specific examples and discuss the challenges that businesses must navigate in each sector.
1. Scraping Ecommerce Websites:
In the highly competitive e-commerce industry, staying on top of pricing trends, product availability, and customer sentiment is crucial to maintaining market leadership. Web scraping allows businesses to track competitor pricing, monitor product listings, and analyze consumer feedback to make smarter pricing and inventory decisions.
With web scraping, you’re never in the dark about what your competitors are doing. Whether you’re tracking product launches or seasonal discounts, real-time competitor monitoring provides a powerful competitive edge, allowing you to proactively make informed decisions.
Key Use Cases:
- Price Monitoring: Pricing is one of the most critical aspects of maintaining profitability and market share. For e-commerce companies, monitoring price changes in real-time is essential to ensure they offer competitive prices while maintaining healthy margins. With web scraping, businesses can track pricing data across multiple platforms and react quickly to changes in competitor pricing.
Amazon sellers can use web scraping to monitor competitors’ pricing and product availability. By extracting daily price changes, you can adjust your prices accordingly to maintain a competitive edge and improve your rankings in search results.
When you monitor prices across multiple retailers in real-time, you’ll always have the information needed to stay competitive. Whether you need to react to competitor discounts or adjust prices for profitability, web scraping provides actionable data that keeps your business in control.
E-commerce platforms can scrape competitor websites to track real-time pricing data across various categories. This data helps businesses adjust their own prices dynamically to remain competitive, offer timely discounts, or match prices.
For example, an online electronics retailer might scrape prices from competitors like Amazon, Walmart, and Best Buy daily. By analyzing price fluctuations, the retailer can offer competitive pricing on top-selling products, leading to increased sales.
- Product Catalog Scraping: E-commerce sites often scrape large product catalogs from multiple suppliers or competitors to ensure that their own listings are up-to-date. This is particularly important for platforms with a large inventory.
For example, a marketplace like eBay can scrape competitor sites to update its product database, ensuring they offer a wide variety of products while automatically adjusting their stock listings to match market trends.
- Consumer Sentiment Analysis: Businesses can scrape product reviews and social media comments to gauge consumer opinions on certain products or brands, allowing for data-driven product development and customer engagement strategies.
For example, a fashion retailer can scrape reviews from platforms like Amazon and customer forums to understand which styles and brands are trending. By analyzing feedback, they can adjust their inventory and marketing campaigns accordingly.
Challenges in E-Commerce:
E-commerce platforms often implement anti-scraping measures, such as IP blocking and CAPTCHAs, requiring businesses to use proxy management and CAPTCHA-solving services for efficient and uninterrupted data extraction.
2. Real Estate:
The real estate industry thrives on data—whether it’s property listings, market trends, or price changes. Web scraping can give real estate businesses access to comprehensive and up-to-date property data, including listings, sales trends, and neighborhood insights. This data helps investors, agents, and brokers make more informed decisions about where and when to buy or sell.
An investor looking to purchase properties in a competitive market can use web scraping to monitor real estate listing websites for price drops, new listings, or property features. By continuously scraping real estate portals, the investor gains real-time insights into which properties are undervalued or in high demand, allowing them to act quickly on promising opportunities.
In the real estate market, time is of the essence. With web scraping, investors and real estate professionals can make data-driven decisions based on the latest market information, giving them the ability to act faster than competitors and maximize their ROI.
Key Use Cases:
- Property Listings and Price Monitoring: Real estate firms can scrape multiple property listing sites (such as Zillow, Realtor, or Redfin) to track changes in property prices, availability, and new listings. This allows businesses to have a comprehensive view of market trends and make better investment decisions.
For example, real estate investment firms might scrape property prices from local and national real estate sites to analyze price fluctuations and spot undervalued properties in hot markets.
- Market Trends and Forecasting: By scraping historical data, including housing prices, rental rates, and demographic information, real estate businesses can forecast trends and identify emerging neighborhoods for future development.
For example, a developer can scrape neighborhood-level data on home prices, school ratings, and amenities to determine the best areas for launching new residential projects.
- Investment Opportunities: Investors use scraping to track foreclosed homes, auction listings, or other real estate investment opportunities. This data provides timely insights into potential deals and undervalued properties.
For example, a property investor might scrape public records and foreclosure listings to identify properties at risk of foreclosure, enabling them to act on potential investment opportunities before competitors.
Challenges in Real Estate:
Data availability and accuracy are significant challenges in real estate. Scrapers must ensure that the data is cleaned and structured properly, especially when dealing with diverse sources with inconsistent formats.
3. Food Delivery and Grocery Services:
The rise of online food delivery and grocery services has made scraping an essential tool for businesses looking to remain competitive in this rapidly evolving industry. From tracking competitors’ menus and prices to monitoring customer reviews, web scraping enables food delivery services to optimize their offerings and improve customer satisfaction.
Key Use Cases:
- Menu Scraping and Price Tracking: Delivery platforms can scrape restaurant menus and prices from competitors to stay competitive, adjusting their fees and promotions accordingly.
A food delivery service might scrape the menus of local restaurants listed on UberEats and DoorDash to ensure their own listings are up-to-date and competitively priced.
- Competitor Monitoring: Scraping competitor websites for reviews, delivery times, and promotions helps businesses understand how they rank in the market and adjust their strategy to gain more market share.
A grocery delivery service might scrape customer reviews from competitors to identify pain points related to delivery times or product availability, enabling them to address these issues in their own service.
- Market Research and Demand Forecasting: By scraping data from grocery and restaurant platforms, businesses can predict trends in food preferences, adjust their inventory, and improve their supply chain management.
In the age of customer-centric marketing, understanding consumer preferences and emerging trends is more important than ever. Web scraping enables businesses to monitor reviews, analyze social media conversations, and track trends in real-time, providing insights into shifts in demand and customer preferences. Using real-time market data, businesses can react to trends before their competitors even notice them. With continuous market intelligence, web scraping allows businesses to pivot quickly, ensuring they stay aligned with consumer needs and preferences.
A grocery delivery company might scrape customer orders to analyze which products are in demand seasonally and adjust stock levels accordingly.
Challenges in Food Delivery and Grocery Services:
One of the biggest challenges is keeping data up-to-date and accurate, especially as restaurant menus, prices, and availability change frequently. Regular, real-time scraping is necessary to ensure data accuracy.
Challenges in Web Scraping
While web scraping offers tremendous value by providing businesses with access to vast amounts of data, it comes with several technical, ethical, and legal challenges. Understanding these challenges and planning how to navigate them is crucial for any successful scraping initiative. In this section, we will explore some of the key scraping challenges businesses face and offer strategies to overcome them while remaining compliant with legal and ethical standards.
1. Handling Dynamic and JavaScript-Heavy Websites
Many modern websites are built using JavaScript frameworks such as React, Vue, and Angular, where content is rendered dynamically after the initial page load. This presents a significant challenge for basic scrapers, which can only extract static HTML.
Challenges:
- Traditional HTML parsing tools like BeautifulSoup are ineffective for scraping dynamic content.
- JavaScript-heavy sites rely on AJAX requests or require user interactions (like scrolling or clicking) to load all the data.
Solutions:
- Selenium and Puppeteer are widely used tools to handle dynamic websites. These tools automate browsers, allowing scrapers to wait for JavaScript to load and even interact with elements like buttons or drop-down menus.
- Headless Browsers: Using headless browsers like Puppeteer can speed up scraping by eliminating the graphical interface and automating content rendering.
2. IP Blocking and Rate Limiting
Websites often detect scrapers by monitoring the frequency and volume of requests coming from the same IP address. If a scraper sends too many requests in a short period, the website may block its IP, making further data extraction impossible.
Challenges:
- Websites implement rate-limiting and block IP addresses to prevent overload and protect their content.
- Bot detection systems identify scraping patterns, which may result in the website blocking the scraper.
Solutions:
- Proxy Rotation: Implementing rotating proxies allows scrapers to send requests from different IP addresses, reducing the likelihood of detection. Proxy Tools like Scrapy or services such as Bright Data can help rotate proxies effectively.
- Request Throttling: Introduce random delays between requests to mimic human browsing behavior, reducing the chances of being flagged by anti-bot systems.
- User-Agent Spoofing: Change the User-Agent header in requests to avoid detection. By rotating User-Agent strings, the scraper can appear to be using different browsers or devices.
3. CAPTCHA and Anti-Bot Mechanisms
To prevent automated scraping, many websites implement CAPTCHAs and other anti-bot mechanisms that require users to perform actions that are difficult for bots to replicate (e.g., selecting images, solving puzzles).
Challenges:
- CAPTCHAs are designed to distinguish between bots and human users, making it hard for automated systems to bypass CAPTCHAs.
- Websites may use advanced bot detection mechanisms that monitor suspicious activities such as excessive requests or unusual browsing patterns.
Solutions:
- CAPTCHA-Solving Services: Third-party services like 2Captcha or Anti-Captcha can automatically solve CAPTCHAs and integrate with your scraper.
- Headless Browsers: Tools like Selenium and Puppeteer can simulate human behavior, including clicking and navigating through CAPTCHA prompts, although this is not always foolproof.
- Human-in-the-Loop Systems: For more advanced CAPTCHAs, businesses can introduce human-in-the-loop systems, where difficult CAPTCHAs are solved manually to allow the scraping process to continue.
4. Legal and Ethical Considerations
One of the most significant challenges in web scraping is navigating the legal and ethical implications. Scraping data without proper permissions can lead to violations of terms of service, copyright laws, and data privacy regulations such as GDPR and CCPA.
Challenges:
- Legality: Not all websites allow their data to be scraped, and violating a website’s terms of service can result in legal action.
- Data Privacy: Scraping personal information without consent can violate privacy laws such as the General Data Protection Regulation (GDPR) in Europe or the California Consumer Privacy Act (CCPA).
Solutions:
- Scrape Public Data Only: Always ensure that the data you are scraping is publicly available and does not violate any privacy agreements or legal protections.
- Check Website Terms of Service: Review the website’s robots.txt file and terms of service to ensure that scraping is permitted. Many websites explicitly prohibit scraping in their terms, while others restrict it to certain areas.
- Data Compliance: Make sure your scraping activities comply with relevant data protection laws. If scraping data that includes personal information, ensure the necessary consents are obtained.
5. Data Quality and Cleaning
Even if a scraper successfully extracts large volumes of data, there is a significant challenge in ensuring that the data is accurate, complete, and clean. Scraped data often comes in unstructured formats, requiring extensive cleaning and validation before it can be used.
Challenges:
- Unstructured Data: Data from different websites can come in various formats, requiring significant cleaning and formatting efforts.
- Inconsistent or Missing Data: Scraping errors, dynamic website content, or incomplete pages can result in missing or inconsistent data.
Solutions:
- Automated Data Cleaning Pipelines: Use data cleaning tools or ETL pipelines (Extract, Transform, Load) to process and format scraped data. This can help normalize different data formats and remove unnecessary noise.
- Regular Validation: Regularly validate scraped data by cross-referencing with trusted sources to ensure accuracy and completeness.
6. Scalability and Performance
As businesses grow and the volume of data increases, the need for scalable and high-performance web scraping solutions becomes paramount. Scrapers built for small projects may not be able to handle large-scale scraping tasks efficiently.
Challenges:
- Large-Scale Scraping: Scraping large datasets or multiple websites simultaneously can overwhelm infrastructure, causing slowdowns or crashes.
- Performance: Without optimization, large-scale scrapers can become slow and resource-intensive, affecting the overall efficiency of the process.
Solutions:
- Cloud-Based Best Scraping Services: Using cloud-based scraping services or platforms like PromptCloud can scale your data extraction efforts without the need for in-house infrastructure.
- Asynchronous Scraping: Implementing asynchronous scraping using libraries like Scrapy (Python) or Node.js can increase performance by handling multiple requests simultaneously.
While web scraping offers invaluable insights and competitive advantages across industries, it comes with its own set of challenges. From handling dynamic content and overcoming anti-scraping mechanisms to navigating legal and ethical issues, businesses must implement robust strategies to ensure their scraping efforts are effective, compliant, and scalable.
At PromptCloud, we specialize in fully managed web scraping solutions that handle the complexities of dynamic websites, IP rotation, CAPTCHA-solving, and data cleaning—allowing you to focus on leveraging actionable insights without the headaches of manual data extraction. Contact us today to learn how we can help your business scrape smarter and scale your data operations with ease.
Web Scraping Best Practices
Web scraping can be a highly effective tool for businesses looking to gather valuable insights from online data. However, to ensure the success and longevity of your scraping projects, it’s essential to follow best practices that prioritize efficiency, compliance, and ethical use. Ignoring these can result in legal repercussions, IP blocks, or poor-quality data. Below, we outline key best practices for conducting web scraping responsibly and effectively.
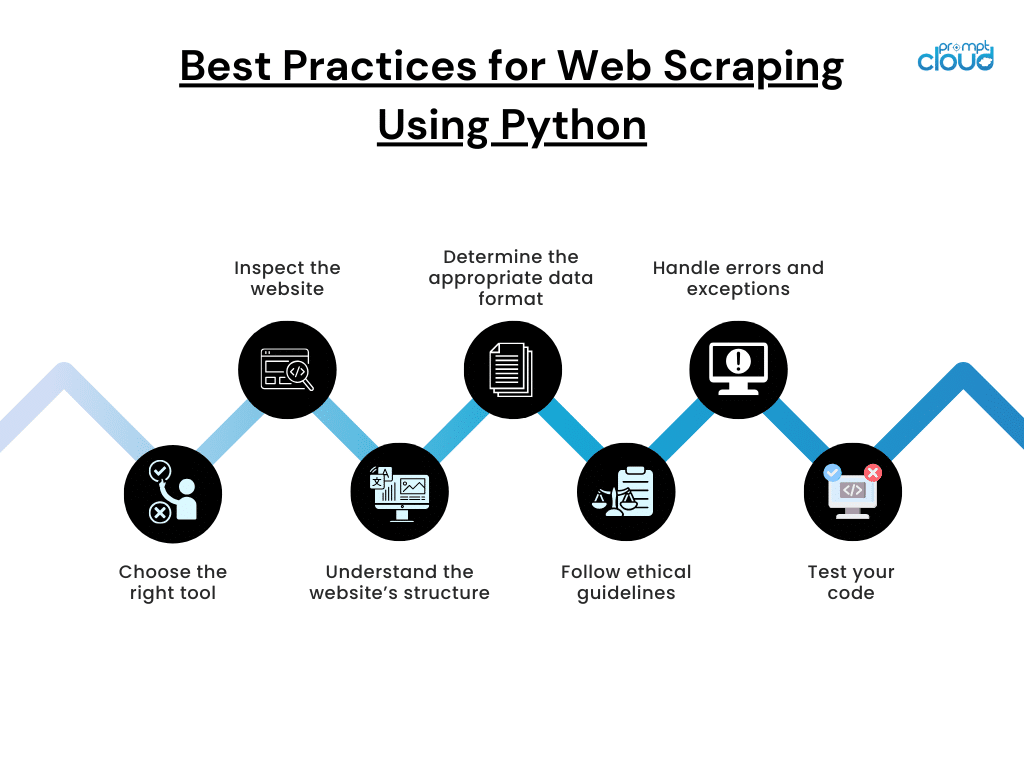
1. Respect Website Terms of Service and robots.txt
Every website has its own terms of service (ToS) and robots.txt file, which specifies how the site’s content should be accessed. Before scraping a website, it’s critical to review and understand these guidelines.
Best Practices:
- Check robots.txt: Websites often list their scraping rules in their robots.txt file. This file tells web crawlers which sections of the site they are allowed or prohibited from scraping.
Example: Before scraping a news website for articles, check the robots.txt file to see if there are any restrictions on crawling or scraping specific sections of the site. - Follow Terms of Service: Always read the website’s ToS to confirm whether scraping is allowed. Scraping content that violates the ToS can lead to legal consequences.
2. Implement IP Rotation and Proxy Usage
Many websites use anti-scraping mechanisms like IP blocking to prevent bots from overloading their servers with requests. To avoid detection and ensure continuous data collection, it’s essential to rotate IP addresses and use proxies.
Best Practices:
- Use Rotating Proxies: Implement proxies that automatically rotate IP addresses, making it harder for websites to detect repetitive requests coming from the same source. This ensures the scraper can bypass rate-limiting and geo-blocking.
- Throttle Requests: Introduce random delays between requests to mimic human browsing behavior. This reduces the chances of being flagged by websites as a bot.
3. Avoid Overloading the Target Website
Scraping too aggressively can strain the target website’s servers and result in your scraper getting blocked. To avoid this, it’s important to balance your scraping activity and respect the website’s infrastructure.
Best Practices:
- Respect Rate Limits: If a website has rate-limiting policies in place (maximum requests per second), respect those limits. Overloading the server with too many requests in a short period can result in IP bans or blocking your scraper entirely.
- Monitor Server Responses: Watch for HTTP status codes such as 429 (Too Many Requests). If you encounter this code, slow down your scraper and reduce the request frequency.
4. Handle Dynamic Content with the Right Tools
With the widespread use of JavaScript frameworks like React and Angular, many websites today load content dynamically after the initial page load. Traditional scrapers struggle with such websites, so it’s important to use the right tools.
Best Practices:
- Use Headless Browsers: Tools like Puppeteer or Selenium can handle dynamic content by simulating real user interactions with the website. They allow your scraper to render JavaScript-heavy content and navigate through pages.
- Wait for Content to Load: For websites that load content asynchronously, make sure your scraper waits for the content to load before extracting the data. Implement wait times or explicit waits to capture the correct information.
5. Clean and Structure the Data
Raw scraped data is often messy and unstructured, requiring thorough data cleaning before it can be used effectively. It’s essential to have processes in place to clean, structure, and validate the data.
Best Practices:
- Normalize Data Formats: Scraped data from different sources may come in various formats. Implement processes to normalize and structure the data consistently (e.g., converting date formats, removing HTML tags, standardizing currencies).
- Validate Data: Always check for missing or inconsistent data and validate it by cross-referencing multiple sources. Poor-quality data can result in faulty analysis and decisions.
6. Stay Compliant with Data Privacy Laws
With increasing emphasis on data privacy regulations such as GDPR (General Data Protection Regulation) in Europe and CCPA (California Consumer Privacy Act) in the US, it’s vital that your scraping activities adhere to the applicable laws.
Best Practices:
- Avoid Scraping Personal Data: Do not scrape sensitive or personal data, such as user profiles or email addresses, without explicit consent. Violating data privacy laws can result in hefty fines and legal actions.
- Obtain Consent When Necessary: If your scraping activity involves personal data, ensure you have obtained proper consent in line with privacy regulations.
- Be Transparent: Clearly communicate your data usage practices if you are scraping user-generated content and ensure that users are aware of how their public data is being utilized.
7. Monitor and Maintain Your Scraping Scripts
Websites frequently update their structures, meaning that scraping scripts can quickly become outdated or break. Regular monitoring and updates are necessary to keep your scrapers running smoothly.
Best Practices:
- Automate Monitoring: Implement monitoring systems that detect changes in the website’s HTML structure or layout. Automated alerts can notify you when your scraper encounters an error or when the website’s structure changes.
- Regularly Update Scraping Scripts: Review and update your scraping scripts regularly to handle changes in website design, page structure, or newly added anti-scraping mechanisms.
Web scraping offers immense value, but only if done ethically, legally, and with long-term efficiency in mind. By following best practices like respecting website rules, implementing IP rotation, using advanced tools for dynamic content, and ensuring data compliance, businesses can extract valuable insights without risking legal or technical pitfalls.
At PromptCloud, we specialize in fully managed, compliant web scraping solutions that take care of these complexities. From real-time data extraction to advanced dynamic scraping, we ensure your business gets the insights it needs, while staying compliant with the latest regulations.
The Future of Web Scraping
The future of web scraping is poised to evolve rapidly as technology advances and regulations around data privacy tighten. As businesses become increasingly data-driven, web scraping will continue to play a critical role in providing real-time insights for market research, competitive analysis, and business intelligence. However, with the rise of AI, machine learning, and stricter compliance laws, the future of scraping will bring both opportunities and challenges.
In this section, we’ll explore the key trends shaping the future of web scraping, how AI-powered tools are transforming the landscape, and what businesses need to consider in an era of growing data privacy concerns.
1. AI Web Scraping: Smarter, Faster, and More Efficient
Artificial intelligence (AI) and machine learning (ML) are set to revolutionize scraping by making it more automated, scalable, and intelligent. Traditional scrapers require precise instructions to extract specific data, but AI-powered web scraping tools are learning to understand content contextually, making data extraction more accurate and flexible.
Key Developments:
- Natural Language Processing (NLP): NLP enables scrapers to interpret and extract unstructured text from websites, such as user-generated content, reviews, or news articles, with greater accuracy. AI models can learn to differentiate between important and irrelevant data without manual intervention.
- Adaptive Learning: AI scrapers can adapt to changes in website structure automatically, reducing the need for constant manual updates. When websites alter their layout or content format, machine learning algorithms can detect these changes and adjust scraping strategies in real-time.
2. Automation and Scalability: Cloud-Based Scraping at Scale
As businesses demand more data from diverse sources, the future of scraping will focus heavily on automation and scalability. Cloud-based solutions and web scraping as a service (SaaS) platforms will be essential for companies that need to collect and process large volumes of data regularly.
Key Developments:
- Cloud Infrastructure: Cloud-based web scraping allows businesses to scale their data collection efforts without worrying about infrastructure limitations. Scraping jobs can run across multiple servers, improving speed and efficiency while reducing downtime.
- Task Automation: The ability to automate repetitive scraping tasks, schedule crawlers, and integrate data directly into data pipelines or CRMs will become the standard for businesses looking to streamline their operations.
3. Ethical and Legal Challenges: Navigating Data Privacy Regulations
As data privacy laws like GDPR (General Data Protection Regulation) and CCPA (California Consumer Privacy Act) become stricter, businesses will face increasing challenges to ensure their web scraping activities are compliant with evolving regulations. Ethical considerations around data ownership and user privacy will drive the future of web scraping, leading to more transparent and responsible practices.
Key Considerations:
- Data Ownership and Consent: The debate around who owns publicly available data is intensifying. As more websites seek to protect their content, scraping will need to evolve to ensure that it respects intellectual property and user consent.
- Global Data Regulations: With the global patchwork of data privacy laws, businesses operating in multiple regions will need to stay informed about regulations that impact how and where they can scrape data. Compliance tools will be critical in ensuring that data collection methods adhere to international laws.
4. The Rise of Anti-Scraping Technologies
As web scraping becomes more widespread, websites are increasingly deploying anti-scraping technologies to protect their data. These include CAPTCHAs, IP blocking, rate-limiting, and honeypots designed to catch scrapers. In the future, businesses will need to employ advanced techniques to bypass these defenses without violating ethical standards.
Key Developments:
- Enhanced Bot Detection Systems: Websites are using more advanced tools to differentiate between bots and humans. These include monitoring user behavior patterns, implementing device fingerprinting, and tracking mouse movements or scrolling activities.
- Improved Bypassing Techniques: Future web scrapers will need to incorporate AI-based human mimicry and more sophisticated IP rotation techniques to remain undetected. Additionally, scrapers will likely rely on AI-driven CAPTCHA-solving technologies or partnerships with human-in-the-loop CAPTCHA-solving services to bypass complex CAPTCHAs.
5. Data Integration and Actionable Insights
As the volume of data collected through web scraping continues to grow, businesses will increasingly focus on how to integrate and analyze this data to extract actionable insights. In the future, scraping tools will likely integrate more tightly with machine learning models, business intelligence platforms, and data analytics tools, making data extraction part of a larger, automated decision-making process.
Key Developments:
- AI-Driven Data Analysis: Scraped data will be fed into AI systems for real-time analysis, enabling businesses to make quicker decisions based on the latest market trends or competitor activities. The future of web scraping will move beyond data collection into predictive analytics and trend forecasting.
- Seamless Data Integration: Future scraping solutions will be designed to seamlessly integrate with enterprise systems like CRM, ERP, or business intelligence platforms, streamlining data pipelines and eliminating manual data processing.
6. Ethical AI in Web Scraping
The rise of AI-driven scraping will also bring about ethical challenges. As machine learning models become more capable of mimicking human interactions with websites, businesses will need to ensure that they are not overstepping ethical boundaries, such as scraping sensitive personal information or breaching user privacy.
Key Considerations:
- Transparency and User Consent: AI-driven scrapers will need to incorporate mechanisms for obtaining user consent when scraping sensitive data, ensuring that companies remain transparent about how the data is being used.
- AI Accountability: As AI-driven scraping models become more autonomous, there will be growing scrutiny over the ethical use of these tools. Businesses will need to ensure accountability and maintain human oversight to avoid misusing the technology.
The future of web scraping is bright, but businesses must navigate an increasingly complex landscape of regulations, anti-scraping technologies, and ethical concerns. The integration of AI, automation, and cloud-based technologies will transform how data is collected, analyzed, and used for decision-making, providing businesses with unprecedented insights at scale.
At PromptCloud, we are at the forefront of this evolution, offering compliant, scalable, and AI-powered web scraping solutions that help businesses unlock actionable insights while staying ahead of regulatory challenges. As web scraping continues to evolve, we are committed to ensuring that your business can harness the power of data in an ethical, transparent, and efficient way.
Choosing the Right Web Scraping as a Service (SaaS)
As businesses become more data-driven, web scraping as a service (SaaS) is gaining popularity. Instead of managing the complexities of setting up and maintaining web scrapers in-house, many companies are opting to outsource their scraping needs to specialized service providers. These providers offer scalable, fully managed solutions that help businesses collect, clean, and structure data from multiple sources, while ensuring compliance and ethical standards.
In this section, we’ll discuss what web scraping as a service entails, provide an overview of leading companies in the space, and help you navigate the factors to consider when choosing the right provider. We’ll also weigh the pros and cons of outsourcing versus handling scraping in-house and offer examples of custom solutions that meet specific business needs.
Introduction to Web Scraping Services or Web Scraping as a Service
Web Scraping as a Service (SaaS) refers to outsourcing the process of data extraction from websites to a specialized provider. Instead of building and maintaining your own scraping infrastructure, you can leverage a third-party service to handle everything—from setting up web crawlers to cleaning and delivering the data in a structured format.
Key Features of Web Scraping as a Service:
- Fully Managed Solutions: The service provider takes care of the entire process, from building the scrapers to handling maintenance and updates.
- Scalability: SaaS providers offer scalable solutions that can grow with your business, enabling you to scrape more data as your needs expand.
- Compliance: Best web scraping services ensure that the data collection process adheres to legal and ethical guidelines, protecting you from potential legal issues.
- Custom Data Solutions: Many providers offer tailored solutions based on specific business requirements, whether it’s competitor pricing analysis, real estate listings, or lead generation.
Overview of Companies Providing Best Web Scraping Services
Several companies specialize in offering web scraping services India, each catering to different use cases, industries, and scale.
Here’s a brief overview of some leading web scraping service providers:
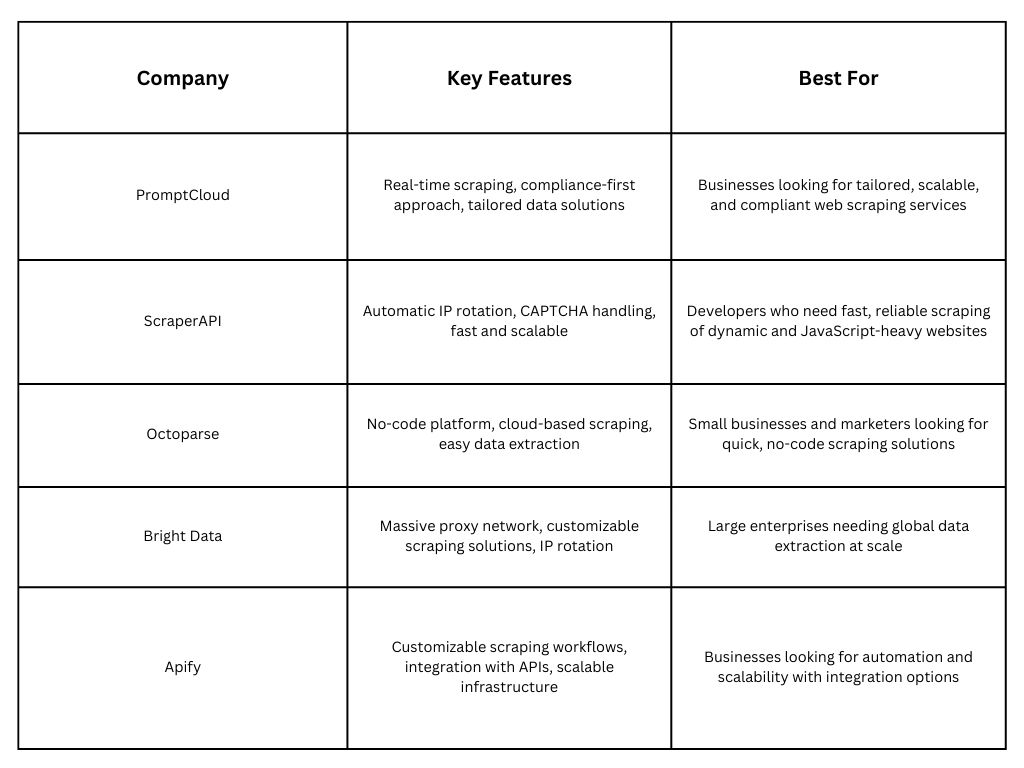
1. PromptCloud
PromptCloud offers a fully managed web scraping solution that caters to various industries such as e-commerce, real estate, financial services, and market research. They specialize in custom data extraction, ensuring data is delivered in any format required by the business.
- Key Features: Real-time scraping, compliance-first approach, tailored data solutions.
- Best for: Businesses looking for tailored, scalable, and compliant web scraping services.
2. ScraperAPI
ScraperAPI simplifies the process of scraping by handling IP rotation, CAPTCHAs, and browser rendering. It’s designed to make scraping easy and efficient, even for complex dynamic websites.
- Key Features: Automatic IP rotation, CAPTCHA handling, fast and scalable.
- Best for: Developers who need fast, reliable scraping of dynamic and JavaScript-heavy websites.
3. Octoparse
Octoparse provides a no-code solution for web scraping, allowing non-technical users to easily set up web crawlers through a user-friendly interface. It is best for small to mid-sized businesses that want to quickly start scraping without coding knowledge.
- Key Features: No-code platform, cloud-based scraping, easy data extraction.
- Best for: Small businesses and marketers looking for quick, no-code scraping solutions.
4. Bright Data (Formerly Luminati)
Bright Data provides advanced web scraping services India with a focus on data collection at scale. It offers tools for proxy management, which is ideal for large-scale scraping operations that require IP rotation and geo-targeted scraping.
- Key Features: Massive proxy network, customizable scraping solutions, and IP rotation.
- Best for: Large enterprises needing global data extraction at scale.
5. Apify
Apify is a cloud-based platform offering web scraping, automation, and data extraction tools. It provides customizable scraping scripts and pre-built solutions, catering to both developers and non-technical users.
- Key Features: Customizable scraping workflows, integration with APIs, scalable infrastructure.
- Best for: Businesses looking for automation and scalability with integration options.
Factors to Consider When Choosing a Web Scraping Service Provider
Choosing the right web scraping service provider can significantly impact the success of your data extraction efforts. Here are key factors to consider when evaluating different providers:
1. Data Customization and Flexibility
Every business has unique data needs. Make sure the provider can customize the data extraction process to fit your specific requirements. Whether you need data delivered in JSON, CSV, API, or database format, the provider should be flexible enough to deliver clean, structured data.
- Question to Ask: Can the service provider tailor the scraping to extract exactly the data I need in my desired format?
2. Scalability
If your business grows, your data scraping needs will expand too. Ensure the provider can scale with your data requirements, whether it’s extracting data from hundreds or thousands of web pages daily.
- Question to Ask: How well does the service scale when I need to scrape large volumes of data or from multiple websites?
3. Legal Compliance
Web scraping operates in a complex legal landscape, especially with regulations like GDPR and CCPA. Ensure the provider has a compliance-first approach, ensuring that your data scraping activities are fully legal and ethical.
- Question to Ask: How does the service ensure compliance with data privacy laws and website terms of service?
4. Real-Time Data Extraction
Some businesses require real-time data to stay competitive, particularly in industries like e-commerce or financial services. Make sure the service can handle real-time scraping for immediate insights.
- Question to Ask: Can the provider deliver real-time data feeds for my business needs?
5. Customer Support and Service Level Agreement (SLA)
The success of your scraping efforts can depend on the quality of customer support and how quickly the provider resolves issues. Look for a provider with reliable support and a clear SLA that outlines uptime, response time, and service guarantees.
- Question to Ask: What kind of customer support is provided, and are there clear SLAs to ensure reliable service?
Pros and Cons of Outsourcing Web Scraping vs. Doing It In-House

Outsourcing Web Scraping:
Pros:
- No Technical Overhead: You don’t need to invest in infrastructure, maintenance, or technical expertise.
- Scalability: Managed services can handle large-scale data extraction without requiring additional resources on your end.
- Compliance: Outsourcing to a provider that specializes in web scraping ensures that legal and ethical standards are met.
- Time Efficiency: The entire process is handled by the provider, allowing your team to focus on core business activities.
Cons:
- Higher Costs: Outsourcing can be more expensive compared to building an in-house scraper, especially if you have long-term or large-scale scraping needs.
- Less Control: You have less control over the process, which can be a downside if you need frequent adjustments or tweaks to the scraping process.
In-House Web Scraping:
Pros:
- Full Control: You have complete control over the scraping process, allowing for customizations and on-the-fly adjustments.
- Cost-Effective (in the long run): For businesses with the technical expertise, building an in-house scraper can be more cost-effective over time.
- Immediate Adjustments: If website structures change or new requirements arise, you can immediately adapt the scraper.
Cons:
- High Technical Overhead: Building and maintaining scrapers requires significant technical resources and expertise.
- Scalability Issues: Scaling an in-house scraper can be challenging without the right infrastructure and expertise.
- Maintenance Costs: Websites frequently change, and you will need a dedicated team to maintain and update your scrapers regularly.
Choosing the right web scraping service provider is crucial for businesses that rely on timely, accurate, and compliant data extraction. Whether you’re looking to track competitor prices, gather real-time market insights, or automate lead generation, selecting the right provider will determine the success of your data initiatives.
At PromptCloud, we offer fully managed, customizable web and data scraping solutions designed to meet the specific needs of your business. With our scalable infrastructure, compliance-first approach, and real-time data capabilities, we ensure your business gets the data it needs—ethically, efficiently, and on time.
Conclusion:
Web scraping is more than just a tool—it’s a competitive advantage that enables businesses to access real-time data, drive insights, and make strategic decisions faster. Whether you’re monitoring competitor prices, analyzing market trends, or automating lead generation, choosing the right approach to scraping is critical to staying ahead.
Outsourcing to a trusted web scraping companies like PromptCloud eliminates the hassle of building and maintaining scraping infrastructure in-house, allowing you to focus on what really matters—turning data into growth. With tailored solutions designed around your specific needs, scalable infrastructure, and a commitment to compliance, PromptCloud ensures you get the data you need without the headaches.
Ready to take your business intelligence to the next level? Get in touch with us today and discover how PromptCloud’s custom web scraping services USA can unlock new opportunities, boost efficiency, and keep your business ahead in the ever-evolving digital landscape. Let us handle the complexity, so you can focus on driving results. Request a demo and start harnessing the power of data to propel your business forward.















