




As digital landscapes evolve, static websites are being increasingly replaced by dynamic ones that offer a more interactive and personalized user experience. However, this shift presents a significant challenge: traditional web scraping methods often fall short when it comes to web scraping dynamic content these modern websites produce.
Dynamic websites, powered by technologies such as JavaScript and AJAX, continuously update their content based on user interactions, making it imperative for businesses to adopt advanced scraping techniques to access and leverage this data.
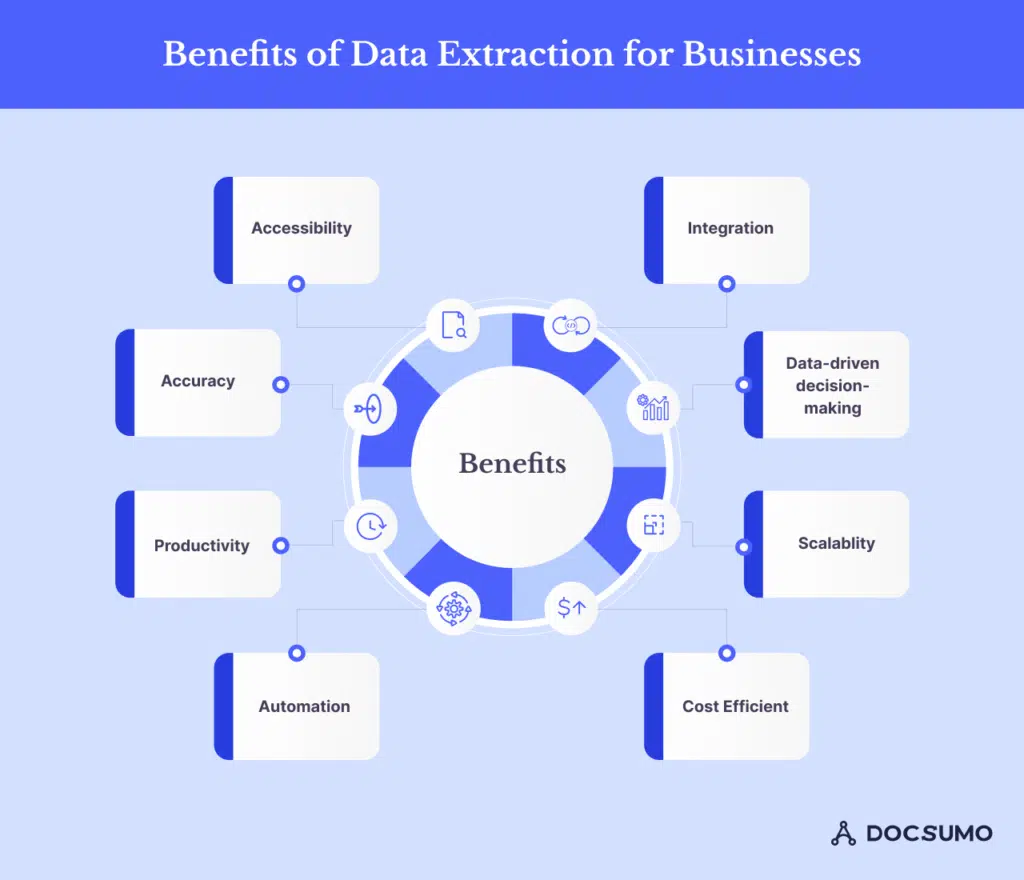
Source: docsumo
Automation of Data Extraction – Why is it Imperative
In the rapidly evolving business landscape, the automation of data extraction is no longer a luxury, it’s a necessity. As companies strive to remain competitive and agile, the ability to efficiently gather, process, and analyze vast amounts of data in real time has become a critical factor for success.
Manual data extraction and web scraping dynamic content is time-consuming and prone to errors. Automation streamlines this process, significantly reducing the time and resources required to gather data. Also, having access to real-time data is crucial. Automated data extraction provides up-to-the-minute insights, enabling businesses to make informed decisions quickly. This agility is essential for responding to market trends, customer demands, and competitive actions in a timely manner.
As businesses grow, the volume of data they need to manage and analyze increases exponentially. Automated data extraction systems can easily scale to handle larger datasets, ensuring that businesses can continue to derive valuable insights without being overwhelmed by data volume. While the initial investment in automation technology can be significant, the long-term cost savings are substantial. Automation reduces labor costs associated with manual data entry and minimizes the risk of costly errors. Over time, businesses can achieve a higher return on investment through increased efficiency and reduced operational costs.
Advanced Scraping Techniques

For businesses, data is not just an asset; it is the foundation for strategic decision-making, market analysis, and competitive intelligence. Dynamic websites, with their real-time updates and user-specific content, host a treasure trove of information that can inform everything from product development to marketing strategies. However, the dynamic nature of these websites requires a more nuanced approach to data extraction.
Headless Browsers
Headless browsers, such as Puppeteer and Selenium, are essential for scraping dynamic websites. These tools simulate real user interactions, allowing you to navigate through pages, click buttons, and interact with JavaScript elements as a human would. This ensures all dynamically loaded content is captured accurately, providing a comprehensive data set for analysis.
JavaScript Execution
Dynamic websites rely heavily on JavaScript to render content. Executing JavaScript within your scraping scripts, using tools like Puppeteer and Playwright, allows you to extract the content generated by these scripts. This technique is particularly effective for handling elements that load content asynchronously, ensuring no data is missed.
API Scraping
Many dynamic websites use APIs to fetch data. By intercepting and analyzing network requests, you can identify these APIs and extract data directly from them. This method is often more efficient and reliable than scraping rendered HTML, as it reduces the need to handle complex DOM structures and provides cleaner data.
Handling AJAX Requests
AJAX (Asynchronous JavaScript and XML) requests are a common method for dynamically updating content. To scrape data from AJAX-driven websites, monitor and capture these requests using tools like Fiddler or Browser Developer Tools. Replicating these requests in your scraping scripts ensures you capture the dynamically loaded data accurately.
Managing Authentication and Sessions
Dynamic websites often require user authentication and session management. Handling login processes and maintaining sessions programmatically, through automated form filling, cookie management, and session tokens, ensures continuous access to the data. This is crucial for scraping personalized or restricted content.
Overcoming Anti-Scraping Measures
Many dynamic websites implement anti-scraping measures, such as CAPTCHAs, IP blocking, and rate limiting. Overcoming these challenges involves using CAPTCHA-solving services, rotating IP addresses, and implementing rate-limiting strategies in your scraping scripts. Mimicking human behavior by adding random delays and using realistic user agents can also help avoid detection.
Dynamic websites often employ these techniques to enhance user experience by seamlessly loading additional content. However, these features can pose significant challenges for data extraction.
Techniques for Handling Pagination
Static Pagination Handling: Static pagination involves sequentially navigating through pages by clicking on “Next” or specific page numbers. Automated scripts can be programmed to detect these elements and iterate through pages until the end of the dataset is reached.
Dynamic Pagination: For websites using dynamic pagination (such as AJAX), scripts need to detect and execute the AJAX calls that load new pages. By capturing these network requests, businesses can automate the process of navigating through dynamically loaded pages, ensuring no data is missed.
Techniques for Handling Infinite Scroll
Scroll Simulation: Infinite scroll loads new content as users scroll down the page. Automated tools like Selenium or Puppeteer can simulate user scrolling actions, triggering the loading of additional content. Scripts can be programmed to scroll incrementally and capture new data until all content is loaded.
Content Monitoring: For sites using infinite scroll, monitoring changes in the DOM (Document Object Model) helps detect when new content is loaded. For web scraping dynamic content, automated scripts can track the changes, ensuring all newly loaded data is captured accurately.
Advanced Web Scraping Best Practices
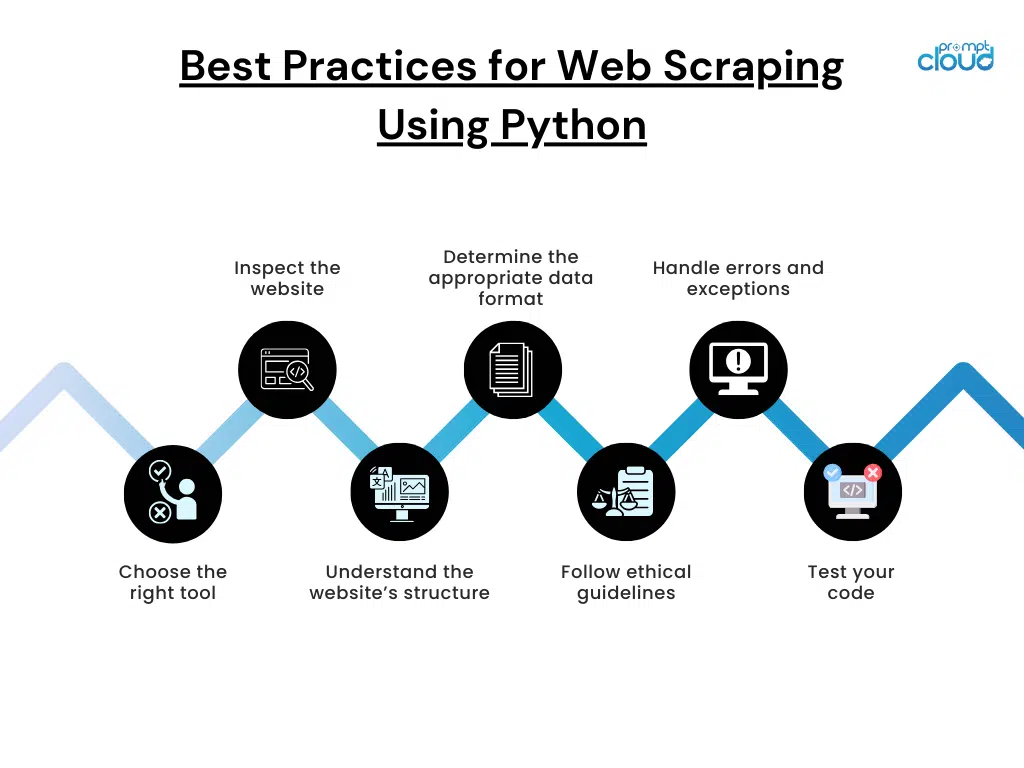
- Error Handling: Implement robust error-handling mechanisms to manage issues such as network interruptions or changes in website structure. This ensures the data extraction and web scraping dynamic content is resilient and reliable.
- Rate Limiting: To avoid being blocked by websites, implement rate limiting and respect the website’s terms of service. This involves controlling the frequency of requests and simulating human-like interactions.
- Data Validation: Continuously validate the extracted data to ensure completeness and accuracy. Implement checks to detect missing or duplicate data and handle these scenarios appropriately.
The automation of data extraction and web scraping dynamic content, given the complexity, is a strategic imperative for businesses aiming to thrive in the digital age. It enhances efficiency, provides real-time insights, ensures scalability, and delivers accurate and consistent data, all of which contribute to cost savings and a competitive advantage. By embracing automation, businesses can unlock the full potential of their data, driving innovation and growth in an increasingly complex and dynamic market.
At PromptCloud, we specialize in sophisticated web scraping solutions that adeptly handle pagination and infinite scroll, providing your business with complete and accurate data. Our expertise ensures you can navigate the complexities of dynamic web content, empowering you to harness the full potential of your data for strategic growth and success. Share your requirements at sales@promptcloud.com















