




Dynamic web scraping involves retrieving data from websites that generate content in real-time through JavaScript or Python. Unlike static web pages, dynamic content loads asynchronously, making traditional scraping techniques inefficient.
Dynamic web scraping uses:
- AJAX-based websites
- Single-Page Applications (SPAs)
- Sites with delayed loading elements
Key tools and technologies:
- Selenium – Automates browser interactions.
- BeautifulSoup – Parses HTML content.
- Requests – Fetches web page content.
- lxml – Parses XML and HTML.
Dynamic web scraping python requires a deeper understanding of web technologies to effectively gather real-time data.
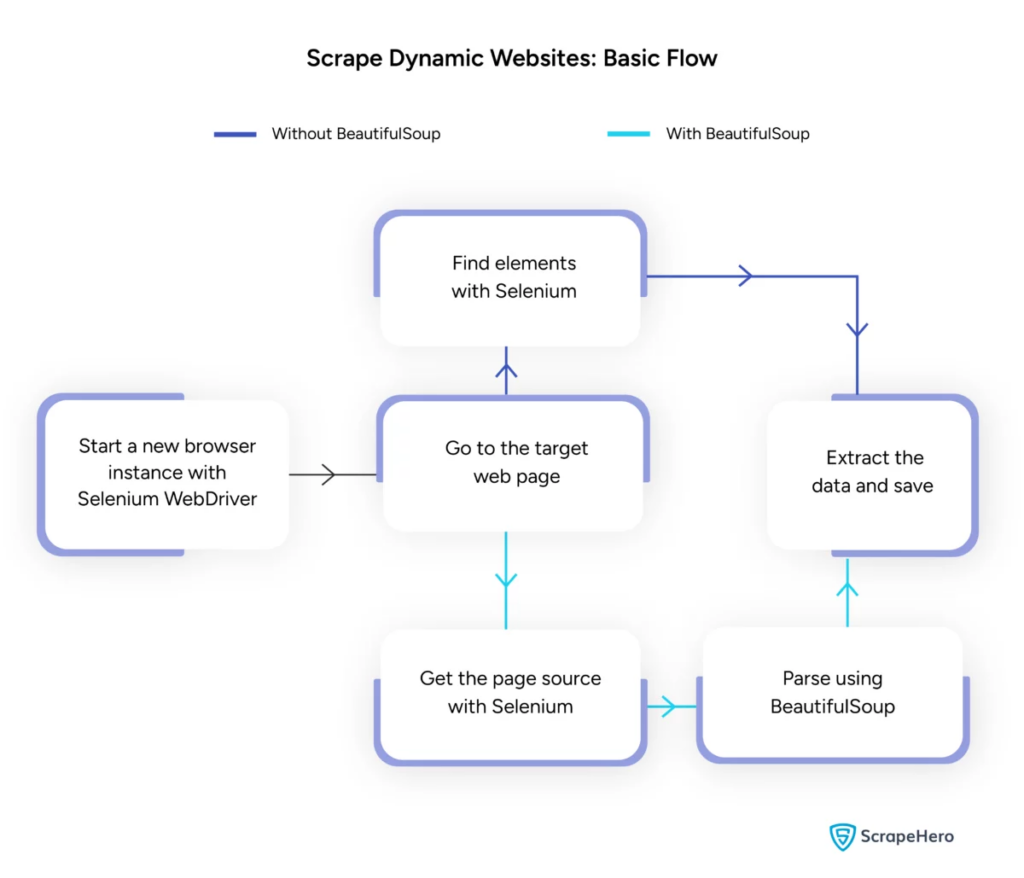
Image Source: https://www.scrapehero.com/scrape-a-dynamic-website/
Setting Up Python Environment
To begin dynamic web scraping Python, it is essential to set up the environment correctly. Follow these steps:
- Install Python: Ensure Python is installed on the machine. The latest version can be downloaded from the official Python website.
- Create a Virtual Environment:

Activate the virtual environment:

- Install Required Libraries:
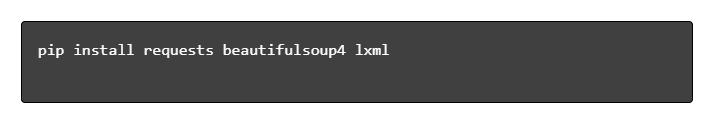
- Set Up a Code Editor: Use an IDE like PyCharm, VSCode, or Jupyter Notebook for writing and running scripts.
- Familiarize with HTML/CSS: Understanding webpage structure aids in effectively navigating and extracting data.
These steps establish a solid foundation for dynamic web scraping python projects.
Understanding the Basics of HTTP Requests
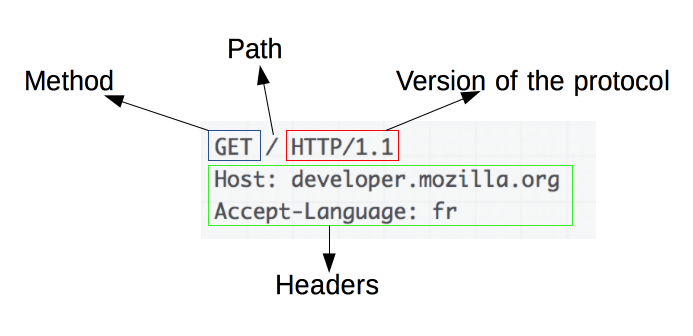
Image Source: https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview
HTTP requests are the foundation of web scraping. When a client, like a web browser or a web scraper, wants to retrieve information from a server, it sends an HTTP request. These requests follow a specific structure:
- Method: The action to be performed, such as GET or POST.
- URL: The resource’s address on the server.
- Headers: Metadata about the request, like content type and user-agent.
- Body: Optional data sent with the request, typically used with POST.
Understanding how to interpret and construct these components is essential for effective web scraping. Python libraries like requests simplify this process, allowing precise control over requests.
Installing Python Libraries
Image Source: https://ajaytech.co/what-are-python-libraries/
For dynamic web scraping with Python, ensure Python is installed. Open the terminal or command prompt and install the necessary libraries using pip:
Next, import these libraries into your script:

By doing so, each library will be made available for web scraping tasks, such as sending requests, parsing HTML, and managing data efficiently.
Building a Simple Web Scraping Script
To build a basic dynamic web scraping script in Python, one must first install the necessary libraries. The “requests” library handles HTTP requests, while “BeautifulSoup” parses HTML content.
Steps to Follow:
- Install Dependencies:

- Import Libraries:

- Get HTML Content:
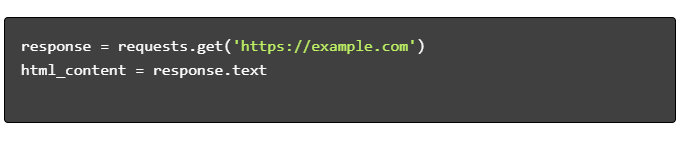
- Parse HTML:

- Extract Data:

Handling Dynamic Web Scraping with Python
Dynamic websites generate content on the fly, often requiring more sophisticated techniques.
Consider the following steps:
- Identify Target Elements: Inspect the web page to locate dynamic content.
- Choose a Python Framework: Utilize libraries like Selenium or Playwright.
- Install Required Packages:

- Set Up WebDriver:


- Navigate and Interact:

Web Scraping Best Practices
Its recommended to follow Web scraping best practices to ensure efficiency and legality. Below are key guidelines and error-handling strategies:
- Respect Robots.txt: Always check the target site’s robots.txt file.
- Throttling: Implement delays to prevent server overload.
- User-Agent: Use a custom User-Agent string to avoid potential blocks.
- Retry Logic: Use try-except blocks and set up retry logic for handling server timeouts.
- Logging: Maintain comprehensive logs for debugging.
- Exception Handling: Specifically catch network errors, HTTP errors, and parsing errors.
- Captcha Detection: Incorporate strategies for detecting and solving or bypassing CAPTCHAs.
Common Dynamic Web Scraping Challenges
Captchas
Many websites use CAPTCHAs to prevent automated bots. To bypass this:
- Use CAPTCHA-solving services like 2Captcha.
- Implement human intervention for CAPTCHA-solving.
- Use proxies to limit request rates.
IP Blocking
Sites may block IPs making too many requests. Counter this by:
- Using rotating proxies.
- Implementing request throttling.
- Employing user-agent rotation strategies.
JavaScript Rendering
Some sites load content via JavaScript. Address this challenge by:
- Using Selenium or Puppeteer for browser automation.
- Employing Scrapy-splash for rendering dynamic content.
- Exploring headless browsers to interact with JavaScript.
Legal Issues
Web scraping can sometimes violate terms of service. Ensure compliance by:
- Consulting legal advice.
- Scraping publicly accessible data.
- Honoring robots.txt directives.
Data Parsing
Handling inconsistent data structures can be challenging. Solutions include:
- Using libraries like BeautifulSoup for HTML parsing.
- Employing regular expressions for text extraction.
- Utilizing JSON and XML parsers for structured data.
Storing and Analyzing Scraped Data
Storing and analyzing scraped data are crucial steps in web scraping. Deciding where to store the data depends on the volume and format. Common storage options include:
- CSV Files: Easy for small datasets and simple analyses.
- Databases: SQL databases for structured data; NoSQL for unstructured.
Once stored, analyzing data can be performed using Python libraries:
- Pandas: Ideal for data manipulation and cleaning.
- NumPy: Efficient for numerical operations.
- Matplotlib and Seaborn: Suitable for data visualization.
- Scikit-learn: Provides tools for machine learning.
Proper data storage and analysis improve data accessibility and insights.
Conclusion and Next Steps
Having walked through a dynamic web scraping Python, it is imperative to fine-tune the understanding of the tools and libraries highlighted.
- Review the Code: Consult the final script and modularize where possible to enhance reusability.
- Additional Libraries: Explore advanced libraries like Scrapy or Splash for more complex needs.
- Data Storage: Consider robust storage options—SQL databases or cloud storage for managing large datasets.
- Legal and Ethical Considerations: Stay updated on legal guidelines about web scraping to avoid potential infringements.
- Next Projects: Tackling new web scraping projects with differing complexities will cement these skills further.
Looking to integrate professional dynamic web scraping with Python into your project? For those teams that require high-scale data extraction without the complexity of handling it internally, PromptCloud offers tailored solutions. Explore PromptCloud’s services for a robust, reliable solution. Contact us today!















