




How often do you need to scrape data from a website for your work and it seems like too much of a pain? This blog post will teach you how to scrape data in 5 easy steps.
This post is written for software professionals who need to extract data from web pages or PDFs and want the process to be as quick and painless as possible. There are many ways to scrape data but this article will focus on a few of the most popular methods that are used by professional developers: XPath, Regular Expressions, Beautiful Soup (BSA), Scrapy, Python Requests Library (PRL) and Selenium Webdriver. These scraping tools can all be easily installed with instructions provided for each one.
Scraping data on a website can be done with any language. In this article, I will demonstrate how to scrape data using Python because it is very easy to install and fairly easy to learn especially if you already know another programming language since the syntax is similar to Java, C and PHP.
Python supports multiple libraries for scraping data which are described in the table. Scraping is a tool that everyone should know how to use since it provides valuable insights into your target market, competitors and/or customers.
Web scraping can help you extract different types of data. You can crawl real estate listings, hotel data or even product data with pricing from eCommerce websites by writing a few lines of code. But if you are going to crawl the web and extract data, you need to take care of a few things.
It is important to make sure that the scraped data is in a usable format. Your code can extract data from multiple websites. The extracted data is clean and does not give erroneous results when running algorithms. That said, if you want to write your code or create a small web scraping project to crawl data from websites, you can do so in five simple steps.
How to Scrape Data in 5 Easy Steps
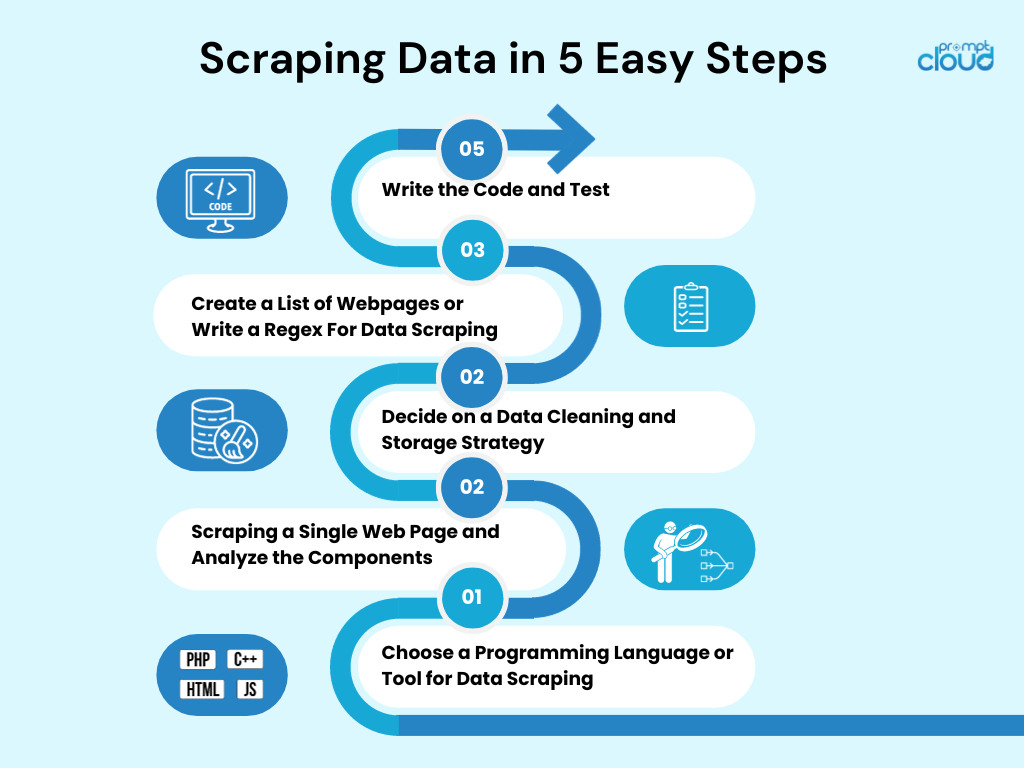
1. Choose a Programming Language or Tool for Data Scraping
“A man is as good as his tools”. Hence you need to choose your tools for web scraping in a way that suits your needs. While some ready-to-use software may seem easy to use, they might not allow you to make a lot of configuration changes. At the same time, many tools may not have a plugin to save the data that you scraped in a database or on the cloud.
When it comes to programming languages that are used for scraping of data today, there’s Node.js, Python, Ruby and more. But among these, Python is the most popular one thanks to its easier learning curve, simple syntax, the availability of multiple external libraries and the language being open source.
There are multiple libraries like BeautifulSoup and Scrapy that can be used to crawl web pages, create web crawling spiders, and run scraping jobs at specific time intervals. Python allows for immense flexibility when it comes to integrating other systems with your scraping engine. You could easily save your scraped data on your local machine, in databases, onS3 Storage, or even dump them into a Word or Excel file.
If you’re considering storing your scraped data in a MySQL database, MySQL Administration tools can simplify the management process, and you might also find it beneficial to use a GUI tool for more user-friendly database management.
2. Scraping a Single Web Page and Analyze the Components
Before you go about scraping product information from say a thousand product pages on Amazon, you need to access the page and get the entire Html page to analyze it and decide on a strategy. Data in Html pages can reside within specific key-value pairs in tags or the text within tags.
You can use libraries like BeautifulSoup to specify which exact tag you want to extract data from on every webpage and then run the code on a loop. This way, for every single product web page, your code will run and extract the same information- say, price details.
3. Decide on a Data Cleaning and Storage Strategy
Even before you start scraping the data, you should decide on where you will be storing the data. This is because how you process the data will depend on where you will be storing it. There are multiple options available. You can choose between NoSQL and SQL databases, depending on whether the data that you are scraping will be structured on unstructured.
For unstructured data, you can choose SQL databases since you can store the data in rows consisting of a set of attributes. For unstructured data, where there are no set attributes, you can go for NoSQL databases. In terms of what database to save the data in, for SQL you can choose MySQL or Postgres. Amazon RDS offers on-the-cloud databases where you can store your data and pay based on usage.
For NoSQL, you can choose one of their fully managed and extremely fast solutions, like Dynamo Dbor Elastic Search. Different databases have advantages that offer fast retrieval, some offer cheaper storage per TB. The database you choose depends on your specific use case and hence. Some research needed on this before you decide on one.
In case you need to store scraped images and videos that are large, you can use AWSS3 or Glacier.The latter is used when you want to store massive amounts of data in an archived format. You would not need to access often while the former is the more used solution. This acts as something like an online hard drive. You can create folders and save files in them.
Image Source: https://www.melissa.com/
4. Create a List of Webpages or Write a Regex For Data Scraping
While you may test your code on a single webpage, you must be wanting to crawl tens or hundreds of pages because of which you are undertaking this project. Usually, if you are going to crawl a few web pages, you can save the links in an array and loop over it when scraping the pages. A better and more frequently used solution is to use a regex. Simply put, it is a programmatic way to identify websites with similar URL structures.
For example, you might want to crawl product data of all the laptops on Amazon. Now you might see that all the URLs begin with “www.amazon.com/laptop/<laptopModelNo>/prodData”. You can replicate this format using regex so that all such URLs are extracted and your web scraping function running on only these URLs. And not all the URLs on Amazon’s website.
In case you have too many web pages to crawl, we recommend that you use a parallel processing approach to crawl around ten web pages at any moment. If you are scraping web pages and extracting links from them, and then scraping the web pages that those links lead to, then you can use a tree-like approach to crawl multiple child pages arising from a root webpage at the same time.
5. Write the Code and Test
Everything we have discussed until now has been the preparation. For the final act of running the code and getting the job done. Web scraping code rarely works exactly the way you are expecting it to. This is because not all web pages that you are trying to crawl would have the same structure. For example, you run your scraping code on 100 product pages and find only 80 of them have been scrapped.
The reason behind this is that 20 pages may be in the out-of-stock state and their webpage structure is different. Such exceptions will not account for when you write the code. But after a few iterations, you can make the required changes. And extract data from all the web pages that you need.
Alternative Data Scraping Methods
Use the Excel Filter function to scrape data
This is the easiest way to scrape data from any web page. It requires no extra tools except Excel and it will not leave a footprint on your target website or your system i.e. no API calls are made, no cookies are set etc. If you have access to a PC/Mac with Excel installed then this is by far the easiest way to scrape data.
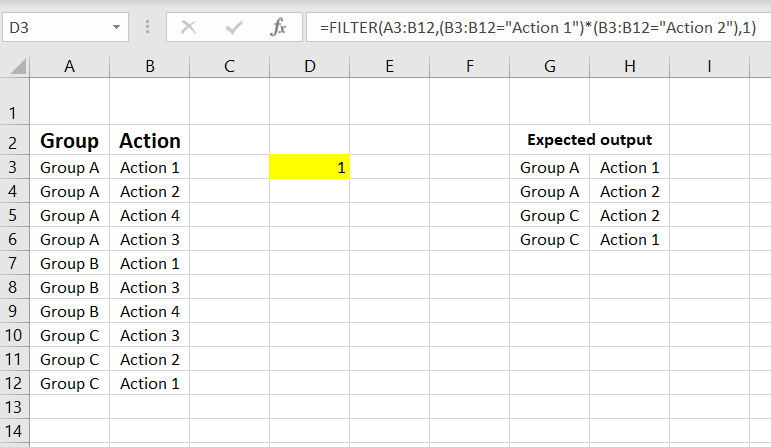
Image Source: StackOverflow
How it works
In Excel, open a new sheet and write your target website’s URL in the first cell (e.g. http://www.joes-hardware-store.com/). In the next cell, enter an HTML or XPath Data Filter formula (see table below for the XPath Data Filter formula used in this example) that will extract data from your target web page. If you want to scrape multiple columns of data, repeat Step 1 for each column of data and put them side by side.
How to get XPath Data Filters in Excel
- Open Excel and click on File > Options > Advanced.
- In the Advanced settings, navigate to the Display section.
- Check the box next to “Show Developer Tab in the Ribbon” and click OK.
- Click on Developer > Reference.
- Scroll down and find Microsoft XML Document 3.0.
- Click on MSXML3 Apress, then click OK.
- With the MSXML3 Reference installed, enter your target web page URL into cell A1 in Excel.
- In cell B1, enter an XPath Data Filter formula (e.g., to get the price of item “123”).
- Copy the contents of cell B1 to all remaining cells using Excel’s CTRL+C shortcut.
- Paste your target web page URL (in cell A1) into Excel’s address bar.
- Press Enter to load it into the browser and see your data magically appear in Excel
As you can see, this is an extremely efficient way of scraping data. There is no footprint left on the target website or your system i.e. no API calls are made, no cookies are being set etc.
Use the Text-to-Columns function in Microsoft Word to separate data by column
This method is a bit more complicated than the first but it can be used to scrape data from any website that has clearly defined columns. It requires MS Word and Excel plus some extra tools which are described below. The good news is that this method does leave a footprint on your target website so if you are scraping websites for marketing purposes and want to avoid detection, this method is not for you.
How it works
Create MS Word Document:
- Open MS Word and create a new document, naming it appropriately (e.g., Joe’s Hardware Store Product Listing Scraping Tool).
- Copy and paste the content of your target web page into the document.
Navigate Using Goto Function:
- Press CTRL + G to access the Goto function in MS Word.
- Type <<!DOCTYPE HTML [ENTER].
Run MS Word Macro:
- Press ALT + F5 to access the Run function in MS Word.
- Execute the macro; this step should result in a specific outcome based on the applied actions.
Use Excel Text to Columns:
- Open Excel and select the “Filters” option.
- Choose “Text to Columns.”
- Select “Delimited” and pick the appropriate separator from the drop-down menu (e.g., Comma).
- Click “Next” and specify the location of separators to separate web data into columns.
- Define how Excel should handle empty cells (e.g., ignore or substitute with a blank value).
- Click “Finish” to complete the Text-to-Columns function.
Substitute Values for Unclear Columns:
- If the target web page lacks clearly defined columns, set the function to “Substitute Values” in Excel.
Review Separated Data:
- Examine the results; the data should now be separated into individual columns of text.
- Copy/paste the separated data to another location on your computer.
Useful for PDF Data Extraction:
- This method is particularly efficient for extracting data from PDF files with well-defined column headings.
- It is advantageous for automating data extraction from multiple PDF files using Excel macros, leveraging the same MS Word template repeatedly.
Use MS Excel VBA Editor with xvba Tool:
- Download the xvba tool from the provided source.
- Open the MS Excel VBA Editor.
- Utilize xvba as an API-like tool for scraping data without the need to write code.
- Note that typing HTML from the target web page is required; consider using MS Word to break down the web page components.
Understanding Variables in Excel:
- The numbers inside square brackets represent individual cells in a spreadsheet.
- These cells use column and row headings as names for each data field, functioning as variables.
- The variables are treated as text by Excel and will change based on the spreadsheet’s structure (e.g., selecting a different column for data filtering).
Use IMPORTXML in Google Sheets
When you are using IMPORTXML to scrape data from a web page, the first step is to Open Google Sheets. The second step is to go to Tools > Script Editor. The third step is to copy/paste your target website’s HTML code into the text box.
The data is successfully separated into individual columns of text and I can now easily copy/paste them into another location on my computer. We have used this method in the past to scrape Facebook and Twitter data for an online marketing campaign. It is also a good way to scrape data from websites that use AJAX when you don’t want to use the GOTO command.
Use IMPORTHTML in Google Sheets
This method is similar to method number 3, but instead of using IMPORTXML , we are going to use IMPORTHTML . The first step is to Open Google Sheets. The second step is to go to Tools > Script Editor. The third step is to copy/paste your target website’s HTML code into the text box.
Using Chrome Extensions
You can scrape web data using Chrome extensions such as Data Scraper and Save To CSV. Since there is a free and paid version of the Chrome extensions (Data Scraper), I would suggest having both to see which one works better for you.
Conclusion
Scraping up to a few hundred pages (while making sure you give a few seconds gap in between each run). Scraping a website once a month would work fine with a DIY solution written in Python. But in case you are looking for an enterprise-grade DaaS solution, our team at PromptCloud provides an end-to-end solution where you give us the requirement and we hand you the data which you can then plug and play.
Infrastructure, proxy management, making sure you don’t get blocked while scraping data. Running the scraping engine at a regular frequency to update the data. We also make changes to accommodate changes made in the UI of the concerned website. Everything is handled in our fully managed solution. This is a pay-per-use cloud-based service. This will fulfil all your web scraping requirements. Whether you are handling a startup, an MNC or you need data for your research work. We have data scraping solutions for all.
Frequently Asked Questions (FAQs)
What does scrape mean in data?
Regarding data, the term “scrape” pertains to extracting information from websites or other online sources. This process utilizes automated tools or scripts to collect particular data points, including prices, reviews, or contact details, from diverse web pages. Think of it as a digital harvesting method for relevant information, commonly employed by businesses, researchers, or analysts to streamline data collection processes.
Is it legal to scrape data?
When it comes to scraping data, the question of legality depends on your intentions and methods. Generally, it’s considered legal to scrape public information as long as you’re not violating a website’s terms of service. However, extracting non-public data, breaking terms of use, or causing harm to the targeted site may land you in legal trouble. It’s crucial to scrape ethically, follow website policies, and, if you’re unsure, consult legal advice to make sure you’re on the right side of the law.
What is the data scraping technique?
Data scraping involves various techniques, but one common method is using web scraping tools that navigate through websites, extract HTML, and parse relevant information. XPath and regular expressions are often employed to pinpoint specific data within the HTML structure. Another technique is utilizing APIs when available, providing a more structured and legal means of accessing data. The choice of technique depends on the target website, the desired data, and ethical considerations.
What is your method for scraping data?
Opting for web scraping service providers is a prudent approach to ensure efficient and ethical data extraction. These providers typically offer comprehensive solutions, handling infrastructure, proxy management, and adapting to website changes. They employ sophisticated technologies to minimize the risk of being blocked while maintaining the scraping engine’s regular frequency. For those seeking a hassle-free, pay-per-use cloud-based service, web scraping service providers like PromptCloud provide end-to-end solutions, making them suitable for startups, enterprises, or research endeavors.
What is meant by scraping data?
Scraping data refers to the process of automatically extracting information from websites. This is typically done using software that simulates human web surfing to collect specific data from web pages. The data extracted can be used for various purposes such as analysis, research, or feeding into other software systems.















