




Founded in the year 2000, Boston based travel website is one of the most used travel portals around the world. But with so many users and hotels and bookings, and reviews, you can understand the magnitude of travel data generated. So let’s see what to do with that data, and how to scrape hotel data using python.
How can You Benefit by Scraping Hotel Data?
We learned some of the important facts related to the mega-giant of world-tourism’s booking industry. Now what matters is how you can benefit from crawling and scraping it? Well, unlike the website, you might be catering only to the people in a particular country, or maybe even a city or a locality. It might be difficult going about mapping every lodge and hotel, especially if you are just setting up your business. If you crawl data off this site, you will get be getting various details of each hotel such as:
- Full Name
- Representative Image
- Complete Address
- Price Range of Rooms
- Ratings
- Reviews
With so much data, you could easily monitor your competitors’ pricing and understand what users are saying about various properties via reviews. Given below are the important applications of pricing data and customer reviews:
- Competitive pricing and pricing intelligence from the pricing data
- Ensuring that the OTAs adhere to your brand pricing and consistency
- Understanding inventory movement based on season and location
- Brand monitoring for online reputation management
- Understanding consumer preferences
Today we’ll be showing you how to crawl all the above mentioned data in JSON format, for a particular hotel, given you have the URL.
Once you have the data in a JSON format, you can store it in your own NoSQL database and use it as and when required. If you need the prices, you can access only the price, when you need to show someone a representative image, you can do that too, and so on. You can keep scraping and adding to your database, while you build a system to update historical data by keeping a list of your previously scraped hotel URL. Such a system at large-scale can be built with the help of experienced web scraping solution providers like PromptCloud.
So, let’s start with the basics.
1. Setting up a Source Code Editor
To copy and edit the code snippet given later on, you will be needing a code editor, or an IDE. The basic difference between the two is that, a code editor will let you edit code of any programming language, and you can run the code from the command prompt, after editing and saving the code. However, in an IDE (Integrated Development Environment) like PyCharm, you will be having options like source code editor, automation tools for build, and debugger. There are multiple free options, for both IDE and code editors, such as Pycharm, Sublime and Atom. It is easier to get started with Atom, since it allows additional functionalities that one finds in IDEs through the installation of add on packages for different programming languages. This is the link for atom
On visiting their website, you will be seeing that they would have already detected your operating system, as well as its compatibility (32-bit or 64-bit). Depending on that, they will be providing you with the latest version of their editor. Just click on the Download button.
Many people use Git, a popular versioning software to keep track of their code. In case you use it too, atom provides amazing integration with GitHub.
The atom installation file will be around 150MB, and once it is downloaded, you can click on it to get to see the popup given below. It will remain while the installation takes place, so you might have to wait for a minute or two.

2. Atom Installer
Once Atom is installed, you can also install some packages, like we discussed before, which will give you some of the functionalities of an IDE. This will make coding easier for you, with features like autocomplete and easy debug. Press CTRL+ comma-button (press control button and comma button at the same time). Or you could go the long way and select File >> Settings >> Install. Here you can type Python in the search bar and get different packages for yourself such as autocomplete-python that will help you giving suggestions as you type, so as to autocomplete your code.
If you have any existing code files in your computer (such as java files or ruby files), you can load them in atom and see how it all looks. There are many more features in Atom, such as changing the theme, but the exploration part is left for you which can be done with a little bit of help from Google.
3. Installing Python
Some basic programming experience in any sort of object oriented programming language is recommended. However, this DIY tutorial will help you execute the scraper and get your data so that you extract the data to gain basic understanding. We will be covering everything right from installation to viewing the JSON.
First you need to visit the following link – https://www.python.org/downloads.
Click on the Download Python 3.7.0 button. The version displayed might be a higher one, depending on how many days from now you are checking the website. Also, depending on your operating system, Linux, Mac, or Windows, the version of Python might differ.
Once the installation file is downloaded, you can click on it, and select install. Follow the instructions and select where you want Python to be installed. Here is a screenshot of the installation file for the 32-bit version of Python 3.7.0 Make sure that you tick both the boxes before clicking on Install Now. In case you want to make customizations such as changing the directory in which you want Python to be installed, you can also click on the Customize Installation button.
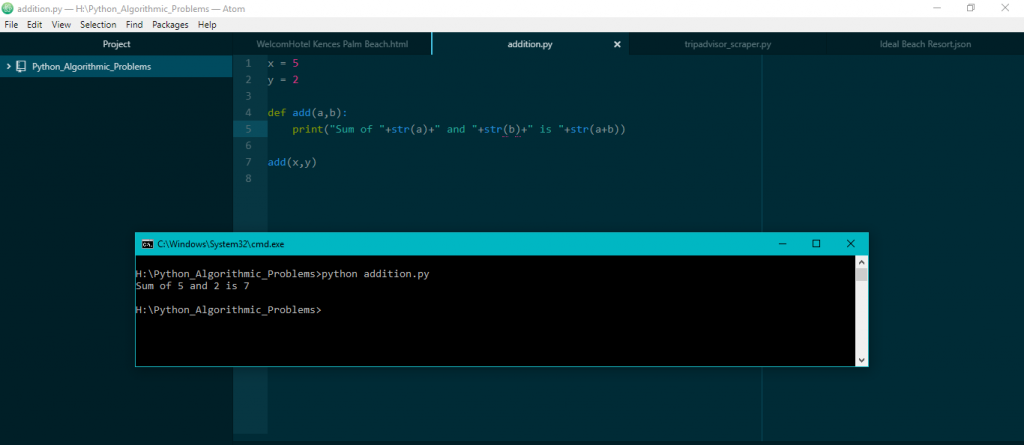
Once the installation is done, you can run a python program to see if everything is working fine. You need not have any Unix knowledge for executing python programs from the command prompt. All you need to type is python followed by the name of the file that you are trying to run and then press enter. Remember to save all your files with a .py extension since the .py extension designates that a file is a Python file. Now let us try out a simple python program that gives us the sum of two numbers. We will create a file in the current directory with the name of addition.py and type the following code in it-
[code language=”python”]
x = 5
y = 2
def add(a,b):
print(“Sum of “+str(a)+” and “+str(b)+” is “+str(a+b))
add(x,y)
[/code]
We will then execute it from command prompt using –
[code language=”python”]python addition.py[/code]
This will run the program and display you the sum of the two numbers. You can write similar functions for subtraction, division, and so on and get the feel of python.
In python, several people have created functionalities that can be reused. These are called Python libraries. You can use these by importing them in your program, but before you do so, you need to make sure, that you have installed those packages using pip. Pip is a command line package manager that comes bundled with python.
For this tutorial we will be using BS4, better known as Beautiful Soup. It is a Python library for grabbing data from HTML and XML files. It works with any parser (or lxml parser by default), to provide idiomatic ways of navigating, searching, and modifying the parse tree. This helps scavenge data from scraped html using a single line of code. Manually doing this would have taken hours, if not days.
Documentation pages for more info on beautiful soup is available here – Beautiful Soup (bs4).
If it is already installed in your system (in case someone was using python in the system previously), you will see this message in your command line –
“Requirement already satisfied message”.
How to Web Crawl it
Now that the environment and text-editor is set up, we can get down to the real business. You’ll understand how data can be extracted from a web page of a particular hotel.
When you execute the code, you will be prompted to give a url. You can give the URL for any hotel page. We will take the following –
The code to crawl the web page is given below. Enter the above mentioned URL when prompted, after running this program. Link for code in case of any issues –
[code language=”python”]
import urllib.request, urllib.parse, urllib.error
from bs4 import BeautifulSoup
import ssl
import json
import re
import sys
import warningsif not sys.warnoptions:
warnings.simplefilter(“ignore”)#For ignoring SSL certificate errors
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE# url = input(‘Enter url – ‘ )
url=input(“Enter Hotel Url – “)
html = urllib.request.urlopen(url, context=ctx).read()
soup = BeautifulSoup(html, ‘html.parser’)
html = soup.prettify(“utf-8”)
hotel_json = {}
for line in soup.find_all(‘script’,attrs={“type” : “application/ld+json”}):
details = line.text.strip()
details = json.loads(details)
hotel_json[“name”] = details[“name”]
hotel_json[“url”] = “https://www.<domainname>.in”+details[“url”]
hotel_json[“image”] = details[“image”]
details[“priceRange”] = details[“priceRange”].replace(“₹ “,”Rs “)
details[“priceRange”] = details[“priceRange”].replace(“₹”,”Rs “)
hotel_json[“priceRange”] = details[“priceRange”]
hotel_json[“aggregateRating”]={}
hotel_json[“aggregateRating”][“ratingValue”]=details[“aggregateRating”][“ratingValue”]
hotel_json[“aggregateRating”][“reviewCount”]=details[“aggregateRating”][“reviewCount”]
hotel_json[“address”]={}
hotel_json[“address”][“Street”]=details[“address”][“streetAddress”]
hotel_json[“address”][“Locality”]=details[“address”][“addressLocality”]
hotel_json[“address”][“Region”]=details[“address”][“addressRegion”]
hotel_json[“address”][“Zip”]=details[“address”][“postalCode”]
hotel_json[“address”][“Country”]=details[“address”][“addressCountry”][“name”]
break
hotel_json[“reviews”]=[]
for line in soup.find_all(‘p’,attrs={“class” : “partial_entry”}):
review = line.text.strip()
if review != “”:
review = line.text.strip()
if review.endswith( “More” ):
review = review[:-4]
if review.startswith(“Dear”):
continue
review = review.replace(‘r’, ‘ ‘).replace(‘n’, ‘ ‘)
review = ‘ ‘.join(review.split())
hotel_json[“reviews”].append(review)
with open(hotel_json[“name”] + “.html”, “wb”) as file:
file.write(html)
with open(hotel_json[“name”] + “.json”, ‘w’) as outfile:
json.dump(hotel_json, outfile, indent=4)
[/code]
Once you run the program and give the html provided, you will be getting a json file, with name same as the name of the hotel (Radisson BLU Resort Temple Bay Mamallapuram.json), and it will look as shown below. Link to json for easy use –
[code language=”python”]
{
“name”: “Radisson BLU Resort Temple Bay Mamallapuram”,
“url”: “https://www.<domainname>.in/Hotel_Review-g1162480-d478012-Reviews-Radisson_BLU_Resort_Temple_Bay_Mamallapuram-Mahabalipuram_Kanchipuram_District_Tamil_N.html”,
“image”: “https://media-cdn.<domainname>.com/media/photo-s/03/e5/92/9b/radisson-blu-resort-temple.jpg”,
“priceRange”: “Rs 8,356 – Rs 36,027 (Based on Average Rates for a Standard Room)”,
“aggregateRating”: {
“ratingValue”: “4.0”,
“reviewCount”: “2407”
},
“address”: {
“Street”: “57 Covelong Road”,
“Locality”: “Mahabalipuram”,
“Region”: “Tamil Nadu”,
“Zip”: “603104”,
“Country”: “India”
},
“reviews”: [
“A well maintained sprawling resort on the beach. Has one of the largest swimming pool, acres of lawn, lots of activities for kids, well decorated rooms, play cricket, volley ball, friendly staff and a view of the shore temple on the beach. Food is average….”,
“This place is awesome.We got a pool facing room.The buggy took us around lush green lawns,flowers and coconut trees.Very well maintained place. The pool is probably the best part of the resort.The beach,the deck area is lovely.Service is good.We were told that the resort was…”,
“I Have Good Experience With Radisson BLU Resort Temple Bay Mamallapuram. Been there for one whole day with my team. I loved this place and the beach attached with Resort. Delicious Food &amp; Welcome Drink.”,
“I stayed there for 1 day along with complete family. We had booked 6 rooms and the quality of rooms was so good that every family member was happy. Good service good food good pool good staff. Overall a very good stay”
]
}
[/code]
Extracted Data
You can see several different fields in the JSON. Let us explain them to you for easier consumption. The name field is self-explanatory, and it is followed by URL, image and price-range. The URL is actually the same URL that you gave the program when it asked for one –

It is included in the JSON in case you need it later. The image URL will give you a representative image of the hotel and the price range will give you an idea of the minimum rate at which you can get the standard room and the maximum cost of the best suites. The address field is broken into several sub fields just for easier filtering, depending on the use case. Street, locality, region, zip code, and Country, all are provided to you. You can consolidate and use them as one, or use them for filtering by zip code, or country, or region, and so on.
The aggregate Rating field has the ratings out of five and the number of people who actually reviewed the hotel. Why are both important? Suppose a hotel is rated 4.9/5 stars, but only 10 people have reviewed it, whereas another one is rated 4.5/5 stars, but is reviewed by 2,500 people. Which one would a customer book?
Next you will come across the reviews field, consisting of the top reviews in the primary page of the hotel. You can see that some of the reviews are too long and got truncated in the form of “…”. Programmatically this can be expanded to reveal the complete review as well. You can use this to data and run text mining techniques to understand the Voice of Customer pertaining to the hotel, its pros and cons.
All this data can be broken and their formats can be changed, and they can be used as you like it, since the JSON is readable from all programming languages and follows a standard format that is accepted worldwide.
After running the program, you can see that an html file with the name of the hotel has also been created. It is a complete copy of the html page that has just been scraped. You can use it for further analysis and try your own hand at scraping data from it.
When Should you Go with a Web Scraping Service Provider?
Most people without coding knowledge might still be unsure about the entire process. While this can be used as a learning process, enterprises that require large-scale data at regular frequency should opt for a specialized crawling solutions provider. Here are the primary benefits of working with professional like PromptCloud – a fully managed web scraping service provider:
- Fully managed service
- Fully customizable
- Dedicated support with strong SLA
- Low latency
- Highly scalable
- Upkeep
Disclaimer: The code provided in this tutorial is only for learning purposes. We are not responsible for how it is used and assume no liability for any detrimental usage of the source code.















