



Today, we are no longer restricted by desktop apps, web apps, or any native apps that keep data in silos via proprietary back-ends. The apps on mobile phone might be browser-based or native, but the majority of them ingest data from many sources. Data is getting sourced from everywhere and how are apps collecting data from these diverse data sources? Well, mostly via an API, an application programming interface.
However, there are still large amounts of data out there on web pages that are not accessible via API (the website operator doesn’t offer one). And even in cases where the operator of the site offers an API, the API might come with restrictions in terms of data points, freshness, and number requests. Also, sometimes they are not maintained with time.
This is where leveraging web page technology to convert websites into APIs became important. The use case for using Web Page Adapters to build structured data web pages and publish structured data has been in practice since the time when JavaServer Pages (JSP), Active Server Pages (ASP), and Adobe’s ColdFusion emerged. Using web pages to format and showcase data retrieved from a database became essential, especially when it came to uploading product catalogues online.
However, as the web has matured, data-driven pages have become a common norm well beyond their consumption by human eyes. There is a need for various use cases pertaining to the data stored in these web pages. And that is how web crawlers help people make use of this data to propel business growth. It can be anything from improving the analytics engine and product strategy backed by Voice of Customer to creating a new completely alternative solution by keeping the web data as the foundation.
For example, think of a mobile device marker that is selling its products on several online marketplaces and it wants to make sense of the thousands of reviews posted by its customers and rivals’ customers.
With web crawling, this data can be made available in an automated manner via an API and it can be queried to retrieve structured data. The data structured data downloaded via the API can be easily loaded in a spreadsheet and any other database.
Now, this data can be sliced and diced based on any criteria. Analysts can perform simple statistical analysis and advanced Natural Language Processing techniques. That’s the beauty of the web data when it gets extracted and delivered in an easy-to-consume manner without compromising on the quality.
And, finally, what if the requirement entails data download in JavaScript Object Notation (JSON) or XML via API? That’s also very much possible by programming the crawlers to extract data in any format.

Getting large-scale structured data out of web pages at a certain frequency via “web scraping” is truly a complex technical process that is tremendously helping people whose job is to prepare and analyze the information available on web pages. Fully managed web crawling service providers, such as PromptCloud are at the forefront in this space.
The REST-ful API exposed by PromptCloud can be used to consume web data without worrying about the maintenance of the crawler. However, it works in a manner completely different from the “data extraction tools”. Primarily because of the nature of the operation. It sits a sweet spot between a product and a fully customizable web crawling platform.
PromptCloud’s fully managed web scraping service requires the following from the client:
– List of websites from which data needs to be extracted
– List of data points
– Format of the data (CSV, XML, JSON, etc.)
– Frequency of crawling (from near real-time and hourly to weekly and monthly)
Once this is finalized, PromptCloud’s engineering team builds and maintains (in case page structure changes) the dedicated crawlers to extract desired data. This data is pushed to the API that the client can access via a unique API key.
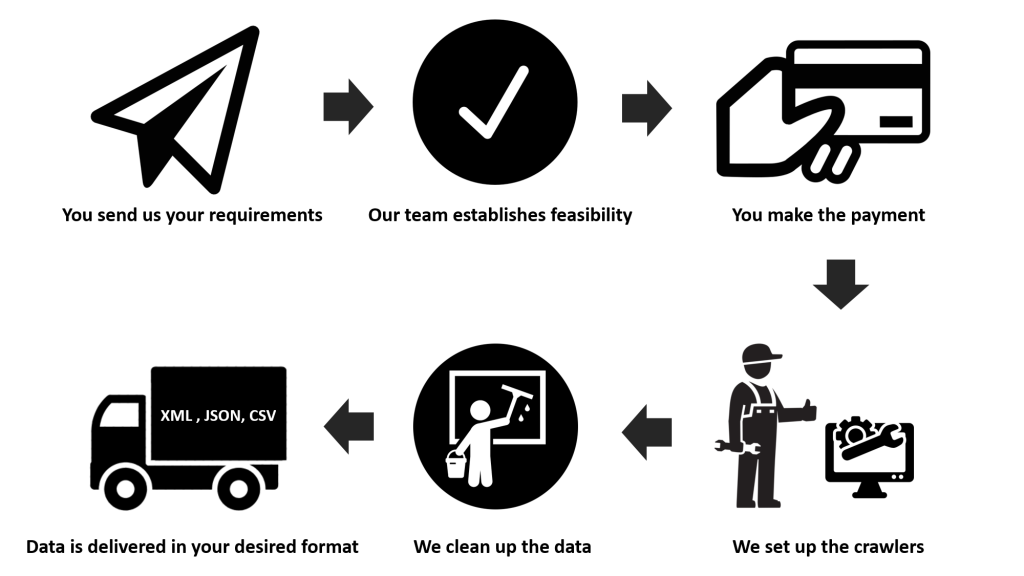
With this solution, PromptCloud makes it possible for the businesses to collect high volume web data without worrying about the technical infrastructure, data delivery pipeline, maintenance, engineering talent, software, proxy service, quality assurance. All these aspects of data delivery are completely taken care of by PromptCloud.
The API will be basically a big data feed of all the data points that clients choose on a specific website. The crawler is set on a schedule to periodically revisit that site and crawl any new data. After it retrieves the data and structures it, the API can be used to push data into any application you have decided to build. The client only has to look into the various parameters available in the API for data consumption and perform the post-acquisition processes.















