



In an era of increasing digitalization, data is the new currency. It is one of many factors that will decide if you can keep up with your competitors. The more data one has, the more advantageous it will be to him. And one way of getting the data is through web data crawler.
Fig: Web Scraping multiple websites and aggregating data
Web Data Crawler for Businesses
Web scraping refers to a process wherein data is extracted from websites. The bots used to extract the data are referred to as data crawlers or spiders. It is not a pixel-by-pixel extraction, but rather, the extraction of the underlying HTML code and data engulfed in it. Loads of businesses rely on web scraping for data- ranging from market research companies who use social media data for sentiment analysis to sites that auto-fetch prices for seller websites.
Web Scraping or Web Data Crawler Techniques
Manual Scraping
Manual scraping is copy/pasting relevant information and creating a spreadsheet to keep track of the data. As simple as manual scraping sounds, it comes with its pros and cons:
Pros
- One of the easiest methods of web scraping, it does not require one to have any prior knowledge or skills to using web data crawler.
- There is little margin for error as it allows for human checks during the process of extraction.
- One of the problems surrounding the process of web scraping is that fast extraction often causes the website to block access. Since manual scraping is a slow process, the question of getting blocked does not arise.
Cons
- The slow speed is also a hassle to time management. Bots are significantly faster at scraping than humans.
Automated Scraping
Automated web scraping or web data crawler can be done by writing your code and creating your own DIY web scraping engine, or by using subscription-based tools that can be operated by your business team with a week of training. Multiple no-code-based tools have become popular with time as they are easy to use and save both time and money.
As for those who want to create their web data crawlers or scrapers, you can get yourself a team that would code the stages that need to be performed to gather data from multiple web pages and then automate the whole process by deploying crawlers having this information in the cloud. Processes that are involved with automated scraping usually include one or more of the following:
HTML Parsing: HTML parsing uses JavaScript and is used for linear or nested HTML pages. It is generally used for link extraction, screen grabbing, text extraction, resource extraction, and more.
DOM Parsing: The Document Object Model, or DOM, is used to understand the style, structure, and content within XML files. DOM parsers are put to use when the scraper wants to get an in-depth view of the structure of a web page. A DOM parser can be used to find the nodes that carry information, and then with the use of tools like XPath web pages can be scraped. Web browsers such as Internet Explorer or Mozilla Firefox can be used along with certain plugins to extract relevant data from web pages even when the generated content is dynamic.
Vertical Aggregation: Vertical aggregation platforms are created by companies that have access to large-scale computing power to target specific verticals. Sometimes, companies make use of the cloud to run these platforms as well. Bots are created and monitored by the platforms without the need for any human intervention based on the knowledge base for the vertical. Due to this reason, the efficiency of the bots created depends on the quality of the data they extract.
XPath: XML Path Language, or XPath, is a query language that is used on XML documents. Because XML documents have a tree-like structure, XPath is used to navigate by selecting nodes based on a variety of parameters. XPath along with DOM parsing can be used to extract entire web pages.
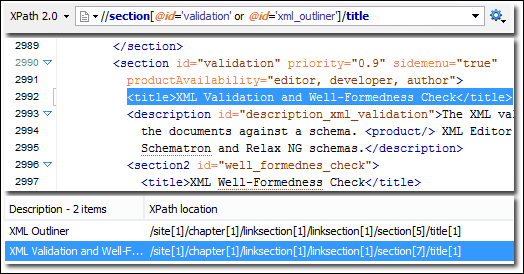
Fig: Extracting data using Xpath. Source: XPath Support (oxygenxml.com)
Google Sheets: Google Sheets is a popular choice for scrapers. With Sheets, the IMPORTXML (,) function can be used to scrape data from websites. It is particularly useful when the scraper wants to extract specific data or patterns from a website. The command can also be used to check if your website is scrape-proof.
Text Pattern Matching: This is a common expression-matching technique that makes use of the UNIX grep command and is usually incorporated with programming languages such as Perl or Python.
Such web scraping tools and services are widely available online, and scrapers themselves do not have to be highly skilled in the above techniques if they do not want to do the scraping themselves. Tools such as CURL, Wget, HTTrack, Import.io, Node.js, and more are highly automated. Automated headless browsers such as Phantom.js, Slimmer.js, Casper.js can also be used by the web scraper.
Pros
- Automated scraping or web data crawler can help you extract hundreds of data points from thousands of web pages in a few seconds.
- The tools are easy to use. Even an unskilled or amateur coder can make use of user-friendly UIs to scrape data from the Internet.
- Some of the tools can be set to run on a schedule and then deliver the extracted data in a Google sheet or a JSON file.
- Most of the languages like Python come with dedicated libraries like BeautifulSoup that can help scrape data from the web easily.
Cons
- The tools require training and the DIY solutions require experience- so you either need to dedicate some energy of your business team towards web scraping or get a tech team to handle the web scraping efforts.
- Most tools come with some limitations, one might not be able to help you scrape data that are behind a login screen, whereas others may have issues with embedded content.
- For paid no-code tools, upgrades may be requested, but patches can be slow and may not prove helpful when working with tough deadlines.
Data as a Service (or DaaS)
As the name suggests, this translates to outsourcing your complete data-extraction process. Your infra, your code, maintenance, everything is taken care of. You provide the requirements and you get the results.
The process of web scraping is complicated and requires skilled coders. The infrastructure along with the manpower that is required to sustain an in-house crawling setup can become too burdensome, especially for companies that do not already have an in-house tech team. In such cases, it is better to make use of an external web-scraping service.
There are many benefits to using a DaaS, some of which are:
Focus on Core Business
Instead of spending time and effort on the technical aspects of web scraping and the setting up of an entire team to revolve around it, outsourcing the job allows for the focus to remain on the core business.
Cost-Efficient Compared to DIY Web Data Crawler
An in-house web scraping solution will cost more than getting a DaaS service. Web scraping is not an easy job and the complexities mean you will have to get skilled developers which will cost you in the long run. Since most DaaS solutions will charge you based on the usage only, you will be paying only for the data points you extract and the total data size.
No Maintenance
When you build an in-house solution or use web scraping tools, there is an added overhead of a bot breaking down due to changes in the websites or other technical issues that may need to be fixed immediately. This might mean that someone or a team would always need to be on the lookout for inaccuracies in the scraped data and keep a check on the overall system downtime. Since websites can change often, the code will need to be updated each time it does so or there will be the risk of a breakdown. With DaaS providers, you will never have to bear the added hassles of maintaining an in-house web scraping solution.
When it comes to web scraping or web data crawler, you can pick and choose from the methods discussed above according to your specific needs. However, if you require an enterprise-grade DaaS solution, we, at PromptCloud, offer a fully managed DaaS service that can provide you scraped data points cleaned and formatted all based on your preferences. You need to specify your requirements and we will provide you with the data which you can then plug and play. With a DaaS solution, you can forget about the inconveniences of maintenance, infrastructure, time and cost, or getting blocked while scraping from a site. We are a pay-per-use cloud-based service that will cater to your demands and fulfill your scraping requirements.















