



[vc_row][vc_column css=”.vc_custom_1490791408767{background-color: #f9f463 !important;}”][vc_column_text]This post is about DIY web scraping tools. If you are looking for a fully customizable web scraping solution, you can add your project on CrawlBoard.
[/vc_column_text][/vc_column][/vc_row]
Looking for data to fuel your business strategy? You simply can’t collect data by searching on Google for what you’re looking for and copying them manually to a spreadsheet. This wouldn’t make any sense as the data requirement is huge when you need to do something useful from the process. Although search engines can help you find what you’re looking for in a matter of seconds, the data you would find is not structured and hence can’t be used for analysis.

You may have been lucky enough to get a spreadsheet from some public records agency, but most likely, you will have to face tables or lists that cannot be manipulated easily. It is a common practice to present data in HTML tables – for example, that’s how many government agencies send out reports. This is exactly why you need to do web scraping. Web scraping has been a part of computer science for years. It is a technology-intensive process and hence obviously demands technical knowledge.
It is a time-consuming process as well to create programs that can extract data from raw code and hence requires specialization. The only thing that could stop you from going ahead and creating a web scraping tool is the lack of programming skills. But you have hope, we will show you how to do web scraping without any programming skills at all. How about a user-friendly tool that doesn’t require you to be a programmer?
This is where OutWit Hub comes to our rescue. It is a Firefox add-on that you can download and install on your browser to give it data scraping capabilities. It lets you start extracting data from web pages with a few mouse clicks. OutWit Hub comes with a lot of recognition and extraction features that can get you the results you need out of the box. You can also customize it to meet your specific scraping needs.
How to use OutWit Hub to Extract Data
First, download the OutWit Hub add on from the Mozilla addons store and install it in your Firefox browser. You will have to restart your browser for the add-on to take effect. Once you start it up, you would see some simple scraping options in the left pane. These options are basic and can be used for tasks like extracting all the images from a web page or links on the page. If you need advanced scraping options, go to Automators>Scrapers section. The source code of the web page will be displayed. Look for the tagged attributes in the source code, you can use them as markers for particular elements that you might want to extract.
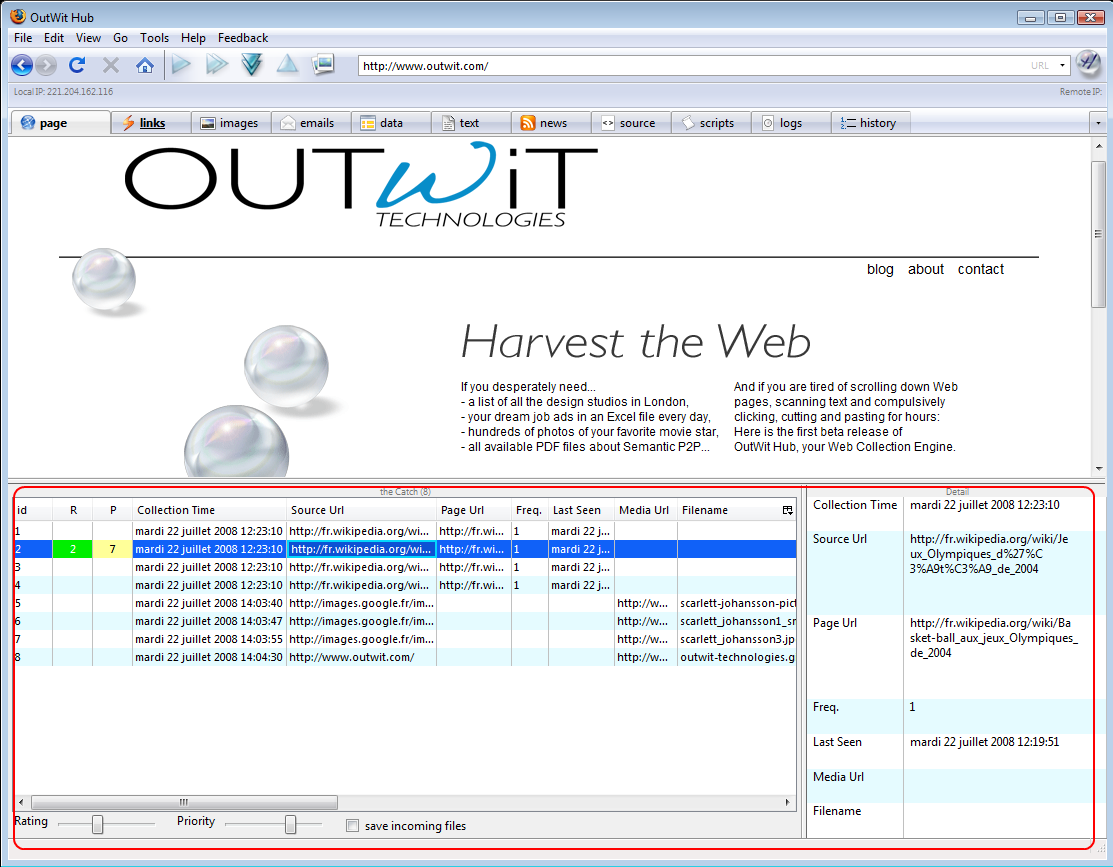
If you go through this code, you can find common patterns of information which you need to pull out from the page. Many pieces of text or characters will be apparent. Once you figure out the pattern used by the page, you can fill the ‘Marker before’ and ‘Marker after’ fields with relevant tags that enclose your required data. Now you can hit the ‘Execute’ button and sit back while OutWit Hub gets busy pulling your required data from the pages.
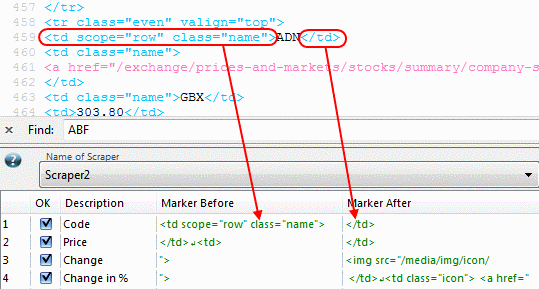
Confused? Here is an example. If you want to pull out all the text that is bold from a web page, you just have to use as your before marker and as your after marker. If you need data from an HTML table, use
and
. OutWit Hub lets you use multiple scrapers simultaneously, so you can extract many columns of data in minimal time.
You should also refer to the documentation section of OutWit Hub to find more specific tutorials that can make your data extraction process easier.
If you need to pull out more complicated data, it can also be done with OutWit Hub. For example, you might want to extract data from a series of similarly structured pages. To do this, you have to use the Format column under the scraper section to insert a ‘Regular expression’. This is how you can designate patterns. The process is quite easy and you can learn it quickly by tinkering around with the options.
OutWit hub is a really great tool to extract data without programming skills, but it isn’t the only option. For instance, if you want to extract data from Wikipedia into a Google spreadsheet, you can do that using the import HTML function of Google docs.
Although it’s a great tool to extract information from web pages with ease, it comes with its own limits. The truth is, using a programming language is the best option to crawl data from the web considering the flexibility it gives us. But if you are not into programming, it’s not a dead-end either. There are some great web scraping services that can cater to your scraping needs with professional accuracy. Depending on a service will also relieve you of the pain it takes to crawl, clean and classify the unstructured data from the web. This would mean you, as a business owner, can spend more of your valuable time analysing the data as opposed to first collecting and then analysing it.
When you grow outside OutWit Hub’s web scraping limitations, and you want to upgrade the whole process, it’s time to switch to a web scraping provider that fits your requirements. And, when you are on the quest for finding a suitable web crawling service, go through 7 things to keep in mind while choosing a web crawling service.















