



When I wrote my first machine learning algorithm, I used the mammoth data set collection hosted by UC Irvine to learn the ropes. There were so many datasets to practice with, 442 to be exact. But the problem is that these are datasets that have been used by loads of people all over the world, and almost all the findings that could be obtained from them, have already been published. Also, data science has progressed in many fields. There are infinite types of data sets that you might want to study. In that case, 442 is a minuscule, almost a drop in the ocean and so is google dataset search existing.
But then, whenever we need to search for something, we “Google” it, right? So if I needed a data set with details of cancer patients in a region, to find whether living in an urban area increases the chances of developing the deadly disease, I would most likely end up “Googling” it. However, what you need to understand is that Google works on the basis of word matching. It is more likely to fetch your articles with the words “Dataset of cancer patients” when you search for it than give you actual datasets. And this is the reason why Google has launched the Google dataset search beta on the 5th of September, this year.
So now, you can search for keywords, and find datasets associated with them. But what do you need to search with? We all know certain tricks and tips that work when searching on Google. Do any such rules apply when searching for a particular google? Yes indeed, according to Google, you will find it much easier to harvest datasets from the Google Search Engine, in case you provide information such as the name of the dataset, description, creator-info, and the format (CSV, JSON, etc). Even datasets in markup languages can be discovered with the help of the all-new search engine.
For people who want Google to locate datasets in their websites and show them to users, Google says that although the feature is in the pilot, things are taking pace, and you can start adding dataset by adding structured data to your website, and they will eventually come up in the search engine when people search with relevant terms.
Why did Google build this now?
Well, there are thousands of repositories containing data on the web and they in turn provide access to millions of datasets. These datasets can belong to National, International, or regional Governments, Non-Profit Organizations, or even companies that want to engage the public in dealing with their datasets. A huge quantity of datasets is publicly held by research organizations and colleges of higher education. Access to all these datasets is critical, so as to facilitate the easy flow of information. A dataset trapped under a thousand dollar fees might as well be beyond the reach of many researchers who could have made some sense from the data.
But the problem lies with the volume. With so much data on the internet, it can prove to be very difficult to find a particular dataset, even if you can narrow it down to a category, subcategory, region, and more. You can specify, whether you are looking for data on diseases, movies, plants, animals, calamities, UFO sighting, and more. And theoretically speaking, you should be able to find these easily. But it is no so at present.
Google is solving the problem by allowing people to attach some metadata in a particular format that will be governed by some standards, so as to help Google track the datasets more easily. These metadata would be helping Google make datasets easily accessible to the public.
Why is the program still in Beta?
While most of the technical issues have been addressed, the main challenges are some questions that remain unanswered. Some of these questions are – What is the universal definition of a dataset? Can a single table be called a dataset? What about a collection of tables? A folder of images? How do you say that the images in the folder are related? Or the tables found together are related? What about an API that gives a dataset? Is it possible to relate similar datasets using certain parameters?
The problem is that datasets have been built across a long time, and they are stored in many different formats, and there is no way to find a primary data or metadata, or tag by which they can be immediately identified from the depths of the internet and this is what Google is trying to work on. So what they are recommending is for people who are uploading data, to follow proper conventions, and those using the data, in research, to provide proper citations. After all, Google is just a search engine. It shows us pre-existing data. It can not find something that is not in a state to be found. Unless people start handling data responsibly, by storing it in recommended formats and adding metadata, and citations, things will only get worse as more and more data sets get added to the web, every single day.
Well, how to use google dataset search?
You can search for various types of datasets. And according to Google, a dataset can be any of the following-
- A collection of interrelated tables bunched together
- Data in CSV or Table format
- A set of images or videos
- Any proprietary formatted file that contains data
- Collection of files that together make up a dataset of some form
- An object like a JSON, that can be processed to build up a dataset.
- Binary models such as those produced by Tensorflow
- Anything that even looks like a dataset to naked eyes.
This is what the search engine looks like and you can go on and search something just like you normally would on Google web search:
 So when I searched for a housing dataset, I met this result:
So when I searched for a housing dataset, I met this result:
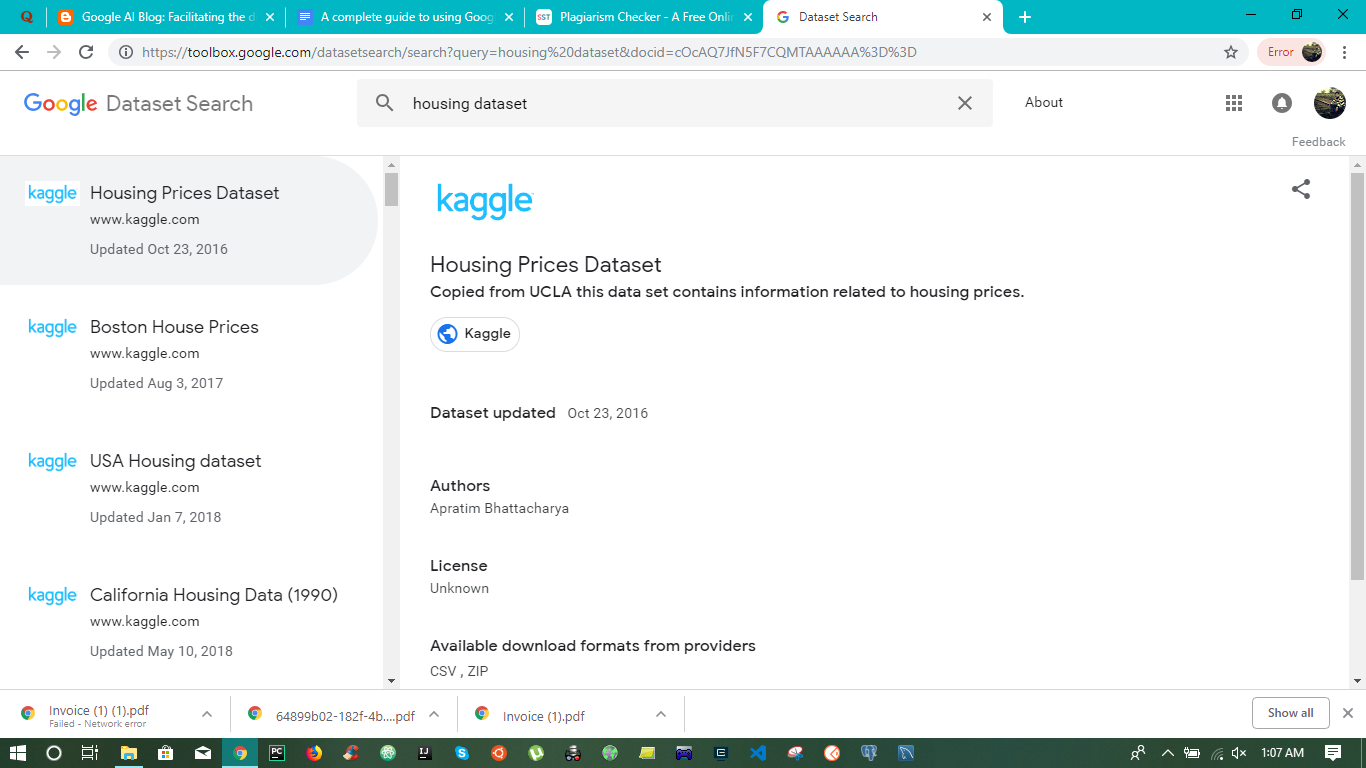
You can see that Google is trying to show the most relevant and popular datasets related to only two words that I have entered, and in this scenario, Kaggle has many housing datasets that have been used by thousands of users, and hence these come at the top.
Next, I searched for something a bit more specific. And got the following result:
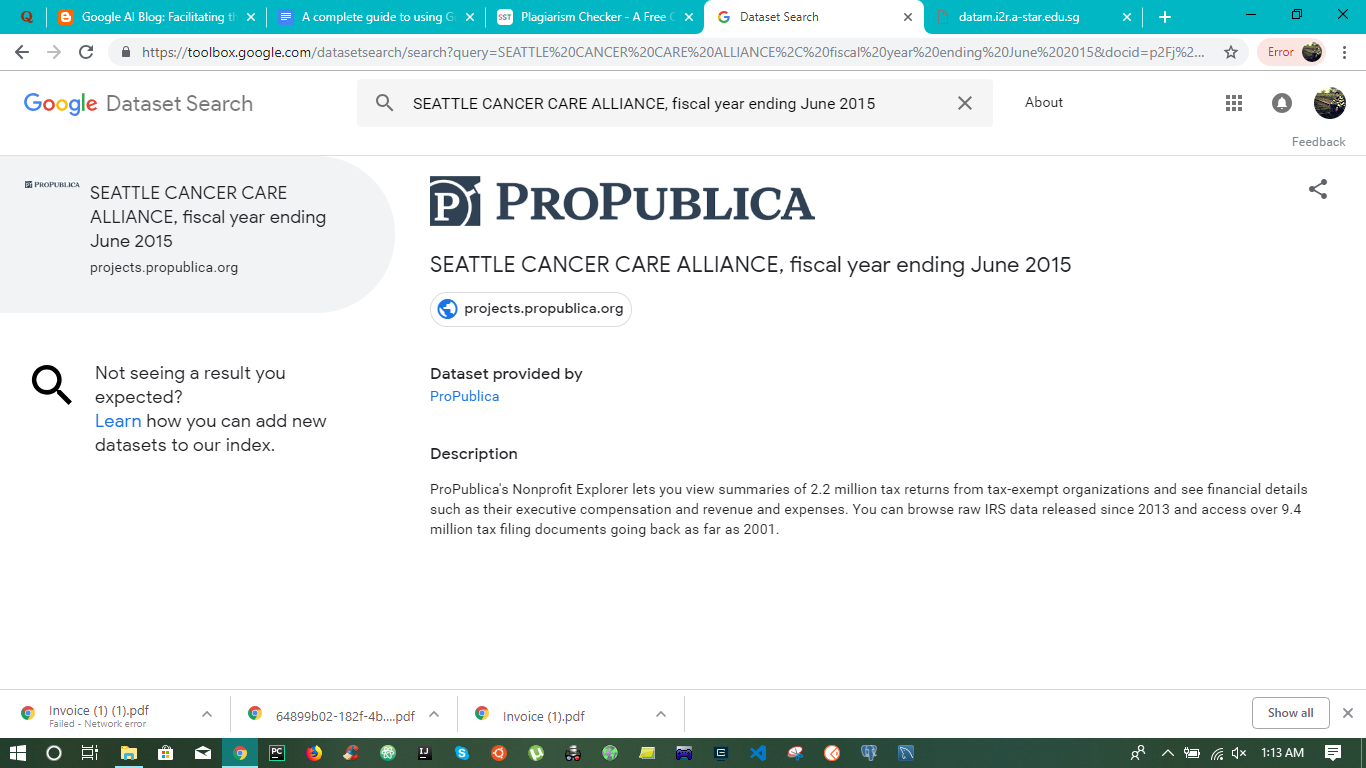
This time, you can see that since I searched for something specific, Google was able to pinpoint the resource to me, thus helping me scale up my work faster. Google is also providing some basic descriptions and links for me to understand more about the dataset that I want to work with.
Such a service is a godsend, and I wish this was available when I started learning data science. I would recommend you to go on and search for datasets, on Google, and try to give as much information about the dataset that you are trying to search, so as to find the best-fit dataset for your project, study, or research. Meanwhile, if the data you need isn’t available in a ready-to-use format on the web already, you can always reach out to us to set up a custom crawl.
Looking for a web scraping service to extract data for you contact PromptCloud















