




Web scraping Amazon requires careful attention to detail and compliance with their terms of service. Python, with its powerful libraries like BeautifulSoup, Requests, and Scrapy, makes it feasible to extract product data quickly and efficiently. Users must handle HTTP requests, parse HTML documents, and handle JavaScript rendering where necessary.
Employing practices such as setting up proxies, using proper headers, and managing cookies ensures seamless interaction with Amazon’s servers. It’s imperative to implement rate limiting to avoid IP bans. Data obtained can include product titles, prices, reviews, and ratings, which are useful for market analysis and competitive intelligence.
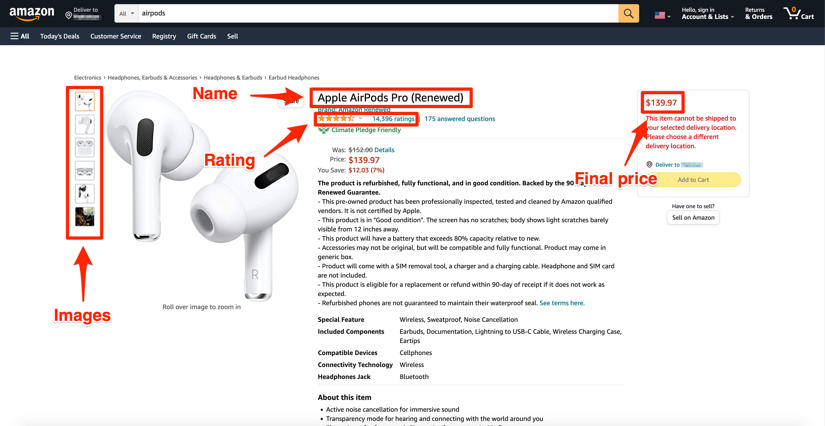
Image Source: ScrapingBee
What is Price Tracking and its Importance?
Price tracking refers to the continuous monitoring of product prices over time to identify trends, fluctuations, and patterns. It is critical for consumers and businesses alike because it aids in making informed purchasing and pricing decisions. For consumers, it can highlight the best times to buy, potentially leading to significant savings.
For businesses, it ensures competitive pricing strategies to attract and retain customers. Price scraping also provides invaluable data for market analysis, revealing insights into consumer behavior and market dynamics, thus enhancing overall financial planning and strategy development efforts.
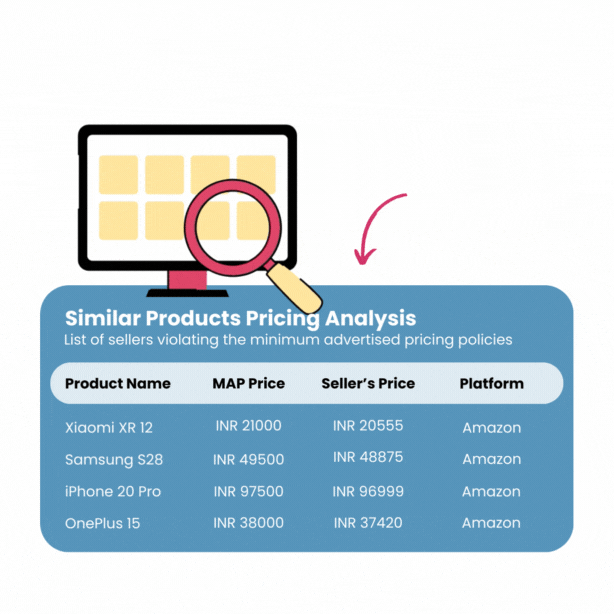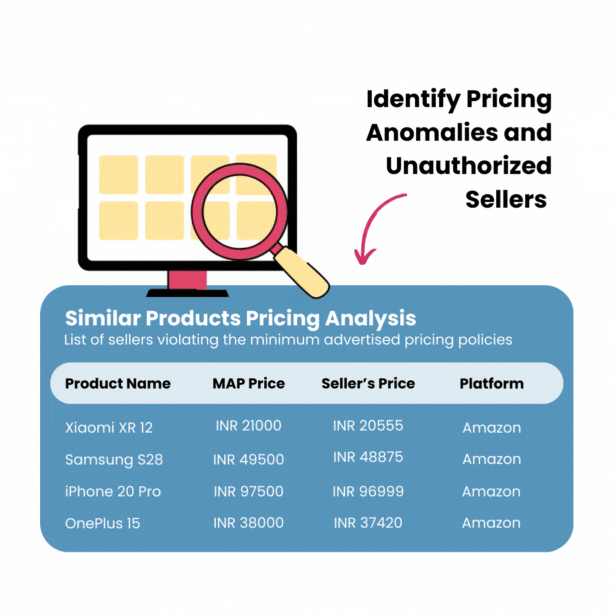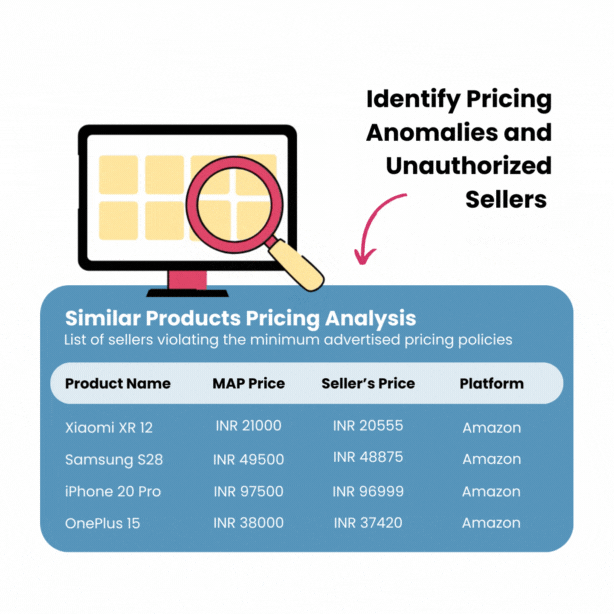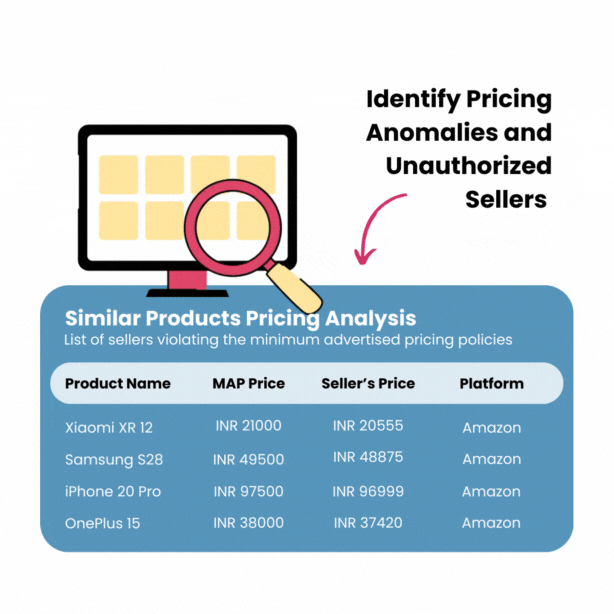
Image Source: 42Signals
Why Should You Scrape Amazon?
Web scraping Amazon is crucial for businesses and researchers aiming to gain a competitive edge through data-driven insights. By extracting detailed product information, user reviews, and pricing data, one can conduct comprehensive market analysis, monitor competitors, and optimize product listings.
Businesses can leverage this information to identify trends, adjust pricing strategies, and improve customer engagement. Researchers can analyze user sentiment and purchasing behavior. This ability to efficiently gather and analyze data directly from one of the largest e-commerce platforms ensures that stakeholders make informed, strategic decisions that enhance performance and drive growth.
- Set Up Python Environment for Web scraping Amazon
To begin, install Python from the official website, ensuring that you add Python to your environment variables during installation. Open a command prompt and run pip install requests to install the Requests library, followed by pip install beautifulsoup4 to install BeautifulSoup for parsing HTML. Consider using a virtual environment to manage dependencies effectively.
Create a new project directory and set up a virtual environment using python -m venv venv, then activate it (.venvScriptsactivate on Windows or source venv/bin/activate on macOS/Linux). Use a text editor or an IDE like VSCode to streamline development.
- Must-Have Python Libraries
Web scraping Amazon data with Python necessitates several critical libraries, each serving a distinct purpose. The requests library efficiently manages HTTP requests, enabling smooth communication with Amazon’s servers. For parsing the retrieved HTML content, the BeautifulSoup library is indispensable due to its ease of use and HTML parsing accuracy.
To handle dynamically loaded data via JavaScript, the Selenium WebDriver is recommended. Additionally, using pandas facilitates data manipulation and storage, transforming raw data into a structured format. Lastly, time is essential for managing delays to mimic human browsing behavior, reducing the risk of being blocked.















