



Why Python Dominates Web Scraping in 2026?
Web scraping with Python is one of the most practical and in-demand technical skills in 2026. Whether you are building a competitive intelligence dashboard, collecting AI training data, monitoring prices, or aggregating market signals, Python provides the most mature and versatile ecosystem for extracting structured data from the web.
The challenge has grown significantly since earlier tutorials were written. Traditional methods that worked reliably on the static web of 2016 frequently fail on modern targets. Over 98.9% of commercial websites now use JavaScript to load or modify content, aggressive anti-bot systems including Cloudflare, DataDome, and PerimeterX analyse browser fingerprints and TLS signatures before your HTTP headers even arrive, and the compliance requirements of GDPR and the EU AI Act have added new obligations around what data can be collected and how. Projects in 2026 require more than Requests and Beautiful Soup.
This guide covers why Python is the right language, how to select the correct tool for different page types, the four-stage pipeline that every scraper follows, working code examples for static and dynamic pages, the failure modes that kill production scrapers, best practices, and the honest point at which maintaining Python scrapers yourself stops making sense.
All code examples use Python 3.10 or above. Deprecated libraries from earlier guides, including urllib2, are not covered.
Python’s position as the default language for web scraping python projects is not accidental. It combines a syntax gentle enough for beginners with an ecosystem powerful enough for production-grade pipelines. The same language that lets you scrape a single static page in ten lines of code also powers distributed crawlers processing millions of pages, ML pipelines consuming scraped training data, and agentic systems that navigate the web autonomously.
The library ecosystem is the core advantage. No other language matches the combination of Requests for HTTP, Beautiful Soup and parsel for parsing, Playwright for browser automation, Scrapy for large-scale crawling, pandas for data processing, and an active community continuously updating these tools as the web evolves. Over 80% of enterprise-level AI pipelines rely on real-time data scraped from the live web. When a new anti-bot system emerges or a new browser automation approach becomes necessary, the Python scraping community produces the first production-ready library to address it.
Python also benefits from AI-assisted development. Modern coding assistants generate scraping scripts with high accuracy, and in 2026, self-healing scrapers that use AI models to detect selector changes and update themselves are an emerging capability.
Tired of Python scrapers that break every time a target site updates its layout?
Get clean, structured web data delivered on your cadence from a managed pipeline built around your specific sources and schema.
• No contracts. • No credit card required. • No scrapers to babysit.
Choosing the Right Python Web Scraping Tool
The single most important decision is choosing the right tool for the page type. Using a headless browser on a static page wastes compute; Requests on a JavaScript-rendered page returns empty containers. Determine whether your target is static or dynamic before writing any code.
To check: open the target page in your browser, right-click, and select View Page Source. If the data you need is visible in the raw HTML, the page is static and Requests plus Beautiful Soup is the right starting point. If the source shows mostly empty div containers, the page is dynamic and requires a headless browser. Understanding the relevant terms for each tool and approach is covered in the PromptCloud web scraping glossary, which defines the key concepts from HTTP and HTML through to proxy rotation and headless browsers.
- Use Requests and Beautiful Soup when the data you need is present in the raw HTML source. This combination handles the majority of static websites and is the correct starting point for learning web scraping python fundamentals. Fast to set up, easy to debug, low resource overhead.
- Use Playwright when a standard HTTP request does not return the data you see in the browser. This covers JavaScript-rendered content, single-page applications, sites that require interaction such as button clicks or scroll events, and pages with authentication flows. Playwright is the modern choice in 2026, replacing Selenium for most new projects due to its cleaner API, async support, and better performance.
- Use Scrapy when the task requires following links across many pages, managing a crawl queue, handling retries and rate limiting automatically, and exporting data at scale. Scrapy is a full framework rather than a single library and has a steeper initial learning curve, but it provides the infrastructure for production crawl jobs that Requests alone cannot.
- Use httpx and parsel when you need async concurrency for high-volume static extraction without the overhead of Scrapy’s full framework. httpx is a modern async replacement for Requests; parsel provides Scrapy-style CSS and XPath selectors without requiring the full Scrapy framework.
- Use curl_cffi when standard Requests is blocked by TLS fingerprinting. Python’s requests library creates a TLS ClientHello fingerprint that is trivially identified as non-browser traffic by Cloudflare and similar systems. curl_cffi impersonates real browser TLS signatures and resolves the most common category of silent block.
How Web Scraping with Python Works: The Four-Stage Pipeline
Every web scraping python project, from a ten-line script to a distributed crawler, follows the same four-stage pipeline. Understanding each stage clearly prevents the most common debugging mistake: diagnosing the wrong layer when something goes wrong.
Stage 1: Fetch
The scraper sends an HTTP request to the target URL and receives the server’s response. For static pages, Requests handles this in two lines. For dynamic pages, Playwright launches a headless browser, navigates to the URL, executes the JavaScript, and waits for the content to fully render before passing the HTML forward. The most important practical detail at this stage is the User-Agent header. Sending requests without a realistic User-Agent, or with Python’s default string, is a clear bot signal on most commercial sites.
Stage 2: Parse
The HTML response is parsed into a navigable structure. Beautiful Soup converts it into a tree of Python objects. Parsel provides the same capability with CSS and XPath selectors. lxml is faster for large pages. Parser choice affects performance at scale but not extraction logic.
Stage 3: Extract
CSS selectors or XPath expressions locate the specific elements containing the data you need. CSS selectors are the standard for most web scraping python projects because they are concise, readable, and directly map to the selectors you see in browser DevTools. To find the right selector: open the target page, right-click the element containing your data, and inspect it. The class names, IDs, and data attributes on that element are what your selector targets. Prefer stable attributes like data-testid or semantic IDs over auto-generated class names that change with CSS-in-JS framework deployments.
Stage 4: Store
The extracted values are cleaned, typed, and written to their destination. CSV for flat tabular data that will be analysed in pandas or a spreadsheet. JSON for hierarchical or nested structures. A relational database for queryable structured data that will power an application. Cloud storage for large-volume datasets feeding downstream analytics or AI pipelines. Always include a validation step before writing: check that expected fields are present and that numeric fields actually contain numbers before the data reaches any downstream system.
Working Python Web Scraper: Code Examples
Static page: Requests and Beautiful Soup
Install the two libraries if you have not already:
pip install requests beautifulsoup4
Fetch a page and extract all heading text:
import requestsfrom bs4 import BeautifulSoupheaders = { “User-Agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36”}url = “https://quotes.toscrape.com/”response = requests.get(url, headers=headers)response.raise_for_status()soup = BeautifulSoup(response.content, “html.parser”)quotes = soup.select(“span.text”)for quote in quotes: print(quote.get_text(strip=True))
The raise_for_status() call converts HTTP error codes into Python exceptions, so your script fails loudly on a bad response rather than silently processing an error page as if it were real data.
Dynamic page: Playwright
Install Playwright and its browser dependencies:
pip install playwrightpython -m playwright install chromium
Scrape a JavaScript-rendered price field:
from playwright.sync_api import sync_playwrightwith sync_playwright() as p: browser = p.chromium.launch(headless=True) page = browser.new_page() page.goto(“https://example-shop.com/product/123”) page.wait_for_selector(“[data-testid=’product-price’]”) price = page.locator(“[data-testid=’product-price’]”).inner_text() print(price) browser.close()
The wait_for_selector() call is critical. It tells Playwright to pause until the price element appears in the DOM, preventing extraction of an empty value from a page that has not yet finished loading.
Storing output to CSV
import csvrows = [{“title”: “Example”, “price”: “29.99”}]with open(“output.csv”, “w”, newline=””, encoding=”utf-8″) as f: writer = csv.DictWriter(f, fieldnames=[“title”, “price”]) writer.writeheader() writer.writerows(rows)
Python Web Scraping Tools Compared
The table below maps the five main Python scraping tools across the dimensions that determine which is appropriate for your project. Match the tool to your actual page type and scale requirements, not to the most impressive feature list.
| Tool | Type | JavaScript | Best For | Learning Curve |
| Requests + Beautiful Soup | HTTP + parser | No — static HTML only | Static pages; learning fundamentals; quick extractions | Low |
| Playwright | Browser automation | Yes — full JS rendering | Dynamic pages; SPAs; JavaScript-heavy sites | Medium |
| Scrapy | Full framework | Not native — middleware available | Large-scale crawls; many pages; built-in pipelines | Medium-High |
| httpx + parsel | Async HTTP + parser | No — static only | High-concurrency static extraction; faster than Requests | Low-Medium |
| curl_cffi | TLS-fingerprint HTTP | No — static only | Sites blocking standard requests by TLS signature | Medium |
One dimension the table cannot capture is the 2026 anti-bot landscape. Playwright is the most capable browser automation tool but is also the most commonly detected by anti-bot systems, which look for headless browser fingerprints. When Playwright is blocked, the solution is usually either rotating residential proxies, using Playwright’s stealth mode patches to mask headless indicators, or switching to a managed scraping API that handles detection evasion as a service.
Handling Anti-Bot Systems: The Failure Modes That Kill Production Scrapers
Most Python scraping guides stop after the code works in development. The section that gets skipped is the one that explains why the same code fails in production on real targets. Anti-bot systems operate in layers, and understanding each layer is what separates a scraper that runs reliably from one that fails silently.
TLS fingerprinting
Python’s requests library creates a TLS ClientHello fingerprint that anti-bot platforms identify as non-browser traffic before reading a single HTTP header. The fix is curl_cffi, which impersonates real browser TLS signatures. This is the most commonly missed fix in 2026 and the reason many scrapers fail on Cloudflare-protected sites without any visible error, simply receiving a challenge page that extracts as empty fields.
User-Agent and header analysis
Sending requests with Python’s default User-Agent is a reliable bot signal. Set a realistic browser User-Agent string and include the standard browser headers that accompany it: Accept, Accept-Language, Accept-Encoding, and Referer where appropriate. Header order also matters on some detection systems: browsers send headers in a specific order that Python’s requests library does not replicate by default.
IP reputation and rate limiting
Making too many requests too quickly from a single IP triggers rate limits and blocks on any commercially significant scraping target. Add random delays between requests using time.sleep() with a randomised interval. For targets with aggressive rate limiting, residential proxy rotation distributes requests across many IP addresses. Datacenter proxies are cheaper but are more easily identified; residential proxies are more expensive but substantially harder to detect.
JavaScript challenges and CAPTCHAs
Sites using Cloudflare’s JavaScript challenge or Google reCAPTCHA cannot be scraped with standard HTTP requests. Playwright or a similar headless browser must render the challenge and, for reCAPTCHA, a CAPTCHA-solving service is required. The most sustainable approach for commercially important sources that deploy aggressive protection is to use a managed scraping API that handles challenge solving as part of the service, rather than maintaining your own CAPTCHA infrastructure.
Schema drift and selector breakage
Websites update layouts and change class names without notice. CSS selectors that worked last month break silently when a site redesigns. Prefer stable selectors: data-testid attributes, semantic IDs, and ARIA labels. Monitor for output volume drops and empty fields so you learn about breakage before a downstream system does.
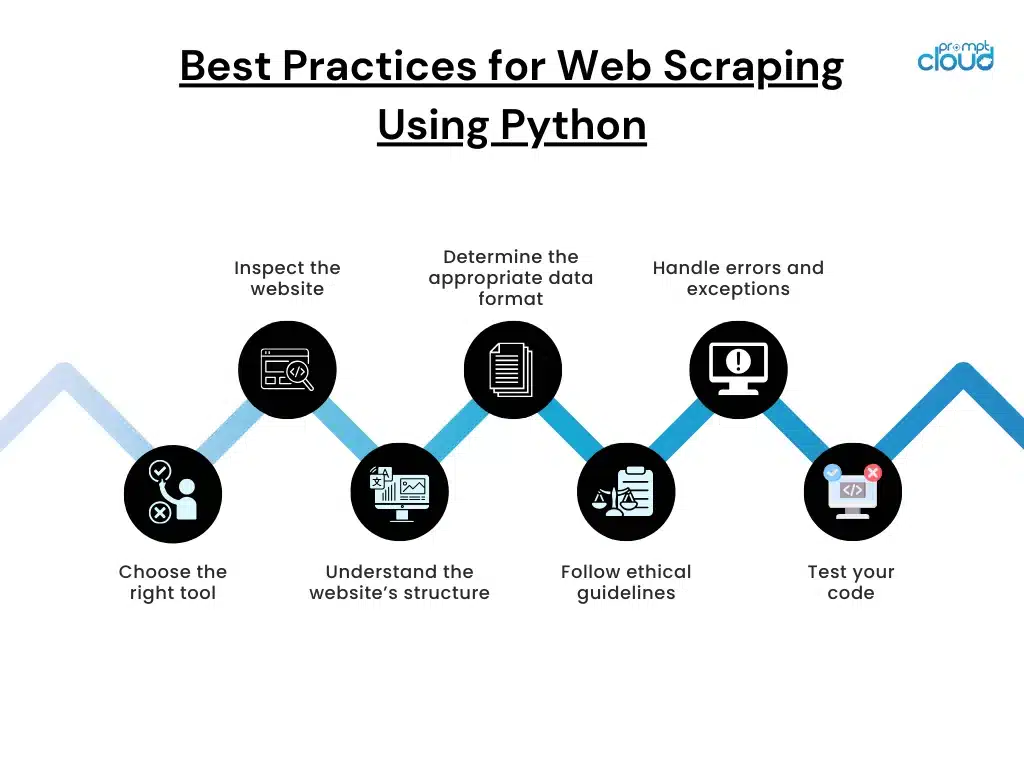
Best Practices for Web Scraping with Python
Always check robots.txt first
The robots.txt file at a domain’s root communicates which paths automated bots are permitted to access and may set crawl rate limits. Check it before configuring any scraper. Paths marked as Disallow should not be scraped. Many sites have added AI-specific directives in 2025 and 2026 that distinguish training crawlers from general bots.
Rate limit every scraper by default
A scraper with no delays between requests will get blocked and may degrade performance for legitimate users of the target site. Add a minimum delay between consecutive requests, randomise the interval within a reasonable range, and limit concurrent connections. A polite scraper stays active on important sources much longer than an aggressive one.
Validate output on every run
Every production scraper run should check that expected fields are present, numeric fields contain numbers, and delivery volume is within expected bounds before writing data anywhere. A site that returns an HTTP 200 status with a challenge page rather than real content will not throw an exception: it will extract empty strings silently. Output-level validation catches these failures.
Version control extraction logic
Scraping scripts and selector definitions should be in version control. When a source changes and selectors need updating, history is essential for diagnosing whether a data quality issue predates the change or was introduced by it.
Store raw HTML alongside structured output
For scraping projects that will run over months or years, storing the raw HTML at extraction time means you can reparse it later if your extraction logic changes, without having to re-request pages. This is particularly valuable for sources that update content frequently or for historical analysis.
When Python Web Scraping Stops Being the Right Answer
Web scraping python is the right starting point for most data collection projects. It becomes the wrong answer when the maintenance burden of keeping scrapers running starts consuming more engineering time than the data is worth.
The inflection point is well-defined. Each target source requires roughly two hours of maintenance per month. At five sources that is manageable; at thirty sources that is sixty hours per month, equivalent to one and a half engineers doing nothing but keeping scrapers alive.
Other signals that the maintenance overhead has crossed the line: your team is responding to scraper failures reactively rather than proactively, downstream systems are occasionally receiving corrupted data because breakages go undetected, and new source requests are being deprioritised because the existing source maintenance backlog is already full.
When these signals appear, the question is not whether to keep using Python: it is whether to continue operating the infrastructure yourself or transfer that operational burden to a provider. The honest evaluation of this decision, including the cost comparison and the criteria for making it, is covered at , which walks through the build-versus-buy decision with the numbers.PromptCloud’s guide to stop maintaining scrapers
Ready to Scale Beyond What Python Scrapers Can Sustain?
Python web scraping is the right architecture for learning and lower-scale projects. When you need continuously maintained, production-grade data pipelines across many complex sources, managed web scraping services remove the infrastructure burden your team currently absorbs.
How PromptCloud Handles What Python Scrapers Cannot Sustainably Do
PromptCloud is a fully managed web scraping service for enterprises that have hit the inflection point where operating Python scraping infrastructure themselves has become more expensive than outsourcing it. The model is end-to-end: PromptCloud builds custom extraction pipelines for each client’s specific sources and schema, manages anti-bot infrastructure, handles JavaScript rendering, validates every delivery, and repairs breakages when target sites change. The client defines what data they need; PromptCloud handles everything between that specification and the delivered dataset.
The most significant operational difference from a self-managed Python scraping setup is where the maintenance burden sits. When a target site updates its page structure at midnight and breaks a CSS selector, PromptCloud’s engineering team detects the failure and repairs the extractor before the next scheduled delivery. The client does not discover the site change from missing fields in their dashboard or corrupted data in their pricing engine.
For pricing intelligence applications specifically, the accuracy and freshness of scraped data determines whether the pricing model can make reliable adjustments. A Python scraper that occasionally misses pages due to rate limiting or silently returns empty fields when anti-bot systems update is a pipeline that introduces systematic errors into decisions. PromptCloud’s QA layer, combining automated schema validation and human review, catches the failures that monitoring alone consistently misses.
Enterprises that built their own Python web scraping infrastructure consistently describe the same pattern: the first build took weeks, the first production deployment surfaced edge cases that took months to resolve, and the ongoing maintenance of keeping extractors current consumed engineering capacity that the team needed for higher-value analytical work. PromptCloud removes that entire maintenance layer, allowing teams to focus on using data rather than collecting it.
Web Scraping with Python in 2026: Start Simple, Scale Intelligently
Python scraping is more capable and more necessary in 2026 than at any earlier point. The combination of Requests and Beautiful Soup handles the majority of static targets in a handful of lines. Playwright handles the JavaScript-rendered sites that now make up the majority of commercial targets. Scrapy handles large-scale crawls. curl_cffi handles the TLS fingerprinting that silently blocks standard requests on protected sites.
Start with the simplest tool that solves the problem. Requests and Beautiful Soup for static pages. Playwright when JavaScript is involved. Scrapy for multi-page crawls. Reach for more sophisticated infrastructure when scraper maintenance is displacing the analytical work the data is supposed to enable.
If your operation has reached that point, PromptCloud offers a structured pilot on your real sources before any full engagement. The scope, delivery quality, and cost profile of a managed pipeline become clear within the pilot, which is the most useful first step in evaluating whether a managed service is the right next architecture for your specific data collection operation.
Tired of Python scrapers that break every time a target site updates its layout?
Get clean, structured web data delivered on your cadence from a managed pipeline built around your specific sources and schema.
• No contracts. • No credit card required. • No scrapers to babysit.
Frequently Asked Questions
What is web scraping with Python?
Web scraping with Python is the automated extraction of data from websites using Python libraries. A Python web scraper sends HTTP requests to target URLs, receives the HTML response, parses it using a library like Beautiful Soup to locate specific data elements, and saves the extracted values to a structured format such as CSV, JSON, or a database. Python is the dominant language for web scraping because of its clean syntax, extensive library ecosystem, and active community that continuously updates scraping tools as the web evolves.
What Python libraries are used for web scraping?
The main Python libraries for web scraping are: Requests for sending HTTP requests to fetch static pages; Beautiful Soup for parsing HTML and extracting data using CSS selectors and tag navigation; Playwright for rendering JavaScript-heavy pages through a headless browser; Scrapy as a full crawl-and-extract framework for large-scale pipelines; httpx for async HTTP requests at high concurrency; parsel for Scrapy-style CSS and XPath selectors without the full framework; and curl_cffi for impersonating real browser TLS signatures when standard Requests is blocked by anti-bot systems.
How do I scrape a JavaScript website with Python?
To scrape a JavaScript-rendered website with Python, use Playwright. Standard HTTP libraries like Requests fetch only the initial HTML shell of dynamic pages, which does not include content loaded by JavaScript after the page renders. Playwright launches a headless Chromium, Firefox, or WebKit browser, navigates to the URL, executes the JavaScript, and waits for the target content to appear in the DOM before you extract it. Install Playwright with pip install playwright followed by python -m playwright install chromium, then use the sync or async Playwright API to fetch and parse the rendered page.
Is web scraping with Python legal?
Web scraping publicly accessible data with Python is generally legal in most jurisdictions. The HiQ Labs v. LinkedIn ruling established in the United States that automated access to publicly available web data does not violate computer access laws. However, scraping becomes legally risky when it violates a site’s terms of service in ways that cause measurable harm, collects personally identifiable information without a GDPR or CCPA lawful basis, circumvents technical access controls, or collects data for AI training without meeting the documentation requirements of the EU AI Act. Checking a site’s robots.txt file and reviewing its terms of service before building a large-scale scraper is standard practice.
How do I avoid getting blocked when scraping with Python?
Avoiding blocks when web scraping with Python requires several measures: set a realistic browser User-Agent header and include standard browser headers in every request; add random delays between requests to avoid triggering rate-based detection; use rotating residential proxies to avoid IP-based blocking; use curl_cffi instead of requests on sites blocked by TLS fingerprinting; use Playwright with stealth patches on sites that detect headless browsers; and monitor your scraper output for silent blocks, where the site returns HTTP 200 but serves a challenge page with empty data fields rather than a hard error.
What is the difference between Beautiful Soup and Scrapy for Python web scraping?
Beautiful Soup is a parsing library that extracts data from HTML you have already fetched. It has no built-in request management, link following, or retry logic: you provide the HTML, it provides the tree navigation. Scrapy is a full web crawling and scraping framework that manages the entire pipeline: it sends requests, follows links, handles retries and rate limiting, extracts data using CSS or XPath selectors, and exports results to CSV, JSON, or databases. Beautiful Soup is the right choice for extracting data from a defined set of pages. Scrapy is the right choice when the project involves crawling many pages across a site or multiple sites and you need a robust, production-ready pipeline.
How do I handle pagination in Python web scraping?
Handle pagination in Python web scraping by locating the next-page link or URL pattern on each page and continuing the fetch-parse-extract cycle until no next page is found. For URL-based pagination where pages follow a predictable pattern such as ?page=1, ?page=2, construct the URLs directly in a loop. For HTML-based pagination where the next page URL is in a link element, parse it from the page with Beautiful Soup using soup.select_one(‘a.next-page’) or equivalent, then follow it. For infinite-scroll pages, check the browser’s Network tab while scrolling: most infinite-scroll sites make background API requests that return JSON, which is simpler to call directly with Requests than to simulate with a headless browser.
How do I store scraped data from Python to CSV?
Store scraped data from Python to CSV using Python’s built-in csv module or pandas. With csv: open a file in write mode, create a DictWriter with your field names, call writeheader(), then writerows() with a list of dictionaries where each key is a column name. With pandas: collect your extracted values into a list of dictionaries, create a DataFrame with pd.DataFrame(rows), then call df.to_csv(‘output.csv’, index=False). Pandas is preferable when you also want to clean, filter, or analyse the data before saving. The csv module is preferable for simple outputs with minimal dependencies.
Can I use Python web scraping for AI training data?
Yes. Python web scraping is the primary mechanism for building AI training datasets at scale. Over 80% of enterprise AI pipelines rely on real-time data scraped from the live web. For domain-specific language model training, targeted Python scrapers collect specialised corpora from industry publications, regulatory databases, and technical sources. For retrieval-augmented generation systems, Python scrapers continuously refresh the external knowledge base the model queries at inference time. The EU AI Act, in force from August 2026, creates new documentation requirements for AI training data collected through web scraping: provenance records, access basis documentation, and transparency about collection methods are now regulatory obligations for AI systems deployed in European markets.
When should I use a managed scraping service instead of Python?
Use a managed scraping service instead of building and maintaining Python scrapers when the maintenance overhead of keeping your scrapers current exceeds the engineering capacity you can sustainably allocate to it. The inflection point is typically around 20 to 30 active sources at production volume: below that, a well-maintained Python scraping setup is cost-effective; above it, the time spent responding to site changes, updating selectors, managing anti-bot infrastructure, and repairing broken pipelines consistently exceeds the cost of a managed service contract. Other signals: downstream systems are receiving corrupted data due to undetected scraper failures, and new source requests are being deprioritised because the existing maintenance backlog is already consuming too much team time.















