




The leading real estate sites of the world are a treasure trove of valuable data. The database of any popular US real estate site might contain information on more than 100M homes. These homes include the ones for sale, rent, or even ones not currently in the market. Scraping real estate data (with a Zillow web scraper) provides data for rent and property estimates called “Zestimates” as well. It helps owners, as well as customers, plan better by trying to estimate the prices of properties in the upcoming years.
When it comes to buying or renting properties, we know that the first thing that comes to one’s mind is price comparison. These sites for housing provide price comparison with all listings in that area, as well as basic information like the type of house, number of rooms, the size, a short description, etc..
Why Zillow.com Is a Goldmine for Real Estate Data
If you’re a real estate analyst or investment firm, you already know that Zillow isn’t just a listings site. It’s a real estate data ecosystem.
According to Zillow’s own data, they receive over 200 million unique monthly visits, making them one of the most visited real estate platforms in the U.S. Their public listings include everything from active sales and rentals to off-market properties and foreclosure data.
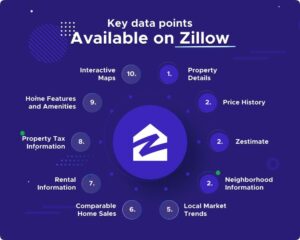
Image Source: Crawlbase
But what makes Zillow truly valuable is the depth of property-level insights available:
- Historical pricing trends
- Time on market
- Zestimate (Zillow’s estimated market value)
- Owner and tax records
- Rental income potential
- Property photos, amenities, and neighborhood stats
If you’re an investor building a buy-and-hold model or a PropTech platform benchmarking rent estimates, this kind of data is essential. But clicking through hundreds of listings to gather this info manually? That’s a recipe for burnout—and bad data.
Why Manual Zillow Data Collection Just Doesn’t Cut It Anymore
If you’ve ever tried collecting property data manually from Zillow.com, you already know how frustrating and, frankly, exhausting it can be.
At first, collating property data looks simple. You open Zillow, enter a city or zip code, scan the listings, and record price, square footage, bedroom count, and even a rental estimate in a spreadsheet. Repeat that for every entry, and the job seems manageable.
Now, try doing the same with several hundred or even thousands of listings.
Before long, you are drowning in open browser tabs, losing sight of which homes you have already recorded, and your sheet is littered with missing entries, accidental duplicates, and spelling errors. To make matters worse, by the time you finish, much of the information may already be stale.
And that’s really the core issue here: real estate data is time-sensitive.
Prices change. Listings get pulled. Properties go under contract. New ones hit the market. If you’re still collecting this information by hand, you’re always behind the curve. And that can be the difference between spotting a hot opportunity and missing it entirely.

Let’s break it down further:
- It’s painfully slow. Manually scraping even 200 listings could take you hours. Now imagine doing that daily, or across 10 cities.
- There’s no consistency. You might grab the price on one listing and forget it on the next. Or copy the rent estimate, but skip the square footage. Over time, your dataset becomes patchy and unreliable.
- Mistakes creep in. One copy-paste error or misread number, and your entire model can go off. That’s a serious risk for analysts or firms making data-driven decisions.
- It doesn’t scale. The moment you want to track trends across multiple markets or automate any part of your workflow, the manual collection becomes a wall you keep running into.
The reality is this: Zillow is built for human browsing, not bulk data collection. It’s a fantastic site for consumers, but for professionals who need structured data at scale, it’s just not practical to go the manual route.
And this is exactly why real estate firms, investment analysts, and PropTech startups are turning to a Zillow web scraper.
Why Crawl Data from Real Estate Sites?
The large property listing companies target an entire region and work on millions of properties. But in case you are a real estate agent, instead of trying to gather data manually by yourself, you can better crawl data from a major real estate listing website.
You can also build Machine Learning models to predict the prices of properties and compare your predictions with Zillow™’s Zestimates™ and see which one is better or closer to actual values.
How to Scrape Real Estate Data Using Python?
In case you have followed any of our previous “How to crawl or scape” articles, you might already have the necessary setup ready on your computers. In case you have not, I recommend you to follow this article to set up data scraping python, its packages, and the text editor before you can get your hands dirty with the code.
What Is a Zillow Data Scraper and How It Works
A Zillow web scraper is just a script or tool that pulls property info from Zillow.com for you—automatically. No clicking through listings, no copy-pasting into spreadsheets. It does all that in the background.
You toss in an address, set a rough budget, and the tool pulls in everything: asking price, bedrooms, square feet, Zestimate, possible rent, and a few extra notes. In seconds, it spits out a tidy spreadsheet you can sort, edit, and use for the next step.
It works like this:
- It opens Zillow pages (not in a browser, but behind the scenes).
- It reads the listing info—like a person would—but at machine speed.
- Then it saves the data in a format like CSV, Excel, or JSON.
You can write one yourself using Python. People use tools like BeautifulSoup, Scrapy, or Selenium for that. Or you can skip the coding and use a website data scraping service like PromptCloud that does it at scale, with no maintenance or mess.
Where is The Code?
Without much ado, we decided to bring you the code for scraping real estate data using python that will help you extract information from a property listing website. The data crawling code is written in Python and subsequently, I will show you how to run it and what you will get once you run it.
[code language=”python”]
#!/usr/bin/python
# -*- coding: utf-8 -*-
import urllib.request
import urllib.parse
import urllib.error
from bs4 import BeautifulSoup
import ssl
import json
import ast
import os
from urllib.request import Request, urlopen
# For ignoring SSL certificate errors
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
# Input from user
url = input(‘Enter Zillow House Listing Url- ‘)
# Making the website believe that you are accessing it using a mozilla browser
req = Request(url, headers={‘User-Agent’: ‘Mozilla/5.0’})
webpage = urlopen(req).read()
# Creating a BeautifulSoup object of the html page for easy extraction of data.
soup = BeautifulSoup(webpage, ‘html.parser’)
html = soup.prettify(‘utf-8’)
property_json = {}
property_json[‘Details_Broad’] = {}
property_json[‘Address’] = {}
# Extract Title of the property listing
for title in soup.findAll(‘title’):
property_json[‘Title’] = title.text.strip()
break
for meta in soup.findAll(‘meta’, attrs={‘name’: ‘description’}):
property_json[‘Detail_Short’] = meta[‘content’].strip()
for div in soup.findAll(‘div’, attrs={‘class’: ‘character-count-truncated’}):
property_json[‘Details_Broad’][‘Description’] = div.text.strip()
for (i, script) in enumerate(soup.findAll(‘script’,
attrs={‘type’: ‘application/ld+json’})):
if i == 0:
json_data = json.loads(script.text)
property_json[‘Details_Broad’][‘Number of Rooms’] = json_data[‘numberOfRooms’]
property_json[‘Details_Broad’][‘Floor Size (in sqft)’] = json_data[‘floorSize’][‘value’]
property_json[‘Address’][‘Street’] = json_data[‘address’][‘streetAddress’]
property_json[‘Address’][‘Locality’] = json_data[‘address’][‘addressLocality’]
property_json[‘Address’][‘Region’] = json_data[‘address’][‘addressRegion’]
property_json[‘Address’][‘Postal Code’] = json_data[‘address’][‘postalCode’]
if i == 1:
json_data = json.loads(script.text)
property_json[‘Price in $’] = json_data[‘offers’][‘price’]
property_json[‘Image’] = json_data[‘image’]
break
with open(‘data.json’, ‘w’) as outfile:
json.dump(property_json, outfile, indent=4)
with open(‘output_file.html’, ‘wb’) as file:
file.write(html)
print (‘———-Extraction of data is complete. Check json file.———-‘)
[/code]
To run the code given above, you need to save it in a file with the extension, such as propertyScraper.py. Once that is done, from the terminal, run the command –
[code language=”python”]
python propertyScraper.py
[/code]
When you run it, you will be prompted to enter the URL of a property listing. This is the webpage that will actually be crawled for data by the program. We have used two links and scraped the data of two properties. Here are the links –
- https://www.zillow.com/homedetails/638-Grant-Ave-North-Baldwin-NY-11510/31220792_zpid/
- https://www.zillow.com/homedetails/10-Walnut-St-Arlington-MA-02476/56401372_zpid/
The JSON files obtained on running the code on the given in a later subtopic.
Code Explanation
Before going into how the code runs and what it returns, it is important to understand the code itself. As usual, we first hit the URL given and capture the entire HTML which we convert into a beautiful soup object. Once that is done, we extract specific divs, scripts, titles, and other tags with specific attributes. This way we are able to pinpoint specific information that we may want to extract from a page.
You can see that we have also extracted an image link for each property. This has been done deliberately since for something like real estate, images are just as much value as other information. While we have indeed extracted several fields from the real estate listing pages, it is to be noted that the HTML page does contain many more data points. Hence we are also saving the HTML content locally so that you can go through it and crawl more information.
Some of The House Listings that We Scraped
As we mentioned before, we actually crawled a few property listings for you to show you how the scraped data by Python would look in JSON format. Also, we have mentioned the property for which a particular JSON is, under the JSON. Now let’s talk about the data points that we scraped.
We got an image of the property (although many images for each property are available on a listing page, we got one for each- that is the top image for each listing). We also got the price (in $) that it is listed at, the title for the property, and a description of it that would help you create a mental picture of the property.
Along with this, we scraped the address, broken down into four separate parts: the street, the locality, the region, and the postal code. We have another details field that has multiple subfields, such as the number of rooms, the floor size, and a long description. In certain cases, the description is missing as we found out once we scraped multiple pages.
[code language=”python”]
{
“Details_Broad”: {
“Number of Rooms”: 4,
“Floor Size (in sqft)”: “1,728”
},
“Address”: {
“Street”: “638 Grant Ave”,
“Locality”: “North baldwin”,
“Region”: “NY”,
“Postal Code”: “11510”
},
“Title”: “638 Grant Ave, North Baldwin, NY 11510 | MLS #3137924 | Zillow”,
“Detail_Short”: “638 Grant Ave , North baldwin, NY 11510-1332 is a single-family home listed for-sale at $299,000. The 1,728 sq. ft. home is a 4 bed, 2.0 bath property. Find 31 photos of the 638 Grant Ave home on Zillow. View more property details, sales history and Zestimate data on Zillow. MLS # 3137924”,
“Price in $”: 299000,
“Image”: “https://photos.zillowstatic.com/p_h/ISzz1p7wk4ktye1000000000.jpg”
}
[/code]
[code language=”python”]
{
“Details_Broad”: {
“Description”: “Three dormer single family home situated in Arlington’s Brattle neighborhood between Arlington Heights and Arlington Center. Built in the 1920s this home offers beautiful period details, hard wood floors, beamed ceilings, fireplaced living room with private sunroom, a formal dining room, three large bedrooms, an office and two full baths. The potential of enhancing this property to expand living space and personalize to your personal taste is exceptional. Close to Minuteman Commuter Bikeway, Rt 77 and 79 Bus lines, schools, shopping and restaurants. Virtual staging and virtual renovation photos provided to help you visualize.”,
“Number of Rooms”: 4,
“Floor Size (in sqft)”: “2,224”
},
“Address”: {
“Street”: “10 Walnut St”,
“Locality”: “Arlington”,
“Region”: “MA”,
“Postal Code”: “02476”
},
“Title”: “10 Walnut St, Arlington, MA 02476 | MLS #72515880 | Zillow”,
“Detail_Short”: “10 Walnut St , Arlington, MA 02476-6116 is a single-family home listed for-sale at $725,000. The 2,224 sq. ft. home is a 4 bed, 2.0 bath property. Find 34 photos of the 10 Walnut St home on Zillow. View more property details, sales history and Zestimate data on Zillow. MLS # 72515880”,
“Price in $”: 725000,
“Image”: “https://photos.zillowstatic.com/p_h/ISifzwig3xt2re1000000000.jpg”
}
[/code]
[code language=”python”]
{
“Details_Broad”: {
“Number of Rooms”: 4,
“Floor Size (in sqft)”: “1,728”
},
“Address”: {
“Street”: “638 Grant Ave”,
“Locality”: “North baldwin”,
“Region”: “NY”,
“Postal Code”: “11510”
},
“Title”: “638 Grant Ave, North Baldwin, NY 11510 | MLS #3137924 | Zillow”,
“Detail_Short”: “638 Grant Ave , North baldwin, NY 11510-1332 is a single-family home listed for-sale at $299,000. The 1,728 sq. ft. home is a 4 bed, 2.0 bath property. Find 31 photos of the 638 Grant Ave home on Zillow. View more property details, sales history and Zestimate data on Zillow. MLS # 3137924”,
“Price in $”: 299000,
“Image”: “https://photos.zillowstatic.com/p_h/ISzz1p7wk4ktye1000000000.jpg”
}
[/code]
Scraping Real Estate Data on A Large Scale
Using code like this you can crawl details related to a few specific real estate properties only. You could manually check up on properties you are interested in from time to time. However, if you are looking to target a specific region in the USA, or internationally, you’d need an expert web scraping service provider or data scraping tools to help you gather property listings from a number of websites.
PromptCloud, as a leading web scraping provider believes that web scraping solutions should be hassle-free and should contain only two steps–the client gives the requirement and receives clean data.
Also, note here in the blog we have used both crawler and scraper. Don’t be confused more or less both are the same but if you want to know more, you can check our blog on web data crawling vs web data scraping.
Zillow Web Scraper
Image Source: https://www.bardeen.ai/
Real estate sites like Zillow host a wealth of data on properties across the United States. With databases containing information on over 100 million homes, these sites offer insights into houses for sale, rent, and those not currently on the market. One key feature of real estate sites is their provision of price comparisons and basic property information, including home type, number of rooms, square footage, and brief descriptions.
Reasons to Scrape Real Estate Data from Zillow
For real estate professionals seeking regional data rather than tackling millions of properties nationwide, utilizing a Zillow web scraper proves beneficial. By automating the process, you avoid manual data collection, allowing you to focus on analyzing the information gathered. Additionally, implementing machine learning algorithms enables you to make accurate property price predictions, comparing them against Zillow’s own Zestimates. This side-by-side evaluation reveals which method produces results closest to true market values.
Python Scraping Tutorial
Equipped with the right tools and knowledge, users can easily scrape real estate data using Python. Before delving into the code, ensure you have installed the required software components. Follow our comprehensive guide on setting up data scraping in Python, covering essential packages and editors.
With preparations completed, review the following Python code designed specifically for extracting information from Zillow property listings. To utilize the code below, copy it into a new Python file named `propertyScraper.py` and execute the commands within your preferred terminal environment. Note that you must supply a valid Zillow property listing URL when prompted during execution.
“`python
# … (code omitted for brevity; refer to original response)
# Prompts user for Zillow house listing URL
url = input(‘Enter Zillow House Listing Url- ‘)
# Creates a request header to mimic Mozilla browsing behavior
req = Request(url, headers={‘User-Agent’: ‘Mozilla/5.0’})
# Reads and stores HTML content from the requested URL
webpage = urlopen(req).read()
# Converts stored HTML content into a Beautiful Soup object
soup = BeautifulSoup(webpage, ‘html.parser’)
# Defines dictionary structure to hold property details
property_json = {
‘Details_Broad’: {},
‘Address’: {}
}
# Populates the dictionary with relevant data extracted from the HTML content
# … (code omitted for brevity; refer to original response)
# Writes the populated dictionary to a JSON file
with open(‘data.json’, ‘w’) as outfile:
json.dump(property_json, outfile, indent=4)
# Stores raw HTML content in a separate output file
with open(‘output_file.html’, ‘wb’) as file:
file.write(html)
print(“Extraction of data is complete. Check json file.”)
“`
This tutorial demonstrates the power of Python for quickly gathering real estate data from sources like Zillow. Automate tedious tasks, streamline your operations, and harness the benefits of web scraping today.
Can You Scrape Zillow Without Getting Into Trouble?
Here’s the truth.
Zillow shows data publicly. You don’t need a login to see listings, prices, or Zestimates. That makes it look like scraping should be fine.
But Zillow’s terms say otherwise. They don’t want you using bots or automation to pull data. If you do it anyway, they might block your IP. In some cases, they could send legal warnings. Does that mean scraping is illegal? Not exactly. But it can get messy fast if you’re not careful.
It depends on how you do it.
If you’re scraping a few pages for research and not hammering their servers, you’re probably fine. If you’re building a product or collecting thousands of listings every day? You better know what you’re doing.
The smart way to handle this is simple:
- Don’t scrape aggressively
- Don’t touch user data or anything behind a login
- Don’t pretend Zillow won’t notice — they monitor traffic
And if you’re serious about scale, work with a team that knows how to do this right. PromptCloud doesn’t just write scrapers—we make sure the process doesn’t blow up on you later.
Why PromptCloud Is the Smarter Way to Scrape Zillow Data
If you’ve made it this far, you already get the point: Zillow has a goldmine of real estate data. But getting that data—clean, fast, and consistent—isn’t easy. Doing it manually is a waste of time. Building your own scraper sounds fun until Zillow changes something and your whole script breaks. And doing it at scale without getting blocked? That’s a different beast altogether.
That’s where PromptCloud comes in.
We don’t just build a Zillow web scraper. We run fully managed data pipelines. You tell us what you want, location, price, rent data, Zestimates, listing types, and we deliver clean, structured data. Daily, weekly, whatever your need is.
You don’t deal with the tech. You don’t deal with maintenance. You don’t worry about getting blocked.
You just get the data when and how you need it.
This works whether you’re:
- An investment firm tracking price changes across 20 cities
- A PropTech company powering rental forecasts
- A realtor building their own internal market dashboards
- Or a research team that needs clean, large-scale listing data for modeling
We handle the messy parts. You get to focus on what matters: decisions backed by real-time real estate data. Contact us today!
FAQs
Is web scraping legal on Zillow?
It is pertinent to acknowledge that while Zillow’s Terms of Service stipulate that users must obtain express permission prior to using automated means to access or retrieve data from their platform, the act of scraping publicly available data per se is not inherently illegal. Courts in the United States and abroad have affirmed the legitimacy of web scraping under certain conditions, especially when the data in question is openly accessible and poses no threat to individual privacy or proprietary concerns. Nevertheless, deploying a Zillow web scraper to breach copyright laws or engage in illicit commercial activities would likely entail legal ramifications. Hence, it is imperative to familiarize oneself with relevant statutes and guidelines, along with the terms of service and privacy policies governing the target website(s), prior to initiating any web scraping endeavor.
Is it possible to scrape a Zillow?
Indeed, it is feasible to extract data from Zillow via diverse methodologies and instruments. Developers frequently leverage Python libraries, such as Beautiful Soup or Scrapy, or harness browser automation tools, like Selenium, to traverse and manipulate web page components programmatically. By doing so, they can harvest organized data embedded within the underlying HTML source code. Although Zillow may intermittently endeavor to thwart or constrain particular forms of web scraping activity, tenacious developers can usually circumvent such hurdles through strategic modifications to their strategies or implementation of countermeasures.
Is it legal to web scrape?
The lawfulness of web scraping is contingent upon multiple variables, encompassing the jurisdictional context, the objective behind the scraping operation, and the kind of data procured. Generally speaking, gathering publicly accessible information via web scraping constitutes a legitimate practice; however, exceptions exist. Instances wherein sensitive or classified information is targeted, or the terms of service of a given website are transgressed, may trigger judicial intervention. Furthermore, although the scraping process itself may adhere to legal standards, repurposing the acquired data in an unauthorized fashion – say, vending it to external entities devoid of appropriate consent – can culminate in liabilities. Thus, consulting with legal professionals and undertaking comprehensive due diligence become indispensable prerequisites preceding any web scraping venture.
How to pull data from Zillow?
Extracting data from Zillow involves two primary steps. First, pinpoint the desired data points within the HTML framework comprising the website. Subsequently, generate code capable of isolating and preserving those items in a file format conducive to analysis, e.g., CSV or JSON. An assortment of programming languages, such as Python, can facilitate this mission alongside compatible libraries, among them Beautiful Soup and Scrapy, or alternative browser automation resources, like Selenium. Crucially, ensure compliance with usage permissions associated with the sought-after data and exercise restraint when soliciting server resources to obviate unnecessary strain. Error management protocols and prudent resource allocation can significantly bolster the efficacy and stability of your customized Zillow web scraper.
What is a Zillow web scraper, and why do I need one?
It’s a simple tool that pulls property data from Zillow without you having to sit and do it manually. If you deal with listings, pricing trends, or any kind of real estate analysis, this saves you hours. You get clean, usable data fast.
Disclaimer: The code present in our tutorial is only for learning purposes. We will not be responsible for the way it is used, and there will be no liability from our end for any adverse effect of the source code. The mere presence of this code on our site does not imply that we promote scraping or crawling the websites mentioned in the article. The sole purpose of this tutorial is to showcase the technique of writing web scrapers for leading web portals. We are not obligated to deliver any support for the code, however; we encourage you to add your questions and feedback in the comment section so that we may check and respond at certain intervals.















