




**TL;DR**
An AI-ready pipeline is the system that keeps your data steady, structured, and trustworthy before it ever reaches a model. It handles the messy parts you don’t see pulling data in reliably, giving it a predictable shape, adding the right context, checking quality, tracking where every record came from, and watching for changes over time. When these pieces work together, the model trains on data it can depend on, which means fewer surprises, fewer debugging cycles, and far more stable performance in the real world.
The State of AI-Ready Pipeline in 2025
Most teams talk about AI as if it is the heart of the model but it’s actually the pipeline that does the hard work in the background. If the pipeline is weak, the model struggles no matter how advanced the architecture. If the pipeline is strong, even a simple model performs with surprising accuracy. It explains how raw data becomes something an AI system can actually learn from.
An AI-ready pipeline is not a single tool or workflow. It is a sequence of tightly connected layers that prepare data for use in machine learning. Each layer has a job. Acquisition brings the data in. Structuring gives it shape. Enrichment adds meaning. Validation protects quality. Lineage keeps everything traceable. Governance sets the rules. It is a technical look at the architecture behind reliable AI systems.
Your data collection shouldn’t stop at the browser. If your scrapers are hitting limits or you’re tired of rebuilding after every site change, PromptCloud can automate and scale it for you.
What an AI-Ready Pipeline Actually Is
An AI-ready pipeline is the system that shapes raw, unstructured, unpredictable data into a format that machine learning models can trust. When a model produces a stable pattern, it is because the pipeline behind it is stable. When a model drifts or behaves inconsistently, the pipeline is usually where the issue starts. The goal of an AI-ready pipeline is to eliminate that uncertainty by controlling each stage between raw ingestion and model consumption.
An AI-ready pipeline does 3 things well:
- It delivers data in a consistent shape, even when sources update their structure.
- It attaches context, meaning, and lineage, so models know what they are learning from.
- It enforces quality, governance, and monitoring, so the dataset stays reliable over time.
These functions turn scattered inputs into structured data flows. They also prevent the common issues that damage model performance, such as silent schema drift, missing metadata, low-quality attributes, fragmented sources, and unmanaged bias. When the pipeline is designed correctly, every downstream workflow benefits. Feature engineering becomes cleaner. Model training becomes faster. Retraining cycles become predictable. Debugging becomes far easier because you can trace every record back to its origin.
The High-Level Architecture of an AI-Ready Pipeline
| Pipeline Layer | What It Does |
| Acquisition | Pulls data from multiple sources on a consistent, controlled schedule so the pipeline receives a steady stream of raw input. |
| Structuring | Converts messy raw inputs into a predictable schema with unified field names, formats, and data types the model can understand. |
| Enrichment | Adds context such as labels, attributes, metadata, and extracted signals that help the model interpret what each record represents. |
| Validation | Filters out incomplete, contradictory, out-of-range, or low-quality records to protect the dataset from noise. |
| Lineage | Captures source, timestamps, and transformation history so every record can be traced and audited end-to-end. |
| Governance | Defines rules for access, retention, versioning, and schema changes, ensuring the pipeline remains controlled and consistent. |
| Monitoring | Tracks drift, freshness, volume changes, and structural issues to keep the pipeline stable as the data environment evolves. |
These layers form a chain. If one breaks, the rest become unstable. A weak acquisition layer sends inconsistent inputs downstream. Poor structuring forces the model to waste cycles on formatting instead of learning. Missing lineage makes debugging nearly impossible. Weak governance creates multiple conflicting versions of the same dataset. And without monitoring, slow drift accumulates until accuracy falls off a cliff. This architecture is what allows complex AI systems to perform with consistency rather than luck.
Deep Dive Into Each Layer of the AI-Ready Pipeline
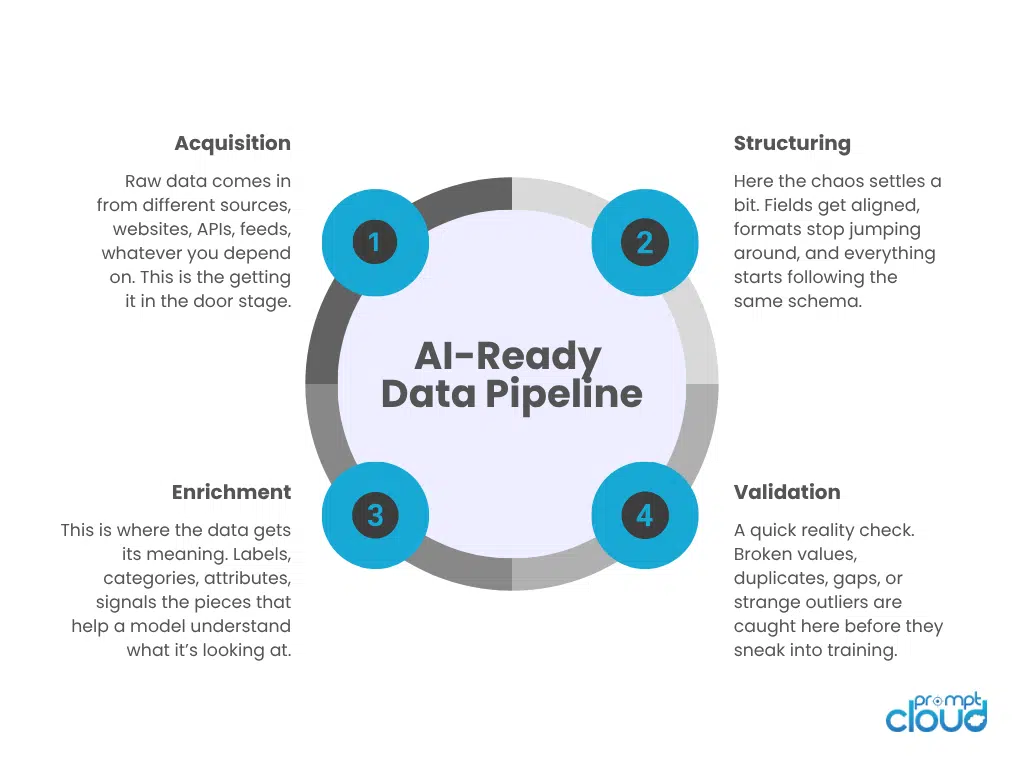
1. Acquisition Layer: Getting the data through the door
This is the part of the pipeline that basically says, “Alright, give me everything you’ve got.” It collects data from all those messy places, sites that load slowly, APIs that behave differently depending on the hour, sources that sometimes vanish without notice. The real job here isn’t fancy. It’s reliable. The pipeline needs data to show up in a steady, predictable way… even when the sources aren’t predictable at all.
Core function: Keep the raw data flowing without the rest of the system panicking.
2. Structuring Layer: Making the data stop misbehaving
Once the data arrives, it’s all over the place. Different shapes, different labels, different moods on different days. The structuring layer is where you take a deep breath and say, “Let’s get you all speaking the same language.” Fields get aligned, formats become normal, and the data finally settles into something that looks like an actual dataset instead of a drawer full of mismatched cables.
Core function: Turn the chaos into a shape the pipeline (and the model) can rely on.
3. Enrichment Layer: Adding the missing meaning
Structured data is nice… but honestly, it’s still a bit empty. What the enrichment layer does is fill in the blanks. It pulls out useful bits, categories, sentiment, skills, attributes and the kind of details that help the model understand what it’s looking at. Think of it as turning a plain sentence into one with context. Suddenly the data has depth.
Core function: Give the data enough meaning so the model doesn’t have to guess.
4. Validation Layer: The friend who tells you something’s off
This layer is the honest one. It catches things that don’t look right, missing values, strange outliers, contradictions, duplicates that somehow crept in. Without this checkpoint, all those tiny errors slip straight into training and quietly distort the model. Validation is the moment you pause and say, “Hold on… this doesn’t add up.”
Core function: Stop bad records early instead of trying to fix damage later.
5. Lineage Layer: Keeping receipts
At some point, someone will ask: “Where did this record even come from?” And if you don’t have an answer, debugging becomes a nightmare. The lineage layer solves that by keeping receipts for every piece of data when it arrived, from where, what changed, and why. When things go wrong (they always do), lineage is how you retrace your steps.
Core function: Make every record traceable, like a breadcrumb trail back to its source.
6. Governance Layer: Setting some basic house rules
Pipelines fall apart fast when anyone can change anything. The governance layer prevents that mess. It defines who can touch the data, how long it should be kept, when schemas can change, and how those changes are approved. It’s the layer that keeps everyone aligned and stops ten different “final versions” from floating around.
Core function: Keep the pipeline organised and consistent as it grows.
7. Monitoring Layer: Noticing the small problems before they turn into big ones
Even the best pipeline drifts over time. Sources change their layout, values start shifting, or something just feels “off.” Monitoring is the part that notices those changes early before they spread into training runs or production systems. It’s like a dashboard that quietly watches the pulse of the whole pipeline. Not dramatic, but essential.
Core function: Catch drift, breakages, and unexpected changes before they hit the model.
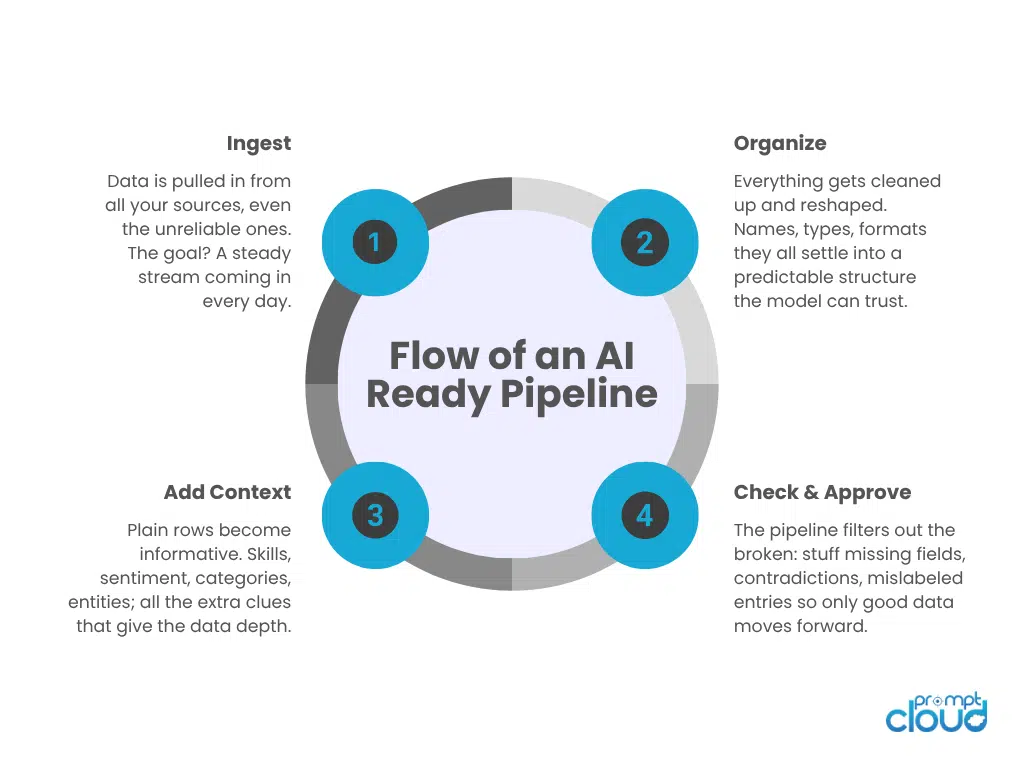
How These Layers Work Together (End-to-End Flow)
| Pipeline Layer | What It Does in the Flow | What It Passes to the Next Layer | Risk If This Layer Is Weak or Missing |
| Acquisition | Brings raw data into the system from multiple sources on a steady, predictable schedule. | Unfiltered, messy input that still reflects the real world but has no uniform shape. | Downstream teams see gaps, sudden drops, or surges in data with no clear reason. Pipelines feel unreliable from day one. |
| Structuring | Maps raw fields into a consistent schema, unifies names, types, and formats across sources. | Structured records that share the same layout, making the dataset behave like a single source. | Models receive shifting column positions and formats, which breaks patterns and harms accuracy. |
| Enrichment | Adds labels, tags, attributes, and metadata so each record carries clear meaning and context. | Context-rich data where products, jobs, reviews, or events are clearly described and easy to interpret. | Models must guess what records represent, leading to shallow learning and misinterpretation of signals. |
| Validation | Runs quality checks to remove broken values, missing essentials, contradictions, and duplicates. | Clean, consistent, de-duplicated data that the model can learn from with far less noise. | Errors slip into training, causing unstable performance, strange edge cases, and hard-to-explain predictions. |
| Lineage | Attaches timestamps, source identifiers, and processing history to every record. | Fully traceable data where each row has a visible origin and transformation path. | When accuracy drops, no one can see why. Debugging, audits, and compliance become slow and painful. |
| Governance | Defines who can access data, how updates happen, how retention works, and how changes are approved. | A controlled environment where datasets evolve in a managed, documented way. | Multiple “truths” appear, versions drift, and informal changes introduce silent inconsistencies. |
| Monitoring | Watches the entire pipeline over time for drift, structural changes, volume anomalies, and failures. | Alerts, dashboards, and signals that show when something has changed before it hits the model hard. | Drift accumulates quietly until the model degrades, forcing fire-fighting instead of planned retraining. |
What Happens When a Pipeline Layer Fails (Failure Modes)
| Pipeline Layer | What Fails | Symptoms You See | Impact on Models |
| Acquisition | Data stops arriving consistently from one or more sources. | Sudden drops in volume, missing segments, gaps in time windows, some sites or markets quietly disappear from the feed. | Models train on incomplete views of reality, leading to skewed patterns, bias toward remaining sources, and unstable predictions. |
| Structuring | Schema changes silently or becomes inconsistent across sources. | Fields move or disappear, formats flip between text and numbers, new columns appear without mapping, old ones break existing transformations. | Inputs no longer match what the model expects, so patterns fail, features degrade, and accuracy falls even when the model code has not changed. |
| Enrichment | Labels, tags, or extracted attributes are missing or degraded. | Categories are applied inconsistently, entities are not resolved correctly, key attributes are empty or only partially populated. | Models misinterpret records because they lose context, leading to weaker segmentation, poorer matching, and shallow understanding of the data. |
| Validation | Quality checks are relaxed, bypassed, or misconfigured. | More duplicates appear, obvious errors slip through, extreme outliers show up, missing values spread across critical fields. | Noise enters the training set, so the model learns from flawed examples and produces unstable, harder-to-explain predictions. |
| Lineage | Source, timestamp, and transformation history are not captured. | No clear way to see where a bad record came from, when it was ingested, or which version of the pipeline produced it. | Debugging becomes slow and guesswork-heavy, and it is difficult to audit or prove how a model reached its output. |
| Governance | Access and changes are uncontrolled or undocumented. | Different teams use different datasets, schema changes happen informally, retention rules are ignored, “final” versions multiply. | There is no single source of truth, experiments are hard to compare, and trust in the data declines across the organisation. |
| Monitoring | Drift, structural change, and failures are not tracked or alerted. | Source changes go unnoticed, distributions shift over time, errors accumulate, and problems are spotted only after users complain. | Accuracy erodes gradually, retraining becomes reactive instead of planned, and the pipeline feels fragile instead of dependable. |
Why This Pipeline Design Matters for AI Teams
An AI-ready pipeline is not just an operational convenience. It is the difference between a model that performs reliably and a model that behaves unpredictably. Most AI teams discover this only after they scale. A pipeline built with the right layers creates that consistency.
There are also downstream benefits that make this architecture essential.
- Retraining becomes predictable because the inputs no longer shift unexpectedly.
- Debugging becomes faster because every record has lineage and history.
- Model drift becomes manageable because monitoring catches changes before they reach production.
- Feature engineering improves because structured, enriched data produces clearer signals.
- Quality issues stop propagating because validation filters out problems early.
- Team workflows stay aligned because governance prevents conflicting versions.
For AI teams, this pipeline design is not an enhancement. It is infrastructure. This is why high-performing AI organizations treat the pipeline as a core asset. It is the engine that keeps the entire system stable. Without it, even the most advanced models struggle to operate with confidence.
Further Reading From PromptCloud
If you want to understand how AI-ready data interacts with automation, agents, synthetic datasets, and QA workflows, these guides are the best next steps. They show how stable pipelines unlock more advanced use cases inside AI systems.
- Learn how modern agents consume structured data in our guide to AI web scraping agents.
- See how AI-ready data shapes GenAI pipelines in this breakdown of GenAI-driven web scraping.
- Understand how synthetic datasets amplify AI quality in our guide to synthetic data generation for AI.
- Improve pipeline reliability through this detailed workflow for scraping QA automation.
Know more: Microsoft’s guide to preparing data for machine learning. This resource explains how data must be structured, validated, transformed, and monitored before it enters an ML workflow.
Your AI Is Only as Good as Its Pipeline
AI systems succeed only when the data beneath them is stable, consistent, and traceable. Models do not perform well because of luck. They perform well because the pipeline feeding them is designed with structure, validation, lineage, governance, and monitoring from the start. This is what separates AI that works on a slide deck from AI that works in production.
An AI-ready pipeline gives teams a dependable foundation. Data arrives predictably. The structure remains stable. Context is preserved. Quality issues are filtered before they spread.
Your data collection shouldn’t stop at the browser. If your scrapers are hitting limits or you’re tired of rebuilding after every site change, PromptCloud can automate and scale it for you.
FAQs
1. Do I really need a full pipeline, or can I just clean the data once and be done?
You can clean a dataset once and ship a model. It might even work for a bit. But the moment sources change, formats shift, or you add new data, you’re back at square one doing the same painful cleanup again. A proper pipeline just builds that effort into the system, so you’re not restarting from scratch every time.
2. Why does my model behave differently every time I retrain it?
That usually means your inputs are changing more than you think. Maybe a field quietly disappeared, or one source started sending different formats, or some validation rule stopped running. The model looks “unstable,” but the real problem is that the data it sees on Monday is not the same as the data it saw last month. An AI-ready pipeline smooths out those differences so retraining feels repeatable, not random.
3. Is all this lineage and governance stuff only for regulated industries?
No. It helps there, sure, but it’s just as useful for teams that are tired of guessing. Lineage is what lets you answer “where did this come from?” without digging through old scripts. Governance is what stops five teams from quietly editing the same dataset in five different ways. Even if you’re not in finance or healthcare, having those controls saves a lot of future pain.
4. What’s the first sign that my pipeline is not really AI-ready?
A big red flag is when people start saying, “The model was great last month, not sure what happened.” If nothing changed in the code but performance still dropped, your data pipeline is drifting underneath you. Another sign: everyone keeps a private “fixed” version of the data because no one trusts the main one.
5. We’re a small team. Is building an AI-ready pipeline overkill for us?
Not if you plan to do this more than once. Small teams feel the pain more because they don’t have spare people to constantly babysit broken data. A lightweight, well-designed pipeline means you clean things properly once, then reuse that system for new sources and new models instead of firefighting every time you add a project.















