




AI Web Scraping Challenges in 2026
Web scraping for AI is not a volume problem. It’s a precision problem. Most failures don’t happen during scraping. They surface months later as biased datasets, model drift, noisy labels, and hallucinations traced back to bad machine learning data collection. If you think more web data automatically means better models, you’re already exposed. This article breaks down the ten structural challenges behind AI training data from web scraping.
Why do you Need Web Data for AI and Machine Learning?
When teams talk about web scraping for AI, they usually talk about scale. More pages. More domains. More tokens. More images. Larger datasets for LLM training data. Bigger crawls feeding real-time data pipelines. That amplification is the problem.
Most content ranking for web scraping for AI focuses on tooling. Scrapers. APIs. Python scripts. Crawlers. Useful topics, but shallow. They ignore what actually breaks once scraped data becomes part of machine learning data collection.
The issues show up later. Bias in outputs. Model drift. Hallucinated facts. Skewed recommendations. Weak generalization. All traced back to training data assumptions that were never validated. Web scraping for AI is not about extraction alone. It’s about curation, labeling, validation, deduplication, and drift management.
Let’s start with the foundation.
Get clean, structured web data delivered on your cadence from a managed pipeline built around your specific sources and schema.
PromptCloud has prepared and structured AI training datasets for enterprise teams across retail, manufacturing, and analytics platforms processing millions of records per day.
“After deduplication and restructuring, our usable training dataset was 30% smaller — and model performance improved measurably.”
Head of Applied AI
Global Marketplace
Challenge 1: Unstructured Web Data in AI Training Pipelines
This is about surface-level noise – what gets extracted.
The web was not designed for clean model ingestion. Pages contain navigation clutter, promotional copy, duplicated fragments, embedded scripts, inconsistent formatting, and contextual assumptions. When scraped raw, this becomes a noisy mixture of content and structural debris.
For LLM training data, that noise matters. A model does not know which paragraph was an advertisement. It does not know that a product comparison page copied text from another site. It does not know that a snippet was outdated. Unstructured web data becomes structured ignorance if not aggressively cleaned.
Teams often underestimate the preprocessing required to convert scraped HTML into meaningful machine learning data collection pipelines. Stripping markup is not enough. Context extraction, boilerplate removal, and semantic filtering become critical. Without this, web scraping for AI produces datasets that are technically large but semantically weak.
This is particularly visible in multimodal datasets. When extracting images from websites, metadata alignment becomes essential. Capturing images without contextual labels leads to disconnected training pairs.
For example: extract images from website.
Next, we’ll move into a deeper problem that hides inside “large” datasets: content duplication that inflates signal artificially.
Challenge 2: Content Deduplication for AI Training Data
The web repeats itself constantly. Press releases syndicated across dozens of domains. Blog posts republished across content networks. Product descriptions replicated across affiliate marketplaces. When you perform web scraping for AI at scale, duplication is not a minor inconvenience. It is structural.
If you don’t aggressively manage content deduplication, your AI training data from web scraping becomes skewed. Models start over-weighting dominant narratives simply because they appear more frequently, not because they are more correct. Minority viewpoints shrink. Niche terminology gets drowned out. Repeated product claims become “facts” inside embeddings. Exact duplicate removal is the easy part. The hard part is near-duplicate detection.
Two articles may differ slightly in wording but contain the same informational core. Two product pages may vary in formatting while describing identical attributes. Without similarity clustering and canonical selection logic, your dataset becomes artificially confident. This is especially dangerous for LLM training data. Repetition inflates certainty. It reduces diversity. And it increases the likelihood that hallucinations align with common but incorrect patterns.
Web scraping for AI requires entity-level and semantic deduplication, not just URL-level filtering. If your machine learning data collection pipeline assumes each page equals one unique signal, your dataset is lying to you.
In curated AI training datasets prepared from large-scale web scraping, near-duplicate removal typically reduces usable token volume by 20–40% from the raw crawl. That reduction is not loss. It is signal correction.

Figure 1: The three operational layers required to convert scraped web data into reliable AI training datasets.
Next, we’ll examine a challenge that is even more subtle and far more damaging: biased datasets created by uneven web representation.
Challenge 3: Biased Datasets from Uneven Web Coverage
The web does not represent reality evenly. Certain languages dominate. Certain regions publish more frequently. Certain industries have stronger SEO footprints. Certain demographics produce more digital content. When you scrape broadly without weighting, you inherit those imbalances.
Biased datasets are not always obvious. They look large. They look diverse. But they may overrepresent certain perspectives, price bands, product categories, or opinions. AI models trained on such data reflect those distortions. Web scraping for AI becomes a bias propagation mechanism if not actively managed.
That skews pricing models and recommendation systems. Large-scale marketplace data extraction, such as from global retail platforms, must account for this imbalance explicitly. See how retail scraping is applied in practice: Temu data scraping for retail success
Bias is not fixed by more data. It is fixed by intentional sampling, weighting, and validation. Without this, machine learning data collection pipelines quietly encode structural inequality into models.
Next, we’ll look at a challenge that affects not just fairness but performance: data labeling challenges that introduce hidden noise.
Challenge 4: Data Labeling Challenges in Machine Learning Data Collection
Scraping gives you raw content. AI models need labeled signals. That gap is where accuracy quietly collapses. When teams build AI training data from web scraping, labeling is often treated as a downstream step. Tags are inferred. Categories are mapped. Sentiment is auto-generated. Entities are extracted. All of this sounds systematic.
But labeling at scale introduces systematic noise. Weak heuristics misclassify edge cases. Automated tagging pipelines misinterpret context. Human annotators receive incomplete metadata. Region-specific nuance gets flattened into generic classes. The result is not a random error. It is a patterned distortion.
And patterned distortion is dangerous. Models trained on mislabeled data don’t just make occasional mistakes. They internalize the labeling bias. They learn incorrect associations with high confidence. For LLM training data, this becomes especially problematic. Instruction-tuned datasets scraped from forums or Q&A sites may include mislabeled intents. Response quality varies dramatically. Context windows get truncated. Without careful review, machine learning data collection becomes a confidence engine for flawed annotations.
Strong pipelines treat labeling as a monitored layer. They measure inter-annotator agreement. They audit automated tagging accuracy. They track label drift over time. Without this, you may believe you are training on structured intelligence when you are actually training on structured noise.
Next, we’ll move into a problem that connects directly to long-term performance: model drift caused by static scraped datasets in a dynamic web.
Challenge 5: Model Drift from Outdated Scraped Data
The web changes continuously. Product specifications evolve. Language shifts. Regulations update. Market sentiment moves. If your AI training data from web scraping captures a snapshot and never refreshes, your models age silently.
Model drift is rarely traced back to the dataset immediately. Teams blame architecture. Hyperparameters. Fine-tuning strategy. But the real issue is often temporal misalignment. The world changed. The dataset did not. Web scraping for AI must consider refresh cadence as a first-class concern.
Real-time data pipelines introduce their own complexity. They require version control. Change tracking. Historical retention. Without these, retraining becomes inconsistent. Manufacturing insights, regulatory text, product listings, and technical documentation evolve frequently. See how web data impacts industrial performance analysis: how manufacturing industry can boost productivity with web scraping.
If your scraped dataset is static while your deployment environment is dynamic, drift is inevitable. Next, we’ll examine the structural challenge that complicates all others: synthetic versus real web data trade-offs in AI training.
Struggling to Prepare Training-Grade Data?
Get clean, structured web data delivered on your cadence from a managed pipeline built around your specific sources and schema.
Challenge 6: Synthetic vs Real Web Data in AI Training
This debate is getting louder. As synthetic data generation improves, many teams are tempted to reduce reliance on real web scraping for AI. Synthetic datasets are cleaner. Easier to control. Free from copyright ambiguity. Balanced by design. But synthetic data has limits.
It reflects the distribution of whatever model generated it. If that base model was trained on biased, noisy, or outdated web data, synthetic outputs inherit those weaknesses. Amplification without grounding becomes circular. Real web data, on the other hand, is messy but current. It captures emerging language, new products, regulatory changes, regional nuance.
The failure mode appears when teams overcorrect. Too much synthetic data and your model becomes internally consistent but externally misaligned. Too much unfiltered web scraping and your model becomes current but unstable. The solution is not scale. It is calibration.
Next, we’ll move into a practical bottleneck that many teams underestimate: data pipeline scalability for AI workloads.
Challenge 7: Real-Time Data Pipelines and Validation Gaps
When web scraping for AI becomes continuous, validation struggles to keep up. Real-time data pipelines feel powerful. Fresh signals. Live ingestion. Constant retraining loops. But the faster the pipeline, the harder it becomes to enforce rigorous data quality for AI models. Validation takes time. Deduplication takes time. Bias analysis takes time. Label audits take time. When ingestion frequency increases, teams often reduce validation depth to maintain throughput.
That trade-off accumulates risk. Machine learning data collection pipelines built for velocity may skip relational checks. Skip distribution monitoring. Skip human sampling. Over time, subtle errors compound and enter training loops faster than they can be detected.
Speed amplifies both signal and noise. Maintaining web scraping for AI at scale requires layered validation pipelines. Ingestion does not automatically mean eligibility for training. Data needs staging. Scoring. Filtering. If your pipeline treats real-time scraping as automatically trustworthy, you are optimizing for freshness over correctness.
Next, we’ll explore a problem tied directly to modern AI systems: LLM training data and long-context contamination.
Challenge 8: Context Fragmentation in LLM Training Data
This goes deeper into structural fragmentation — what gets lost when context is broken apart during ingestion.
Large language models consume text in chunks. When scraping the web for AI training data, content is often segmented into token-sized fragments. Paragraph boundaries shift. Context is truncated. Attribution disappears.
This creates fragmentation. An answer scraped from a forum may lose the question it responds to. A quote may lose attribution. A specification may lose version context. When ingested into LLM training data, these fragments become standalone truths.
That is dangerous. Without preserving structural relationships, web scraping for AI creates knowledge without provenance. Models internalize fragments disconnected from original intent. This problem intensifies when using common scraping scripts without contextual extraction logic. Many Python-based scraping implementations focus on capturing text nodes efficiently.
For reference: web scraping with Python
Extraction is not the hard part. Preserving context is. If LLM training data loses source framing, models learn answers without constraints.
Next, we’ll examine a challenge tied to both ethics and performance: copyright and compliance risk embedded in training datasets.
Challenge 9: Compliance and Copyright Risk in AI Datasets
Web scraping for AI does not exist in a vacuum. Content may be copyrighted. Personally identifiable information may appear. Terms of service vary. Regulatory expectations evolve. When scraped data feeds AI systems, compliance becomes part of data quality.
This is not only legal risk. It is an operational risk. If datasets must be retroactively filtered due to policy changes, retraining becomes mandatory. If PII was unintentionally captured, models may learn patterns they should not have seen. AI training data from web scraping must integrate compliance filters early. PII masking. Source tracking. License classification. Without these controls, models become compliance liabilities. And once a model is trained, removing knowledge is not straightforward. The web is open. Usage is not.
Next, we’ll close with a challenge that sits above all others: false confidence that scale equals readiness.
Challenge 10: Dataset Scale vs Model Readiness
The final and most common mistake. Teams measure tokens. Terabytes. Page counts. Crawl frequency. They assume that more scraped data automatically improves model performance. It doesn’t. Data quality for AI models depends on diversity, balance, labeling accuracy, freshness, deduplication, and bias mitigation. Scale amplifies whatever weaknesses already exist.
A small, carefully curated dataset often outperforms a massive unfiltered scrape. Web scraping for AI is powerful precisely because it can generate volume. But volume without curation becomes noise accumulation. If your evaluation metrics do not trace model errors back to dataset composition, you will misdiagnose performance issues repeatedly. Scale is a multiplier. Not a solution.
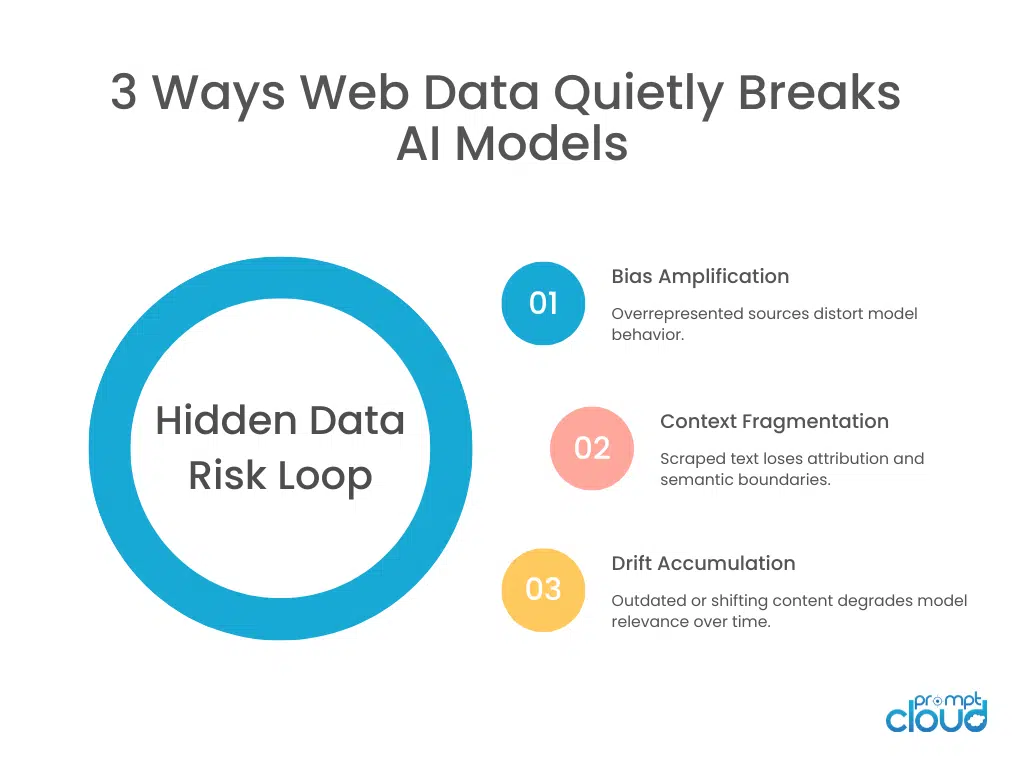
Figure 2: The recurring cycle through which scraped web data introduces bias, fragmentation, and drift into AI systems.
Where Web Scraping for AI Actually Breaks
| Challenge | What It Looks Like in Practice | Why Teams Miss It | Long-Term Impact on Models |
| Unstructured web data | Clean HTML but noisy semantic content | Basic text cleaning seems sufficient | Weak contextual understanding |
| Content duplication | Repeated articles, listings, FAQs | URL-level dedupe only | Inflated confidence, narrow diversity |
| Biased datasets | Overrepresentation of dominant sources | More data assumed to mean balance | Skewed outputs and systemic bias |
| Labeling noise | Misclassified tags and inferred categories | Automated labeling not audited | Patterned prediction errors |
| Model drift | Gradual drop in relevance | Blamed on architecture, not data | Reduced real-world performance |
| Synthetic vs real imbalance | Overclean or overly noisy corpora | Trade-offs not measured | Poor generalization |
| Real-time ingestion overload | Fast pipelines, shallow validation | Speed prioritized over control | Error amplification |
| Context fragmentation | Text chunks lose source relationships | Extraction optimized for volume | Hallucination and misattribution |
| Compliance gaps | PII and licensed content mixed in | Governance treated as legal-only issue | Retraining costs, regulatory exposure |
| Scale illusion | Massive datasets with low curation | Volume mistaken for quality | Diminishing returns on training |
The Way Forward in 2026
Web scraping for AI is powerful because it exposes real-world signals. It is dangerous because it exposes real-world noise. Every dataset encodes choices:
- Which sources were included
- Which were weighted
- What was filtered
- How labels were applied
- How duplication was handled
- How context was preserved
When AI systems fail, the issue is often upstream. Duplicate content inflated confidence. Fragmented context removed attribution. Biased coverage skewed outputs. Static snapshots caused drift. Scale amplified weaknesses.
The instinct is to tune the model. The discipline is to question the dataset.
AI training data from web scraping must be engineered, not accumulated. Sample intentionally. Deduplicate semantically. Preserve context. Monitor drift continuously. Treat compliance as structural, not reactive. Because in AI systems, data is not just input. It becomes behavior.
What separates high-performing AI teams is disciplined data engineering. They treat web data as structured training input, not scraped text blobs. This is why data for AI and machine learning requires normalization, labeling, deduplication, and drift monitoring built into the pipeline. Organizations reaching this realization often evaluate whether their current scraping workflows can sustain long-term model performance.
Don’t Let Accuracy Failures Surface in Production
Get clean, structured web data delivered on your cadence from a managed pipeline built around your specific sources and schema.
Most AI teams optimize architecture before auditing training datasets. That order is backwards.
If you’re scaling AI systems on scraped data, the next step is not more tokens. It’s a deeper validation.
Let’s review your pipeline.
FAQ
1. Why is web scraping for AI more complex than regular data scraping?
Because AI systems amplify patterns in the data. Small inconsistencies, bias, or duplication in scraped datasets become persistent behaviors in trained models.
2. Does more scraped data automatically improve model performance?
No. Volume amplifies both signal and noise. Without deduplication, bias control, and validation, larger datasets can reduce model reliability.
3. How does content duplication affect LLM training data?
Repeated content skews probability distributions. Models become overconfident in dominant narratives and underexposed to diverse viewpoints.
4. What is the biggest hidden risk in AI training data from web scraping?
Context fragmentation. When scraped text loses attribution or surrounding context, models learn incomplete or misleading associations.
5. How often should scraped datasets be refreshed for machine learning?
It depends on domain volatility, but drift monitoring should be continuous. If the real world changes faster than your retraining cycle, model performance will degrade.















