




When you’re working in real estate, data isn’t optional; it’s your edge. Whether you’re a solo investor scouting for hidden gems, a PropTech founder building dashboards, or a researcher analyzing market shifts, the one site you always find yourself on is Zillow.com. And why not? Zillow hosts a massive collection of property listings with details like square footage, price history, rental estimates, neighborhood stats, and even photos.
But there’s a catch.
Zillow is made for browsing, not for bulk data extraction. Trying to manually collect and update this kind of information—listing after listing, tab after tab—is exhausting and incredibly inefficient. And that’s where a Zillow data scraper can change the game.
The real question is: Which Zillow scraper fits your needs? Should you build your own? Try a no-code tool. Or go with a fully managed website data scraping service?
This article compares your options, from DIY scripts to enterprise-grade solutions, to help you pick the right Zillow scraper for your workflow, goals, and technical comfort level.
**TL;DR:** Zillow hosts valuable real estate data, but it’s built for browsing not analysis. This guide breaks down how to scrape Zillow using code, no-code tools, or managed services like PromptCloud. Whether you’re a solo investor or a PropTech startup, this article helps you pick the right scraping method to get reliable, structured data without getting blocked.
Why You Need a Zillow Data Scraper
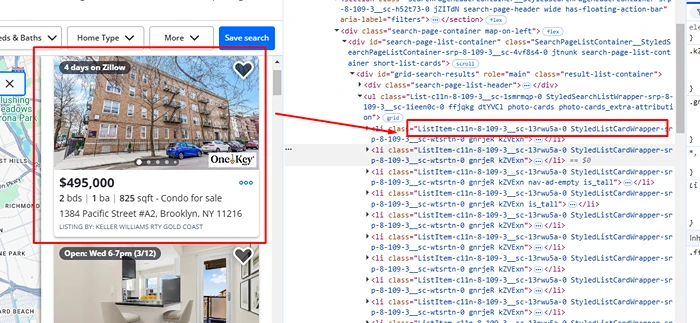
Image Source: Scrapingdog
You’re here because Zillow has the real estate data you want, but it’s locked up behind endless clicks.
Sure, Zillow.com gives you prices, Zestimates, square footage, tax history, rental potential, you name it. But collecting that manually? It’s a waste of time.
That’s where a Zillow data scraper changes everything.
With a scraper, you’re not clicking listings. You’re pulling structured, real-time data fast. You get exactly what you need: price, beds, square feet, photos, rental estimates, and even neighborhood trends. Automatically. Repeatedly. At scale.
If you’re trying to track the market, analyze patterns, or build models, a Zillow scraper isn’t a nice to have. It’s non-negotiable.
Whether you’re an investor watching prices across 10 zip codes or a startup building rent prediction tools, scraping Zillow is the smarter play.
Now, how should you do it? Code? No-code? Or pay someone to handle it for you?
Let’s compare.
Build a Zillow Data Scraper Yourself (With Python)
Let’s be real—if you want full control over your real estate data, writing your own Zillow data scraper is the way to go.
No subscriptions. No limits. No waiting for someone else to get your data. Just code, scrape, and get what you need.
You don’t need to be a software engineer. If you’ve written a few lines of Python before—or you’re willing to learn on the fly—you can pull property data directly from Zillow.
Before We Start
This script is just a tutorial. Zillow.com changes often, and scraping in bulk may go against their terms. What you do with this is on you.
You’ll Need:
- Python 3.x installed
- The following libraries: requests, BeautifulSoup, and pandas
Install them with:
bash
pip install requests beautifulsoup4 pandas
Code: Simple Zillow Data Scraper
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = ‘https://www.zillow.com/homedetails/10-Walnut-St-Arlington-MA-02476/56401372_zpid/’
headers = {
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64)’
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, ‘html.parser’)
try:
title = soup.find(‘title’).text.strip()
description = soup.find(‘meta’, attrs={‘name’: ‘description’})[‘content’].strip()
except:
title = description = ‘N/A’
data = {
‘URL’: url,
‘Title’: title,
‘Description’: description
}
df = pd.DataFrame([data])
df.to_csv(‘zillow_data.csv’, index=False)
print(“Data saved to zillow_data.csv”)
else:
print(f”Failed. Status code: {response.status_code}”)
What It Does:
- Fetches a Zillow listing page
- Grabs the title and description
- Dumps it into a CSV file
That’s it. You can expand it to pull more: price, address, Zestimates, images—Zillow embeds a lot of that inside JSON within <script> tags. If you’re serious, go dig into that next.
Pros:
- Full control over what you collect
- Free
- No waiting around
Cons:
- Breaks if Zillow updates its layout (which they do, often)
- Doesn’t scale unless you set up proxy rotation and deal with blocking
- Not for non-technical users
If you’re building a one-off tool or just need a few listings, this works. But if you’re scraping hundreds or want zero maintenance, skip to the next option.
Use a No-Code Zillow Data Scraper (If You Don’t Want to Code)
Let’s say you don’t want to write Python. Or maybe you just don’t want to waste time debugging code every time Zillow makes a change. Fair enough.
This is where no-code tools come in. A Zillow data scraper doesn’t have to mean writing scripts. Plenty of tools out there let you scrape Zillow listings just by clicking around and setting a few rules—no terminal, no IDE, no dependencies.
Think of it as point-and-click scraping.
How It Works
Most no-code website data scraping tools follow a similar pattern:
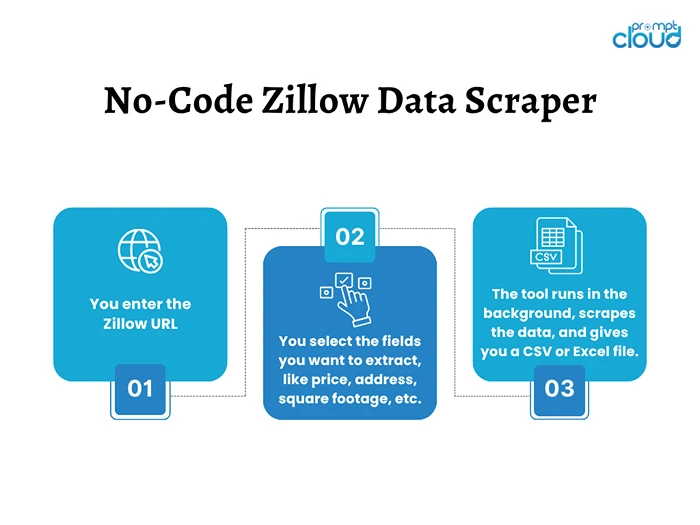
- You enter the Zillow URL (it could be a search page or a single property).
- You select the fields you want to extract, like price, address, square footage, etc.
- The tool runs in the background, scrapes the data, and gives you a CSV or Excel file.
You can set it up to scrape multiple pages, auto-scroll, or even schedule it to run daily or weekly.
Tools People Use for This
- Octoparse – Visual drag-and-drop interface. Can handle login sessions and dynamic pages.
- WebHarvy – Point-and-click with smart pattern detection.
- Apify – Offers Zillow scraping “actors” you can run in the cloud.
- Browse.ai – Great if you want to monitor price changes and get alerts.
All of them work well for basic scraping. You don’t need to install Python. You don’t need to know HTML. You just set it up once, and it runs.
Pros:
- No coding required
- Fast setup
- Ideal for small teams or individual researchers
Cons:
- Limited flexibility
- Harder to customize the data structure
- Still breaks if Zillow updates its page layout
- Some tools charge monthly fees
If your goal is to scrape Zillow a few times a week for personal use, investment research, or trend tracking, a no-code Zillow scraper can save you hours.
But if you’re thinking big, like scraping 10,000 listings across 50 cities, this will only get you so far before it hits a wall.
That’s where the final option comes in: managed scraping services that do it all for you.
Use a Managed Zillow Data Scraper
Building your Zillow data scraper is powerful, and no-code tools are easy. But they both break.
Zillow doesn’t want people scraping their site at scale, and they constantly change things—HTML structure, dynamic loading, and anti-bot measures. If you’re doing anything serious with this data—like powering a real estate dashboard, training ML models, or tracking rent trends across markets—those little script errors or browser blocks add up fast.
That’s why managed website data scraping services exist.
You don’t write code. You don’t configure scrapers. You don’t maintain anything. You just say, “I want all 3-bedroom properties listed in Austin, with price, square footage, Zestimates, and rental history”—and you get structured data on schedule. That’s it.
What a Managed Zillow Scraper Does:
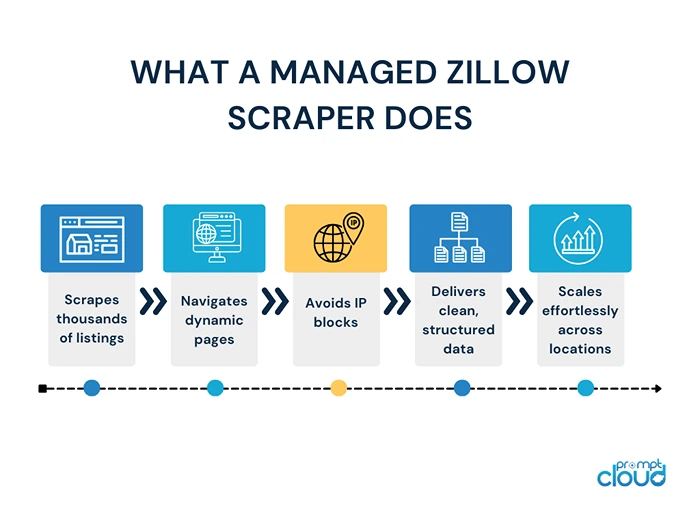
- Scrapes thousands of listings (daily, weekly, etc.)
- Navigates dynamic pages and JavaScript rendering
- Avoids IP blocks using rotating proxies
- Delivers clean, structured data (CSV, JSON, Excel, API, whatever)
- Scales effortlessly across locations and listing types
You get all the data. You do none of the dirty work.
This Is Where PromptCloud Comes In
PromptCloud is one of the few website data scraping services that handles Zillow-level complexity at scale.
They don’t just give you a scraping tool—they run the full pipeline:
- Crawl Zillow for the listings you need
- Clean and structure the data (with images, metadata, prices, addresses, Zestimates, etc.)
- Deliver it in the format and frequency you choose
It’s a fully managed Zillow data scraper that does exactly what you want, when you want it. No browser hacks. No tool limits. No blocked IPs.
And most importantly, you get reliable, usable real estate data—without lifting a finger.
Pros:
- Scales infinitely (even 100,000 listings+)
- No code, no setup, no risk
- Handles errors, structure changes, and proxy issues
- Best choice for teams, products, and platforms that need real-time Zillow data
Cons:
- Comes at a cost (because someone else handles everything)
- You’ll need to clearly define what data you want and how often
If you’re building a data-driven real estate product, running investment analytics, or need Zillow data to train your models, don’t waste time babysitting broken scripts.
Use a Zillow scraper that’s built for scale and maintained by people who know what they’re doing.
How to Choose the Right Zillow Data Scraper
Most people overcomplicate this. Choosing a Zillow data scraper comes down to one thing: what are you actually trying to do with the data?
Start there, and the right tool becomes obvious.
1. Just browsing or researching a few properties?
You don’t need anything fancy. A basic no-code tool like WebHarvy or Octoparse will do the job. These are good for simple jobs—maybe you’re comparing listings in one ZIP code or pulling a handful of prices for a report.
Downside? They break easily if Zillow changes its layout. And they’re not built for scale.
2. You’re technical and want full control?
Write your own scraper in Python using libraries like BeautifulSoup or Scrapy. You decide what gets scraped, how often, and how the output looks. If Zillow makes a small change, you update your script and keep moving.
It’s work, but you own the workflow.
Tip: Start small. Don’t build a 10,000-property pipeline on day one. Test on a few pages and scale later.
3. You need Zillow data at scale and don’t want to babysit code
This is where a managed Zillow data scraper makes sense. You tell a service like PromptCloud what you need (price, Zestimate, rent estimate, square footage, etc.), how often, and in what format. They handle the scraping, the maintenance, and the delivery.
You get data. You don’t deal with proxies, anti-bot blocks, or script failures.
If your time is valuable, this is the smart move.
Bottom line? Pick based on your use case, skill level, and how much time you’re willing to spend fixing things when they break. Because eventually—they will.

What Can a Zillow Data Scraper Pull?
If you’ve ever looked at a Zillow listing, you’ve seen how much data is packed into just one page. A good Zillow data scraper can pull most of it—if it’s built right.
We’re not just talking about the price or address. There’s a lot more under the hood.
Here’s what you can usually extract:
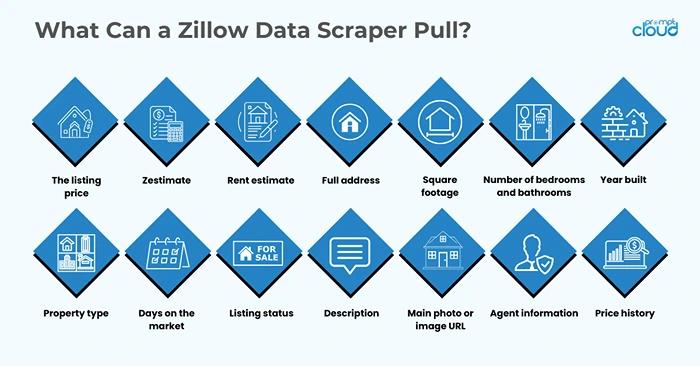
- The listing price is obvious.
- Zestimate — Zillow’s price estimate.
- Rent estimate — sometimes available on rentals or for-sale homes.
- Full address — street, city, ZIP.
- Square footage — total area of the home.
- Number of bedrooms and bathrooms — usually easy to find.
- Year built — useful for age/value analysis.
- Property type — single-family, condo, multi-family, etc.
- Days on the market — how long it’s been listed.
- Listing status — for sale, pending, sold.
- Description — usually in plain text or inside meta tags.
- Main photo or image URL — top listing image.
- Agent information — sometimes pulled from structured JSON on the page.
- Price history — in some cases, previous sale prices or drops.
Now, what you get depends on how your scraper works.
If you’re using a basic scraper or no-code tool, you’ll probably get the top-level stuff: price, address, and maybe square footage.
If you’re building your own Zillow data scraper in Python and know how to parse JSON embedded in <script> tags, you’ll get a lot more—Zestimate, rent value, structured address, etc.
And if you’re using a managed solution? Then you can pull everything—plus automate it daily, weekly, whatever. Clean, complete data with no missing fields.
The point is: that Zillow doesn’t hide its listings, but you need the right tool (and setup) to get all the useful parts.
Can You Use a Zillow Data Scraper Without Getting Into Trouble?
Here’s the deal.
Zillow puts a ton of real estate data out there for anyone to see — listings, prices, Zestimates, photos, the works. It’s all public. You don’t need to log in. So naturally, you think: “Cool, I can just scrape this, right?”
Well, not quite.
Zillow’s terms of service say you’re not allowed to use bots, scrapers, or any kind of automated tool to pull their data. So technically, yeah — if you’re scraping Zillow, you’re violating their terms.
Will they come after you? Probably not if you’re grabbing a handful of listings here and there. Will they block you if you’re hammering their site with thousands of requests per hour? Absolutely.
It’s less about what’s “legal” and more about how loud you are.
You’re probably fine if:
- You’re scraping a few listings for personal use
- You’re not touching user data or logging into anything
- You’re not overloading their servers or hitting pages 24/7
You’ll probably get blocked (or worse) if:
- You’re pulling data at scale for a business
- You’re trying to repackage or resell Zillow data
- You’re running bots without any rate limits or IP rotation
So What’s the Smart Move?
If this is just a weekend project, fine, run your own script and keep it light. But if you’re doing anything serious — a dashboard, a dataset, a PropTech tool — don’t do this half-baked.
Use a website data scraping service that knows how to stay compliant, dodge blocks, and not trigger alarms. Services like PromptCloud handle the grunt work and the legal landmines. You just get the data.
Simple.
Skip the Hassle, Get the Data
Building and running a Zillow data scraper isn’t rocket science, but it’s not painless either.
Sure, you can piece together a Python script, scrape a few listings, and call it a win. But the second Zillow tweaks its site layout, or your IP gets blocked, you’re back at square one. Multiply that by hundreds of listings or dozens of ZIP codes, and now it’s not a side project—it’s a maintenance nightmare.
And if you’re serious about real estate data? You don’t have time for that.
This is where a managed Zillow data scraping service makes sense. You stop wrestling with broken code and start focusing on what matters—tracking market trends, modeling investment opportunities, building smarter platforms, and making better decisions.
Get Zillow Data, Without the Headache
Whether you’re:
- A real estate firm tracking price shifts across cities
- A PropTech startup building rental benchmarks
- Or an analyst who needs to structure Zillow data every week
PromptCloud delivers.
We run scalable, compliant Zillow scrapers, so you don’t have to. You tell us what you need. We get you clean, ready-to-use data. Talk to us today and stop wasting time chasing down listings manually.















