




Zillow Data Scraping for Real Estate Pricing: Why Static Pricing Models Fail
Zillow data scraping is not just about collecting listings, it is about building a continuously updated pricing intelligence layer for real estate decisions. By extracting historical prices, comparable listings, and market velocity signals, teams can move from static pricing assumptions to dynamic, data-backed strategies. The real advantage comes when this data is refreshed at scale and normalized across geographies, something manual workflows cannot support. However, scraping Zillow reliably introduces challenges around blocking, data consistency, and maintenance overhead. This is where teams shift from scripts to managed data pipelines that deliver clean, structured datasets ready for pricing models and decision systems.
Pricing Still Runs on Delayed Signals
Real estate pricing continues to rely on static comps, agent intuition, and periodic reports. That model assumes market conditions change slowly. In reality, listings update daily, demand shifts quickly, and price corrections happen faster than traditional workflows can react.
This creates a structural lag between market reality and pricing decisions.
The Core Gap Is Not Data, It Is Access and Usability
Platforms like Zillow already aggregate massive amounts of property data. The issue is not availability, but how that data is consumed.
Manual browsing or one-time exports lead to:
- Fragmented datasets
- No historical continuity
- No real-time visibility
Without continuous data extraction, teams are effectively making decisions on partial and outdated signals.
Where Pricing Breaks in Practice
This gap shows up in consistent failure patterns:
- Comparable properties used for pricing are already outdated
- Price adjustments lag behind actual demand shifts
- Micro-market signals (zip code, street-level demand) are ignored
The impact is measurable:
- Longer time-on-market for overpriced listings
- Margin leakage from underpriced assets
- Poor alignment with competitive inventory
Zillow Has the Data, But Not the System
Zillow captures real-time listing behavior across markets, including pricing changes, inventory movement, and property-level attributes. However, the platform is designed for human consumption, not for systematic analysis.
Without structured extraction:
- Data cannot be aggregated across markets
- Trends cannot be tracked consistently
- Pricing models cannot be updated dynamically
Zillow Data Scraping Converts Listings Into Pricing Intelligence
Zillow data scraping bridges this gap by transforming raw listings into structured datasets that can be analyzed continuously.
Instead of:
- Checking listings manually
- Updating spreadsheets periodically
Teams can:
- Track price changes in near real time
- Build comparable sets dynamically
- Monitor supply-demand shifts at a granular level
At this point, pricing moves from static benchmarking → dynamic market alignment.
Stop unreliable Zillow data pipelines. Start making pricing decisions with confidence
Get clean, structured web data delivered on your cadence from a managed pipeline built around your specific sources and schema.
• No contracts. • No credit card required. • No scraping infrastructure to maintain.
What Zillow Data Scraping Enables for Real Estate Pricing Strategy
Comparable Intelligence That Actually Reflects the Market
Most pricing decisions rely on a small set of manually selected comparables. That introduces bias and misses market variability.
Zillow data scraping changes this by enabling large-scale comparable analysis. Instead of a handful of listings, teams can benchmark against hundreds of similar properties filtered by size, location, and recency. This improves pricing accuracy and reduces reliance on subjective judgment.
The shift here is critical. Pricing moves from representative sampling → market-level validation.
Image Source: Crawlbase
From Snapshot Pricing to Trend-Based Decisions
Looking at current listing prices is not enough. What matters is how prices evolve.
Zillow exposes signals like price drops, relisting behavior, and time-on-market. When this data is captured continuously, it reveals patterns such as how long overpriced properties take to correct or how aggressively sellers adjust in different markets.
This allows teams to price based on expected movement, not just current positioning.
Real-Time Market Awareness, Not Periodic Guesswork
Traditional pricing workflows operate on delayed updates. By the time reports are compiled, the market has already shifted.
With Zillow data scraping, teams can monitor:
- New inventory entering the market
- Price corrections across segments
- Changes in listing velocity
Localized Pricing That Captures Micro-Market Variations
Pricing differences within the same city can be significant. ZIP-level or neighborhood-level dynamics often drive demand more than city-wide trends.
Scraped Zillow data allows segmentation at a granular level, making it possible to identify:
- Undervalued pockets
- High-demand micro-markets
- Localized pricing anomalies
This is where pricing strategies become geo-intelligent instead of generalized.
Explore More
For teams building broader data pipelines beyond property listings:
- Learn how image-based extraction supports listing enrichment and visual intelligence.
- See how rental market data complements property pricing models in travel and real estate analytics.
Best Practices for Zillow Data Extraction Without Breaking Reliability
Treat Scraping as a Data Pipeline, Not a Script
Most failures happen because scraping is treated as a one-time task. In reality, Zillow data extraction needs to behave like a continuous data pipeline with monitoring, retries, and validation.
This means:
- Scheduling structured data pulls instead of ad-hoc scraping
- Tracking extraction success rates
- Logging failures and recovery cycles
Without this, data gaps go unnoticed and directly impact pricing models.
Design for Change, Not Stability
Zillow’s frontend is not static. Any scraper built on rigid selectors will break.
Reliable systems:
- Use adaptive parsing logic instead of fixed selectors
- Maintain fallback extraction rules
- Continuously test against layout changes
The key shift is assuming change is constant, not an exception.
Prioritize Data Quality Over Data Volume
More data does not mean better decisions if the dataset is inconsistent.
Critical practices:
- Normalize price formats and units
- Deduplicate listings across refresh cycles
- Validate key fields (price, location, property type)
Poor data quality leads to distorted comparables, which directly impacts pricing accuracy.
Control Request Patterns to Avoid Detection
Zillow enforces anti-bot measures that detect abnormal traffic behavior.
To maintain continuity:
- Distribute requests across IP pools
- Introduce delays and randomized intervals
- Avoid aggressive crawling patterns
However, these are not one-time setups. They require continuous tuning as detection systems evolve.
Build for Multi-Market Scalability
If your pricing strategy spans multiple cities or regions, your data pipeline must scale accordingly.
This requires:
- Parallel data collection across geographies
- Consistent schema across markets
- Centralized storage for cross-market comparisons
Without this, pricing remains fragmented and lacks consistency.
Industry Insight: Why Real-Time Data Matters
According to a study by McKinsey & Company, real estate firms that integrate real-time market data into pricing and investment decisions can improve pricing accuracy and reduce time-to-sale by up to 20–30%.
This reinforces a key point:
- The advantage is not access to data
- It is how frequently and reliably that data is updated
Where Most Teams Hit the Wall
Even with best practices, teams encounter a ceiling:
- Maintenance cycles consume engineering bandwidth
- Data inconsistencies persist across markets
- Scaling introduces infrastructure overhead
At this point, scraping is no longer a tooling problem. It becomes an operational burden that competes with core business priorities.
Why Teams Move from DIY Zillow Scraping to Managed Data Pipelines
The Hidden Cost of “Working” Scrapers
Most teams assume that once a Zillow scraper is live, the problem is solved. In practice, that is when the real cost begins. Scrapers require constant adjustments as site structures change, anti-bot mechanisms evolve, and data fields shift. What initially looks like a quick engineering win turns into an ongoing maintenance cycle that consumes time and attention.
Over time, this creates a trade-off. Engineering effort gets diverted from building pricing models and analytics to keeping extraction systems functional. The output may still look operational on the surface, but the underlying system becomes fragile and resource-intensive.
Reliability Becomes the Real Constraint
At a small scale, occasional failures in data extraction are manageable. At scale, they directly impact pricing decisions. Missing listings, delayed updates, or inconsistent data structures introduce gaps that are difficult to detect but costly in outcome.
Pricing strategies depend on continuity. If the data pipeline breaks even intermittently, the entire model begins to rely on incomplete signals. This shifts the problem from data access to data trust, which is a much harder issue to solve internally.
Infrastructure Complexity Scales Faster Than Value
As teams expand Zillow data scraping across markets, the system grows in complexity. What started as a script evolves into a distributed setup that requires orchestration, monitoring, and normalization.
This introduces a mismatch. The effort required to maintain the infrastructure grows faster than the incremental value of additional data. At this stage, teams are effectively running a parallel data engineering system that was never part of the original business objective.
From Extraction to Continuous Data Delivery
Mature teams eventually change the approach. Instead of focusing on how to scrape data, they focus on how to receive reliable, structured datasets that can be used immediately.
This shift reframes the problem. The goal is no longer extraction, but consistent delivery of clean, normalized data with defined refresh cycles. Pricing models become more stable because the input layer is no longer unpredictable.
Why PromptCloud Becomes the Preferred Model
This is where managed web scraping services become relevant. Instead of building and maintaining internal scraping systems, teams rely on external pipelines designed specifically for large-scale data extraction and delivery.
PromptCloud operates at this layer. It provides structured Zillow datasets through managed pipelines that handle extraction, normalization, and delivery without requiring internal infrastructure ownership. The focus moves away from maintaining scrapers to using data directly for pricing decisions and market analysis.
Successful real estate pricing strategies require consistent, high-quality market data across locations and time. This is the foundation of modern real estate web data.
Is Zillow Data Scraping Legal and Compliant for Real Estate Use Cases
Why Compliance Is a Ranking and Buying Concern
One of the most searched and least clearly answered questions around Zillow data scraping is legality. Decision-makers evaluating data strategies are not just asking how to scrape Zillow, they are asking whether it is compliant and safe to operationalize.
Most top-ranking pages either avoid this topic or reduce it to a generic disclaimer. That creates an opportunity to address the issue directly and improve both SEO coverage and buyer confidence.
What Zillow’s Terms Imply for Data Extraction
Zillow’s terms of service place restrictions on automated access, particularly when it interferes with platform usage or bypasses intended access methods.
In practice, this means uncontrolled scraping setups can:
- Trigger access restrictions or blocking
- Operate outside acceptable usage boundaries
- Create risk when scaled across markets
The implication is not that data cannot be used, but that how it is collected matters as much as what is collected.
Why DIY Scraping Introduces Compliance Risk
Most internal scraping setups are built for speed and extraction efficiency. They lack controls around:
- Request behavior and throttling
- Data usage boundaries
- Auditability of collection methods
This creates a gap. Even if the system works technically, it does not account for compliance considerations. Over time, this becomes a business risk rather than a technical one.
How Structured Data Pipelines Reduce Risk
A more controlled approach focuses on responsible data acquisition and usage governance.
This includes:
- Regulated extraction patterns
- Consistent data handling processes
- Clear separation between raw data collection and business usage
The goal is not just to access Zillow data, but to ensure that the entire pipeline operates within acceptable and predictable boundaries.
How to Scrape Zillow Data in 2026: From Scripts to Scalable Pipelines
What Scraping Zillow Actually Involves
At a basic level, Zillow data scraping means extracting structured property data such as:
- Listing price and history
- Property attributes (beds, baths, square footage)
- Location data
- Time-on-market and status changes
In a controlled environment, this can be done using tools like Scrapy, Selenium, or headless browsers that navigate listing pages and extract fields into structured formats like JSON or CSV.
For small-scale use cases, this works. You can pull a limited dataset, run analysis, and derive insights.
The problem starts when this moves from project-level scraping → production-level data pipeline.
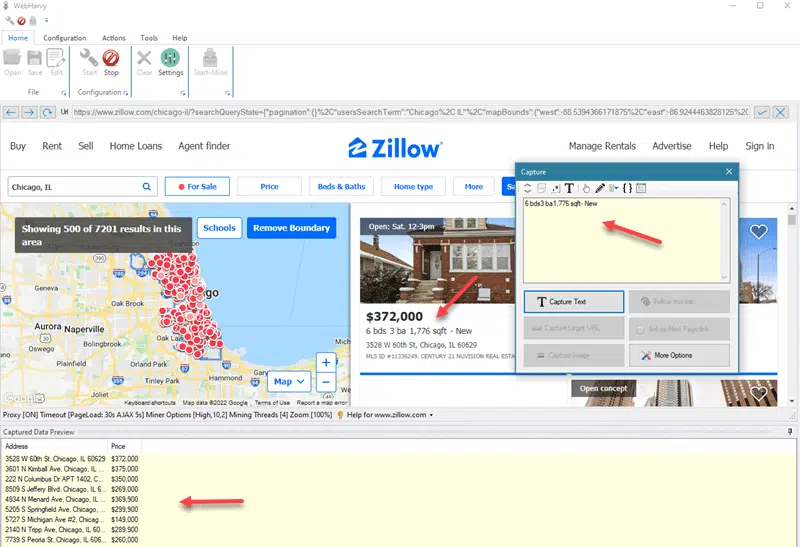
Image Source: WebHarvy
Where DIY Zillow Scraping Starts to Fail
1. Anti-Bot Protection and Blocking
Zillow actively detects automated traffic. High-frequency requests, repeated patterns, or static IP usage trigger blocks.
What this means in practice:
- Scrapers stop working without warning
- Data collection becomes inconsistent
- Teams spend time debugging instead of analyzing
Workarounds like proxy rotation and request throttling increase complexity and cost.
2. Frequent Website Structure Changes
Zillow regularly updates its frontend structure, class names, and page layouts.
Impact:
- Selectors break
- Data fields get misaligned
- Scrapers require constant maintenance
This creates a hidden operational cost. Engineering teams end up maintaining scrapers as ongoing systems, not one-time builds.
3. Data Quality and Normalization Issues
Even when scraping works, the output is rarely analysis-ready.
Common issues:
- Missing fields across listings
- Inconsistent formatting (price ranges, units, location labels)
- Duplicate or stale records
Without a normalization layer, pricing models operate on noisy data, which directly impacts decision accuracy.
4. Scaling Infrastructure Becomes a Bottleneck
To scrape Zillow continuously across multiple markets, teams need:
- Distributed scraping infrastructure
- Proxy networks
- Scheduling systems
- Storage and processing pipelines
This turns a simple scraping task into a data engineering problem.
At this stage, the real question shifts from:
“Can we scrape Zillow?”
to
“Can we maintain this reliably at scale?”
Comparison: DIY Scraping vs Managed Data Pipeline
| Dimension | DIY Zillow Scraping | Managed Data Pipeline |
| Setup | Quick to start | Structured onboarding |
| Maintenance | High (constant fixes) | Minimal (handled externally) |
| Data Reliability | Inconsistent | SLA-backed |
| Scalability | Limited | Built for multi-market scale |
| Engineering Effort | Ongoing | Near-zero internal effort |
The Shift: From Scraper to System
Most teams underestimate this transition.
Scraping Zillow is not the hard part. Keeping it running reliably, at scale, with clean data is.
This is where teams move from:
- Scripts → Pipelines
- Raw HTML → Structured datasets
- One-time extraction → Continuous data delivery
Explore More
If you are thinking beyond scraping into production-grade data systems:
- Understand how AI-ready data infrastructure supports scalable data pipelines.
- See what makes data usable for downstream models and analytics systems.
What “Scraping Zillow” Looks Like Today
In 2026, scraping Zillow is no longer about writing a simple script to extract listing pages. The platform has evolved with stronger anti-bot systems, dynamic content rendering, and stricter access controls.
At a surface level, the process still involves extracting:
- Listing prices and history
- Property attributes
- Location and neighborhood data
- Listing status and updates
But the way this data is accessed has changed. Most listing pages are rendered dynamically, which means static HTML parsing is no longer sufficient. Data extraction now requires browser-based automation or API-like interception of network calls.
Approach 1: Script-Based Scraping (Small-Scale Use Cases)
For limited datasets or experimentation, teams still use frameworks like:
- Headless browsers for rendering dynamic content
- Parsing layers to extract structured fields
- Local storage for dataset creation
This approach works when:
- You are targeting a small geography
- Data refresh frequency is low
- Accuracy requirements are not mission-critical
However, this setup breaks quickly when scaled. It lacks resilience against blocking, structural changes, and data inconsistencies.
Approach 2: Network-Level Data Extraction
More advanced setups attempt to extract data directly from network requests triggered by Zillow’s frontend.
This involves:
- Inspecting API calls made by the browser
- Capturing structured JSON responses
- Bypassing full page rendering
This improves efficiency and reduces parsing complexity. But it introduces new challenges:
- Endpoints change without notice
- Authentication tokens expire
- Access patterns are monitored and restricted
This makes the system fragile unless continuously maintained.
Approach 3: Distributed Scraping Infrastructure
At scale, teams build distributed systems that include:
- Request orchestration across multiple nodes
- Proxy rotation and traffic distribution
- Scheduling systems for continuous data collection
This allows multi-market data extraction and higher frequency updates. But it also introduces significant overhead in terms of infrastructure management, monitoring, and cost control.
At this stage, scraping is no longer a tool, it becomes a dedicated system that requires ongoing engineering support.
The Core Challenge in 2026: Reliability Over Extraction
The biggest shift in 2026 is this:
The challenge is not accessing Zillow data.
The challenge is maintaining consistent, high-quality, continuously updated datasets.
Most DIY systems fail at:
- Handling anti-bot defenses over time
- Maintaining data consistency across refresh cycles
- Scaling without exponential cost increase
This is why many teams start with scripts but eventually transition to managed pipelines.
Where PromptCloud Fits in the 2026 Stack
For organizations that need Zillow data as a reliable input for pricing models, building and maintaining scraping systems internally introduces unnecessary complexity.
PromptCloud addresses this by providing:
- Managed extraction pipelines
- Structured, normalized datasets
- Consistent refresh cycles across markets
Instead of investing in infrastructure, teams receive data that is ready for analysis and pricing decisions, without the operational burden of maintaining scraping systems.
For a reliable industry perspective on housing data, pricing trends, and market dynamics, refer to the Federal Reserve Bank of St. Louis housing data resource. This dataset tracks U.S. home price trends over time and is widely used for analyzing market cycles, pricing movements, and demand-supply shifts.
If you’re building real estate pricing intelligence systems, explore how real estate web data handles multi-market data extraction, normalization, and delivery at scale.
Stop unreliable Zillow data pipelines. Start making pricing decisions with confidence
Get clean, structured web data delivered on your cadence from a managed pipeline built around your specific sources and schema.
• No contracts. • No credit card required. • No scraping infrastructure to maintain.
Frequently Asked Questions (FAQs)
1. Can Zillow data be used for real estate pricing analysis?
Yes, Zillow data can be used for pricing analysis when it is structured and aggregated correctly. Individual listings provide limited insight, but large-scale datasets enable trend analysis, comparable benchmarking, and demand signal tracking across markets.
2. How often should Zillow data be updated for accurate pricing models?
For active markets, pricing models should be updated at least daily or near real-time. Weekly updates introduce lag, especially in high-demand areas where listing prices and inventory levels change frequently.
3. What are the most important Zillow data points for pricing strategy?
The most critical data points include listing price, price history, time-on-market, property attributes, and location-level signals. Combining these allows teams to model both current positioning and expected price movement.
4. Why do Zillow scraping projects fail when scaled across multiple cities?
Most projects fail due to infrastructure limitations, anti-bot restrictions, and inconsistent data formatting across regions. As coverage expands, maintaining reliability and data quality becomes significantly more complex than initial extraction.
5. What is the alternative to building an in-house Zillow scraping system?
The alternative is using managed web data services that provide structured, continuously updated datasets. This removes the need for internal infrastructure, reduces maintenance overhead, and ensures consistent data quality across markets.















