




Artificial intelligence and machine learning are valid if they are based on data. High-quality data is the foundation for everything from a chatbot to a recommendation engine to a real-time forecasting model. That is where web scraping comes into play.
Web scraping consists of programmatically retrieving data from websites. In terms of applications for AI and ML, this method grants access to a vast number of real-time domain-specific structured pieces of information from datasets that public sets cannot usually provide. Models in need of massive, diverse, and up-to-date datasets rely on web scraping to support availability.
In this article, we look into the many web scraping applications that help develop and improve AI and Machine Learning systems. From building training data to tracking consumer sentiment, you’ll find that web scraping translates to smarter and more precise models.
Why Web Scraping is Critical for AI & Machine Learning
AI and ML systems are incredibly voracious for data. To come up with meaningful predictions, to identify patterns, or to understand human language, these models require very large volumes of clean, relevant, and often variegated data. While there are indeed free datasets that pop up in some corner of the Internet, at times, they may not quite work toward the varying requirements of new-age AI applications.
Limitations of Public Datasets
Public datasets like Kaggle or government portals might get you going on a project. But on the flip side, they usually come with these drawbacks:
- They are often outdated. Most public datasets serve as a snapshot in time, capturing sentiments and price levels that may have long ceased to be relevant.
- They lack granularity. For many use cases, public datasets may not cover niche domains or lack fine-grained labels.
- They are not customizable. You get what you get, even if you need a few more fields, formats, or frequencies.
Here lies the real power of web scraping. Data scientists and ML engineers rely on the endless and ever-growing content available on the web to gather custom datasets that fit squarely into their requirements.
How Web Scraping Benefits AI Workflow
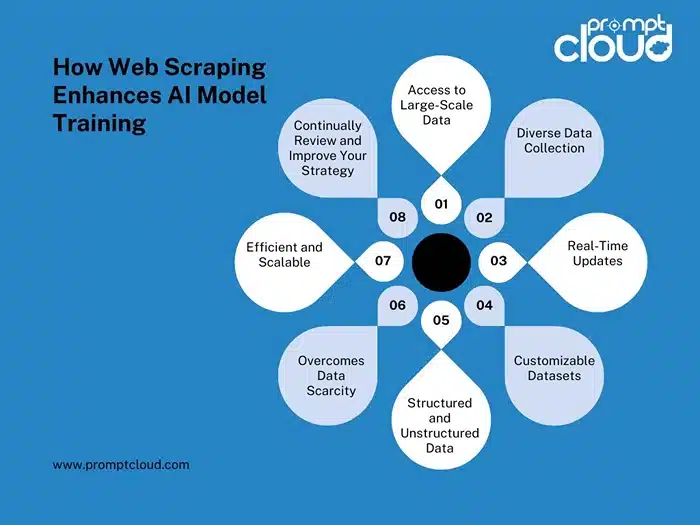
Web scraping would enable you to:
- Individually target and scale data collection from ecommerce, healthcare, or finance domains, or social platforms.
- Make datasets that continuously update themselves for real-time ML systems.
- Collect data across languages, media forms, or sources, enriching model inputs.
And even greater flexibility. The real advantage arises when you start to build.
The actual winning point is the flexibility. Web scraping lets a team gather the data they need to build the right model, be it for a machine translation model needing thousands of product descriptions or for a fleecing AI assistant with stock news.
In short, web scraping use cases have almost gone from being nice-to-haves to being front-and-center in modern AI development, where data can be smartly gathered, refined, and applied by teams.
Common Web Scraping Use Cases in AI & ML
The use cases for web scraping in AI and machine learning are never-ending and ever-changing-from producing labeled training datasets to real-time application and prediction on an AI system operating on dynamic real-world data. Let us examine some of the more important use cases of web scraping in AI and ML workflows.
1. AI Training Data Generation
Every AI model begins with training data. The more good-quality, labeled samples one has, the better the model will be. Web scraping allows developers to obtain gigantic amounts of raw data in various formats-text, images, products, and more.
For example, if you were trying to develop a sentiment analysis model, scraping product reviews or customer comments from ecommerce sites could quickly provide you with thousands of labeled instances. In another instance, if your model needs to classify news into categories, scraping headlines and full articles from media portals offers real-time training material.
Without web scraping, it would almost be too difficult or expensive to source such huge volumes of relevant, up-to-date, and contextual data.
2. Sentiment Analysis and NLP Models
NLP models mostly deal with textual data. Whether we talk about opinion mining, emotion detection, or social listening, web scraping offers a rich language dataset mirroring how people actually talk and write.
Social media platforms, discussion forums, blogs, and customer review sites constitute a treasure trove for real-time sentiment tracking. In political analysis, Twitter data scraped through bots on a large scale helps understand public opinion. In-marketing, companies look at product reviews for customer satisfaction metrics. In AI, forum threads, comment sections, etc., serve as human dialogue corpora for building and training conversational agents.
The above-listed uses of Web scraping serve as essential activities in building models that not just comprehend the language but also the tone, intent, and emotions attached to it.
3. Price Monitoring and Forecasting in Real Time
Price is arguably the most ever-changing data point on the internet today. A price on an e-commerce platform or that of a hotel booking site gets changed ad hoc depending on demand, seasonality, and competitor behavior.
Machine learning models built on pricing data scraped from the internet can aid a company to dynamically price their products or look at price trends for the near term. An airline might, for instance, scrape competitor prices through its own website and adjust its fares in real-time. A retailer might use ML to train the best time to discount for a product using historical price data scraped from product pages.
Without scraping data from the internet, one would have to integrate at a high price for acquiring such granular and frequent pricing data, or it just would not be possible.
4. Financial & Market Intelligence
In finance, timing and information are everything. AI models in this domain often depend on real-time news, stock tickers, regulatory filings, and macroeconomic indicators. Scraping financial news sites, investor portals, and government publications can help build powerful predictive models.
This would involve scraping press releases and corporate announcements that serve as input to ML models that do credit risk scoring or stock movement prediction. Hedge funds and investment analysts use automated scraping tools to keep a step ahead of market shifts.
Such AI web scrapers give ML systems the ability to spot trends from unstructured financial data, thereby bringing a very helpful advantage to the table where the stakes get really high.
5. Healthcare & Medical Research
Web scraping is also streamlining the medical research and healthcare AI landscape. Medical journals, clinical trial databases, health forums, and patient Q&A websites all form an information base that can train diagnostic models or improve medical language models.
A typical use case might be scraping scientific papers from research portals and feeding them into a machine learning model that classifies diseases by symptoms. Else, scraping patient discussions from health forums can aid in detecting the onset of side effects or reactions to treatments.
In an area where labeled medical data is difficult to obtain, web scraping assists in unlocking datasets useful for academic research and applied fields in healthcare AI.
6. Retail & Consumer Behavior Modeling
Today, online retailers rely on AI-based personalization and recommendation engines to enhance user experience and increase sales. These require the behavioral data of customers, i.e., what they browse, click on, review, or abandon
Web scraper tools can build datasets by extracting product listings, user reviews, category hierarchies, and promotional strategies from competitor sites. This can then be used for training ML models for consumer segmentation, product recommendation, personalization, or inventory planning.
This kind of web scraping use case gains significance in e-commerce, where customer behavior evolves by the minute and data has to be refreshed nearly in real time.
7. Image Recognition and Computer Vision
AI models in computer vision usually require at least millions of labeled images for the learning of visual patterns. Although there exist some public datasets, such as ImageNet, they are not always suited to your specific needs.
This is where web scraping is desired to develop your own domain-specific image datasets. For example, scrape fashion product images with tags to train a model to recognize clothing styles. Scrape images of vehicles, machinery, or signage from public directories to help create object detection systems.
Besides scraping the raw images, scraping any associated metadata such as alt text, caption, or product-name etc. would be helpful since they provide natural labels for training.
How AI Web Scraping Works: Converting the Web into Consumable Data for AI
Having put forth various uses of web scraping in AI and ML, it becomes essential to understand the workings of web scraping-almost every time, done at a large scale and for AI applications.
Web Scraping Technical Flow for AI
Normally, web scraping follows a multi-step procedure to efficiently collect data and structure it:
- Crawling: Crawling is the phase where a software program (called a crawler or spider) scrapes the web for websites and discovers new URLs to scrape. For AI purposes, crawlers are often customized to climb through deep site structures and relevant-content paths.
- Parsing: The HTML content is collected, and the scraper proceeds with parsing the contents to extract the fields of interest, be it text, images, metadata, or links; late parsing is done with HTML parsers or browser automation tools, depending on the webpage complexity in question.
- Cleaning & Structuring: This is basically the elimination of noise from the raw scraped data. This noise could be advertisement banners, formatting tags, such as incomplete entries and so on. Cleaning removes these inconsistencies, while structuring arranges the data into CSV, JSON, or XML formats that can now be ready for use into machine learning pipelines.
- Deduplication & Validation: You certainly do not want duplicates and wrongly entered data in your dataset, especially for AI! Hence, scraping data is validated against quality rules to ensure data integrity and relevance.
Behind the Scenes: Automation and Infrastructure
Scalable web scraping often implies:
- Automation Tools: Headless browsers and scripting languages make for simulating user behavior to actually scrape dynamic content.
- Rotating Proxies & User Agents: To thwart sites’ anti-bot measures, scrapers keep on lagging between IP addresses and user agents, so as to pass as legitimate traffic.
- Scheduling & Monitoring: For real-time AI applications, scrapers are scheduled to go and scrape for fresh or updated content on a regular basis.
PromptCloud Scraping-as-a-Service
At PromptCloud, we provide a fully managed web scraping service. Here’s how we simplify or ease your work:
- Custom Scraping Pipelines: Crawlers are built to meet your specific data needs-whether targeting certain sites, content types, or languages.
- Structured Output: Scraped data is neatly formatted in JSON, XML, or CSV formats, ready for use in either the current or the next phase of model training.
- Real-time and Batch Feeds: Whether it’s a single data set for training a model or numerous feeds to provide real-time refresh of data, we’ve got you covered.
- Multilingual and Multimedia Support: Text scraped in various languages? Product images, videos? We are proud of providing even multimedia and multilingual extraction that enhances your AI inputs.
With PromptCloud, you no longer need to have any concerns about infrastructure, maintenance or challenges associated with web scraping. We want you to focus on creating intelligent AI instead of parsing raw data. Contact us today!
Challenges in Web Scraping for AI and What to Watch Out For
While scraping information off websites is an important resource for sustenance of AI and machine learning, it does confront quite a few difficulties. For intelligent systems’ design teams, knowing these limitations is equally of paramount importance as collecting the data itself. Let us go through the major challenges of using scraping in AI, and why they matter.
Data Quality and Consistency
One major hurdle is keeping scraped data consistent and of good quality. Websites differ in structure, and a small change in layout suffices to break a scraping script. Providing this type of inconsistent/ incomplete information to an AI model introduces noise and hence it actually taints the accuracy of the model.
That is why scrapers must be updated and monitored regularly in order to provide consistent outcomes; this is particularly relevant for AI applications where models’ performance relies on data being current and correct.
Anti-Bot Systems and Site Restrictions
Many websites set up anti-scraping measures such as CAPTCHA, rate limiting, and IP blocking. They want to detect and prevent access of content by bots too frequently or effortlessly.
Scraping for AI purposes, particularly on a big scale, practically calls for circumventing such restrictions through the means of proxy rotations, user-agent spoofing, and intelligent throttling of requests. Without these, interruptions may occur in your data pipeline, causing delays to training or update of the model.
Legal and Ethical Considerations
Not all information online is free to be scraped. Some websites forbid automated access in their terms of service or through robots.txt files. There are also laws such as GDPR and CCPA regulating the manner in which personal data can be collected and stored. Then, of course, consideration must be given to laws pertaining to jurisdictions in which the parties operate.
Compliance, especially pertinent to sensitive areas like healthcare, finance, or user behavior, is of utmost importance. Hence, it is imperative to engage in ethical practices when scraping the web, such as respecting site terms, anonymizing data, and refraining from the use of personal identifiers.
Data Labeling and Annotation
Raw scraped data is usually sterile for an AI model. It usually lacks labels for supervised learning requirements. For example, if you scrape thousands of customer reviews, you first need to label them by sentiment before feeding them to the sentiment analysis model.
Labeling and annotation consume time and require expertise. In a few cases, scraping solutions do provide pre-structured or semi-labeled content (like tags, ratings, or product categories), but most of the times, additional data preparation is a considerable investment.
Domain-Specific Relevance
General scraping hardly works. AI models take domain-specific, context-rich data. Scraping without knowing the importance of the source might result in obtaining content that is entirely off-topic or counterproductive in its utility.
For example, a healthcare NLP model will barely get anything good out of scrubbing general news articles; it seeks structured medical texts, patient queries, and clinical reports.
Web Scraping Is the Backbone of Smarter AI
Artificial intelligence and machine learning require fresh and high-quality data, and the best way to gather data is to scrape data from the web. Whether it’s teaching NLP systems or providing real-time analytics, web scraping is therefore a very wide but essential part of AI.
Public datasets may not be sufficient. Web scraping lets you collect exactly the data your models require. PromptCloud, however, provides that data in a neat, formatted structure prepared to go, so one never has to worry about data structuring again.
Do you need a reliable data source for your AI project? Contact PromptCloud to get a custom web scraping solution to fit your goals.















