




Think of AI training data as the fuel that powers an engine. No matter how advanced your algorithms are, they won’t go far without the right data behind them. Just like a child learns by observing the world, an AI model learns patterns and makes decisions by being fed large volumes of data—data that needs to be clean, diverse, and accurately labeled.
This is especially important in today’s world, where AI is being used across everything from healthcare diagnostics to voice assistants and recommendation engines. But there’s a catch: AI models don’t just need any data. They need high-quality, well-structured, and representative data to perform accurately and avoid making costly mistakes.
In fact, according to a report by VentureBeat, up to 80% of a data scientist’s time is spent collecting, cleaning, and organizing data rather than building models. That tells you just how important the training data stage is.
In this guide, we’ll walk through the entire process, from understanding what AI training data sets are to learning how to source, clean, and optimize them. We’ll also cover common challenges and how to solve them, with a special focus on practical steps that AI engineers, machine learning specialists, and data scientists can implement in real-world projects.
What Are AI Training Data Sets and Why Do They Matter So Much?
Let’s clear up something right at the start—AI training data isn’t just a bunch of numbers or random files. It’s the stuff that actually teaches an AI model how to think, respond, and make decisions. Without it, your model is basically guessing.
When people talk about training an AI, what they really mean is showing it a whole lot of examples so it can spot patterns and learn from them. Those examples are bundled into what we call AI training datasets. These sets are made up of inputs (like images, sentences, or sensor readings) and, often, the correct outputs (like “this is a cat” or “this is spam”).
So, if you’re building a chatbot, your training data might include thousands of conversations. If you’re training a model to recognize faces, you’ll need tons of labeled images. The better and more diverse the data, the smarter the model gets.
Now, not all training data looks the same. You’ll usually hear people talk about two broad types:
Structured vs. Unstructured AI Training Data
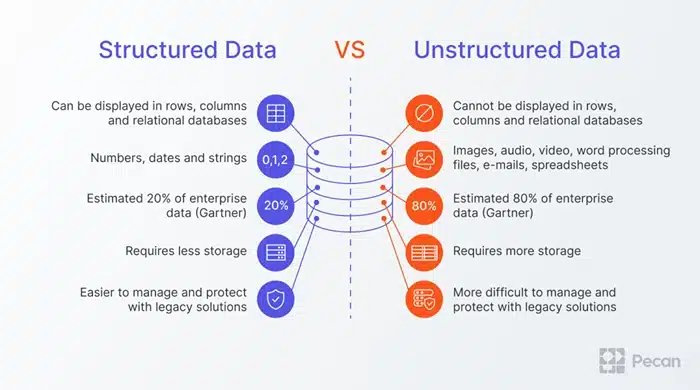
Image Source: Pecan AI
Structured data is neat and organized. Think spreadsheets or tables in a database—each row has a place, each column has a label. You’ll find this kind of data in finance, retail, or sales tracking. It’s easy to work with and great for models that predict numbers or categories.
Unstructured data is more like the wild west. It includes things like emails, videos, audio recordings, customer reviews, or social media posts. It’s messier, but it’s also incredibly rich. For example, training a generative AI model, like one that writes text or edits images, usually requires a ton of this unstructured content.
Here’s the key thing: It doesn’t matter how fancy your algorithm is—if your data is low quality, your AI won’t perform well.
Models trained on poor or biased data can make inaccurate decisions or even reinforce harmful stereotypes. That’s why people working in AI put so much effort into building the right data sets before ever touching a line of model code.
Alright, now that you know what AI training data sets are and why they matter, let’s look at where to actually find them.
How to Source AI Training Data
Finding good AI training data isn’t just a box you check—it’s one of the most important parts of building a solid AI model. But sourcing it? That’s where a lot of teams get stuck. The data might not exist in the format you need. It might be hard to get access to. Or, in some cases, you’re not even sure if using it is allowed.
Here’s a breakdown of the most common ways people source AI training data sets, and what actually works in the real world.
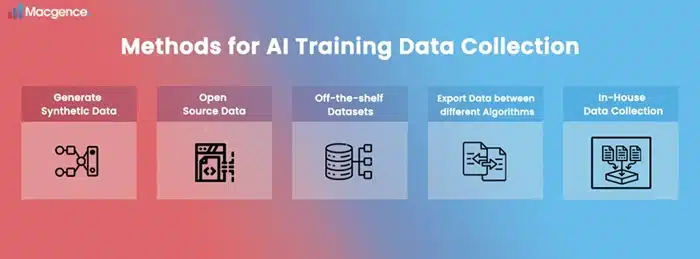
Image Source: Macgence
Use Web Scraping to Build Custom Datasets
A lot of valuable data is out there on the open web—it just isn’t sitting in tidy files waiting for you. That’s where web scraping comes in. It lets you pull information from websites at scale, turning unstructured content like product listings, job ads, or reviews into something you can feed into a model.
For example, if you’re training an AI to understand customer sentiment, scraping reviews from e-commerce sites gives you thousands of real-world examples—fast.
This is one of the areas where PromptCloud really comes in handy. We handle large-scale, fully customized web scraping. That means you don’t need to spend weeks building your own scraping tools or worrying about blocking and throttling. You say what kind of data you need; we deliver it in a structured format.
Of course, not all websites are fair game. Some have legal restrictions or don’t allow scraping at all. So if you’re using web scraping for AI data training, make sure you’re doing it ethically and in line with the terms of service.
Tap Into Public Datasets
Public datasets are everywhere, and they’re great if you’re testing ideas or building early prototypes. Sites like Kaggle, Hugging Face, and academic repositories have datasets for everything from natural language tasks to computer vision.
The downside? Everyone has access to them. That means your model isn’t going to be learning anything your competitors aren’t. These datasets also tend to be generic, and they may not reflect your specific use case or audience.
Still, if you’re getting started or want to benchmark a model before investing in custom data, they’re worth a look.
Use the Data You Already Own
If your business already collects user data—site behavior, transactions, customer interactions—that’s a goldmine for training AI. You don’t always need to look outside. Some of the best training data is already sitting in your logs, CRMs, or support tickets.
Of course, this comes with responsibility. If your data includes personal information, you’ll need to clean it up, anonymize it, and make sure you’re not violating privacy rules. But proprietary data is often more useful than public data because it reflects your real users and real problems.
Generate Synthetic Data When Real Data Isn’t an Option
Sometimes, getting real-world data is too expensive—or just not possible. In those cases, synthetic data can be a great workaround. It’s basically fake data that’s generated to simulate real conditions. You see this a lot in training models for robotics, autonomous driving, or even chatbots.
The trick is to make sure it’s realistic enough to be useful. If it’s too simple or too perfect, your model won’t be ready for messier real-world inputs.
Synthetic data isn’t always a replacement for real data, but it can fill in gaps or boost the size of your dataset if you’re low on examples.
Don’t Skip the Legal Concerns
Here’s the part people tend to ignore until it becomes a problem. If you’re scraping or collecting data that wasn’t originally created for your use, you need to think about copyright, consent, and data protection laws. Especially if there are people involved—like user reviews or chat logs—you’ve got to be careful.
It’s not just about being safe legally. It’s about building AI systems you can trust. Bad data practices lead to bad models, full stop.
Preparing AI Training Data for Model Training (Where the Real Work Begins)
Once you’ve sourced your AI training data—whether scraped, collected, bought, or generated—you’re not done. Not even close. Raw data is rarely clean, complete, or ready to use. And if you skip the prep stage, your model will pay for it.
Preparing your data is one of the most time-consuming steps in any machine learning project, but it’s also one of the most important. The saying “garbage in, garbage out” exists for a reason—if your data’s a mess, your model will be too.
Let’s walk through what it actually means to get your AI training data sets into shape.
Image Source: EWeek
Start by Cleaning the Data
You’d be surprised how often AI models are trained on flawed data—duplicate records, missing fields, incorrect labels. Cleaning it means going through your dataset and checking for things like:
- Duplicates: These can skew your model’s learning, especially if the duplicates lean in one direction (like all positive reviews).
- Missing values: You either need to remove these records, fill them in with estimated values, or mark them properly so your model doesn’t misinterpret them.
- Formatting inconsistencies: One source might use “CA” for California, another might use “Calif.” That sort of thing adds noise your model can’t learn from.
This step isn’t glamorous. But skipping it means building on a shaky foundation.
Annotate and Label the Right Way
If your data isn’t labeled, your model can’t learn what it’s supposed to do. And poor labeling leads to poor performance, even if the data itself is good.
How you label depends on what you’re training your model to do. For example:
- A sentiment analysis model needs text labeled as positive, negative, or neutral.
- An image classifier needs each image marked with what it contains—like “cat,” “dog,” or “tree.”
- A chatbot model might need conversations broken into intent and response segments.
You can label data manually (slow but accurate), semi-automatically (with some help from pre-trained models), or outsource it to specialized labeling platforms. Whichever route you take, consistency matters more than anything else. One mislabeled batch can throw everything off.
Make Sure the Data Is Diverse
Bias is one of the biggest problems in machine learning, and it often comes from the data.
Let’s say you’re training a facial recognition system, and 90% of your image data is from one demographic. Your model will struggle to perform well on anyone outside that group. It’s not a model problem—it’s a data problem.
To avoid this, look closely at how representative your AI training data sets are. Do they reflect real-world variation? Are they too skewed toward certain groups, topics, or outcomes?
Diverse data helps your model generalize. Without it, you’ll end up with something that performs well in testing, but fails in real use.
Watch Out for Bias in Labeling Too
Data bias doesn’t just come from what’s collected—it also comes from how it’s labeled. Humans doing the labeling bring their own assumptions, consciously or not. This can be especially tricky in areas like content moderation or sentiment analysis, where interpretation isn’t always clear-cut.
One way to reduce this risk is to define clear annotation guidelines and stick to them. Another is to have multiple labelers cross-check a portion of the data, so no single person’s bias dominates.
Optimizing AI Training Data for Better Model Performance
Let’s say you’ve collected your AI training data, cleaned it up, and labeled it properly. That’s a solid foundation—but if you stop there, you’re probably leaving performance on the table. Optimization is where good datasets become great ones.
This is especially important if you’re trying to get the most out of limited data, reduce training costs, or improve generalization in real-world scenarios. Let’s talk about how to squeeze the most value out of your AI training data sets without just throwing more data at the problem.
Use Data Augmentation to Boost Variety
Sometimes the problem isn’t too little data—it’s too little variety. Your model might overfit, which basically means it memorizes the training data instead of actually learning how to generalize. This is where data augmentation helps.
In computer vision, this might mean flipping or rotating images, adjusting brightness, or zooming in slightly to create new variations. For text data, augmentation can mean swapping in synonyms, rephrasing sentences, or injecting noise to simulate typos.
It’s not about tricking the model—it’s about preparing it for the messy reality of actual users and unpredictable inputs.
The key is to augment just enough to improve robustness without making the data unnatural. Go overboard, and your model might learn from patterns that don’t matter.
Enrich the Data with External Context
Sometimes your raw data doesn’t tell the full story. Let’s say you’re training a recommendation engine for e-commerce. Purchase history alone is useful, but what if you could also bring in data about product reviews, seasonality, or regional trends?
That’s enrichment—taking your existing dataset and layering on extra context. Web scraping can help here, especially if you want to pull in fresh content from competitor sites, forums, or marketplaces. PromptCloud’s data solutions can automate this, giving you structured data from live web sources without building your own scraping infrastructure.
Enrichment helps your model make smarter predictions because it sees more of the picture.
Balance Data Volume with Quality
Here’s a hard truth: More data doesn’t always mean better results. In fact, too much low-quality data can hurt performance more than it helps. What matters more is the right data.
Instead of chasing massive datasets, ask yourself:
- Are all the key scenarios covered?
- Are edge cases included?
- Is there enough variety across inputs?
Sometimes, trimming a bloated dataset or replacing noisy data with higher-quality samples can improve training outcomes. This becomes especially important when model training costs are high, like in deep learning or large language models.
Keep Your Data Fresh
AI models don’t just need a great dataset once—they often need continuous updates. If your model works in a fast-changing domain (news, product catalogs, job listings, etc.), stale data can become a real problem.
For example, an AI model trained on job descriptions from 2022 won’t reflect the skills or keywords trending in 2025. The same goes for models working in areas like pricing, product classification, or real-time recommendations.
This is where having a repeatable data pipeline makes a difference. Whether it’s pulling fresh data from internal systems or scraping updated content from the web, you want to build data updates into your workflow, not treat them like a one-off task.
Monitor Model Performance and Loop That Back Into Data
A powerful way to optimize your AI training data sets is to use your model’s own feedback. If it consistently performs poorly in certain areas, it could mean your dataset is underrepresenting those cases.
Let’s say your NLP model does great on formal language but fails on slang. Instead of retraining it from scratch, go back and source or generate more examples of informal text. You’re basically teaching it what it missed the first time around.
This loop—model training → performance review → data adjustment—is what leads to real gains. Great AI systems aren’t built all at once; they’re tuned over time with better, smarter data.
Challenges in AI Training Data (and How to Overcome Them)
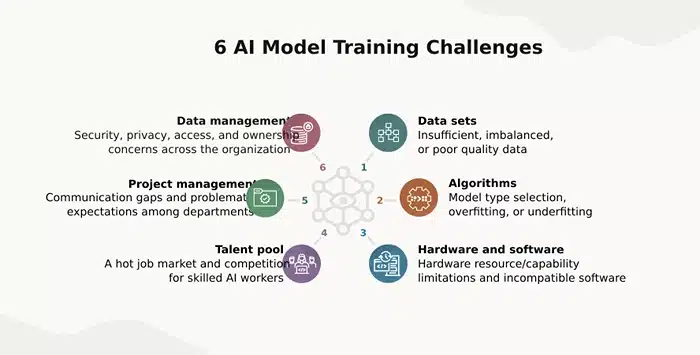
Image Source: Oracle
Building AI models sounds exciting—until you hit the wall of real-world data problems. Even the most carefully planned projects run into issues that slow things down, mess with accuracy, or make your models behave in ways you didn’t expect.
The truth is, the biggest challenges in AI often don’t come from the algorithms—they come from the data. Let’s look at some of the most common problems you’ll face with AI training data and how to deal with them without pulling your hair out.
Bias in the Data (The Silent Saboteur)
Bias is sneaky. It hides in your data without announcing itself—and then shows up in your model’s decisions.
It can come from several places:
- Historical imbalances (e.g., more male than female resumes in a hiring dataset)
- Overrepresented categories (like more photos of light-skinned faces than darker ones)
- Human labelers are unintentionally applying subjective judgment
The result? Your AI model becomes unfair, skewed, or just plain inaccurate for some users.
To fight this, start by analyzing your dataset distributions. Who or what is being over- or underrepresented? Once you spot patterns, rebalance them. You can also introduce bias-detection tools or cross-check predictions for certain groups.
And remember—bias can’t always be removed completely, but it can be reduced through better data choices.
Inconsistent or Poor-Quality Labels
Even high-quality data becomes useless if it’s labeled inconsistently. If two labelers interpret “sarcastic” differently in a sentiment dataset, your model ends up confused.
Inconsistencies often happen when:
- Guidelines are vague or nonexistent
- Multiple annotators work on the same dataset without alignment
- Labels are reused from a previous project with different goals
The fix? Clear, detailed labeling instructions. Think of them like coding standards—consistency matters. Also, use audits: review a sample of labels regularly and retrain labelers if needed.
If you’re dealing with very subjective labels (like emotion detection), consider having multiple annotations per item and using a consensus score.
Data Scalability (The Growing Pains)
It’s one thing to manage a dataset of 10,000 records. It’s another to work with 10 million. As your AI data training needs scale up, so do the challenges—storage, version control, quality checks, and speed all become bigger concerns.
Some teams try to brute-force their way through, but manual handling won’t cut it in the long run.
The solution is automation. Build a pipeline that can:
- Automatically ingest new data
- Clean and format it consistently
- Tag or label using standardized rules
- Store it in a way that supports versioning and auditing
You don’t need to build everything from scratch. Tools like PromptCloud can automate large-scale data collection and processing, especially when it comes to real-time data sourced from the web.
Privacy and Legal Risks
Another challenge that’s easy to overlook—especially when scraping or sourcing public data—is compliance. Privacy regulations like GDPR and CCPA can restrict how data is collected, stored, and used.
Even public web data may be protected depending on its intended use or how it was obtained. Using AI training data that includes personal information (like names, addresses, or medical info) without the right consent can land you in serious trouble.
Always:
- Understand the terms of use of any data source
- Anonymize sensitive data before training
- Consult legal teams when building datasets from external platforms
When in doubt, use licensed or consented datasets, or generate synthetic data that mimics patterns without using real identities.
No AI system is perfect, but most bad models aren’t the result of bad algorithms—they’re built on flawed data. The good news is that once you know what to look for, you can fix a lot of these issues before they affect production.
Why Better AI Training Data Starts with Better Data Practices
At the heart of every powerful AI model—whether it’s recommending content, predicting demand, or generating human-like text—is one key ingredient: high-quality AI training data. The model’s architecture matters, sure. But without the right data, even the most advanced system will fall short.
So what have we learned?
First, understanding what AI training data is and the types it includes (structured vs. unstructured) lays the foundation. Then comes sourcing—through web scraping, public datasets, synthetic data, or proprietary assets—done legally and ethically. From there, careful preparation, cleaning, and annotation ensure your model sees the right signals instead of noise.
But it doesn’t stop at clean data. Optimization techniques—like augmentation, enrichment, and continuous updates—are what keep models competitive and accurate over time. And of course, being aware of common challenges like bias, scalability, and label inconsistencies gives you a head start on solving them.
If you’re serious about building or scaling AI systems, your data strategy can’t be an afterthought. It needs to be a core part of your approach.
This is where PromptCloud can help.
We specialize in sourcing large-scale, high-quality data through web scraping and customized data delivery pipelines. Whether you need fresh product listings, job data, reviews, or real-time content from across the web, we deliver clean, structured data tailored to your training requirements.By partnering with PromptCloud, you get more than just raw data—you get a reliable, ethical, and scalable foundation for your AI training data sets. Schedule a FREE demo!















