




Web Scraping Challenges
Web scraping stands as a critical method for data extraction, empowering businesses and individuals to gather valuable information from multiple online sources. Despite its utility, the process involves several challenges that make it complex and often difficult to do web scraping without getting blocked.
Web scraping, while valuable for data extraction, poses several challenges due to its impact on server loads and potential legal implications. Common obstacles include:
- IP Blocking: Websites may detect multiple requests from the same IP and block it.
- CAPTCHAs: Automated tests to differentiate between human users and bots can hinder scrapers.
- Dynamic Content: Pages that load content dynamically via JavaScript can complicate data extraction.
- Legal Restrictions: Violations of terms of service can result in legal actions or bans.
- Anti-scraping Mechanisms: Techniques like rate limiting and honeypot traps are employed by websites to thwart scraping efforts effectively.

Image Source: AIMultiple
Understanding the Common Causes of Blocks & Bans
Organizations and websites often deploy various measures to protect their data and server resources. Common causes of blocks and bans include:
- Excessive Request Rates: Sending too many requests in a short period can trigger rate limits.
- IP Address Issues: Repeated access from a single IP can lead to temporary or permanent bans.
- User-Agent Detection: Identifying non-human traffic through user-agent strings often results in blocks.
- Suspicious Patterns: Irregular access patterns, like accessing different pages simultaneously, may raise red flags.
- HTTP Header Discrepancies: Mismatched or missing HTTP headers can signal bot activity.
- JavaScript Blockers: Failure to interact with JavaScript elements, often necessary for legitimate users.
Effective Web Scraping Techniques to Avoid Getting Blocked
Using Proxies Effectively to Avoid Detection
Employing proxies is crucial for conducting web scraping without getting blocked. Utilizing a rotating proxy service can help distribute requests across multiple IP addresses, masking the scraper’s identity. Data experts advise using residential proxies due to their higher reliability and lower risk of being blocked. Key strategies include:
- Diversifying proxy providers to prevent dependency on a single source.
- Regularly updating the pool of IP addresses to stay ahead of detection tools.
- Implementing request throttling mechanisms to mimic human browsing behavior.
These techniques collectively minimize the risk of triggering anti-scraping measures on target websites.

Image Source: AIMultiple
Rotating User Agents and IP Addresses
Rotating user agents and IP addresses is crucial for evading detection while web scraping. Web servers often monitor incoming requests and flag suspicious patterns. Using a pool of IP addresses and rotating them ensures that requests appear to originate from various locations, reducing the risk of getting blocked.
Similarly, rotating user agents—strings that provide information about the client software—further disguises scraped requests. Tools like proxy services and libraries designed for user-agent rotation can facilitate these practices. For example, one might integrate solutions such as Scrapy-UserAgents and proxy management services like Crawlera or Bright Data.

Image Source: privateproxy.me
Implementing CAPTCHA Solving Techniques
Implementing CAPTCHA solving techniques necessitates an in-depth understanding of various CAPTCHA systems and their underlying mechanisms. Data experts recommend using advanced machine learning algorithms to develop automated solvers. Tools like Optical Character Recognition (OCR) can decode text-based CAPTCHAs, while Convolutional Neural Networks (CNNs) handle image-based ones. Key points include:
- Data Collection: Gather a dataset of CAPTCHA samples.
- Algorithm Training: Train models on the data.
- Ethical Use: Ensure compliance with legal guidelines.
- Proxy Usage: Rotate proxies to avoid detection.
Such techniques, when properly implemented, facilitate efficient web scraping without getting blocked.
Respecting Website’s Robots.txt and Terms of Service
Adhering to the website’s robots.txt file and its terms of service is essential to ethical web scraping. The robots.txt file indicates which parts of the site can be crawled by web robots. Data professionals should:
- Regularly check the robots.txt file.
- Identify any restricted areas.
- Adjust their scraping scripts accordingly.
- Review the website’s terms of service for additional restrictions.
These practices ensure compliance and protect the scraper from potential legal consequences. Ethical conduct also promotes a respectful relationship between data extractors and website administrators.
Advanced Techniques for Throttling and Rate Limiting
Data experts recommend sophisticated methods to manage throttling and rate limiting effectively during web scraping. Implementing exponential backoff algorithms can ensure the scraper reduces its request rate in response to encountering rate limits.
Additionally, randomizing delays between requests helps mimic human behavior and avoid detection. Leveraging multiple IP addresses via proxy rotation prevents IP-based blocking. Combining these approaches with adaptive learning, where the scraper monitors server responses and adjusts actions dynamically, further enhances evasion techniques. Utilizing services like CAPTCHA solvers can also aid in overcoming more stringent security measures efficiently.

Image Source: tibco.com
Leveraging Headless Browsers for Stealth Scraping
Utilizing headless browsers offers a sophisticated method for conducting data scraping. These tools simulate a real user browsing experience, which helps in circumventing anti-scraping measures without raising red flags. Headless browsers like Puppeteer and Selenium can execute JavaScript, handle cookies, render dynamic content, and more.
They also allow for executing custom scripts to mimic user behavior, such as mouse movements and clicks. By doing so, they effectively prevent detection mechanisms from distinguishing between automated and legitimate traffic, ensuring seamless data extraction while reducing the risk of being blocked while scraping.
Handling JavaScript Rendered Content
Extracting data from JavaScript-rendered web pages requires advanced methods to ensure accuracy and efficiency. Data experts recommend using headless browsers like Puppeteer or Selenium, which can interact with JavaScript and simulate user actions. These tools render full pages, ensuring that dynamic content is captured correctly.
When using these methods, it is crucial to implement practices that mimic human behavior, such as randomizing click intervals and mouse movements. Additionally, pausing for natural page load times can help avoid detection. Monitoring network requests can further enhance the scraping process by identifying key API endpoints that directly return the needed data.
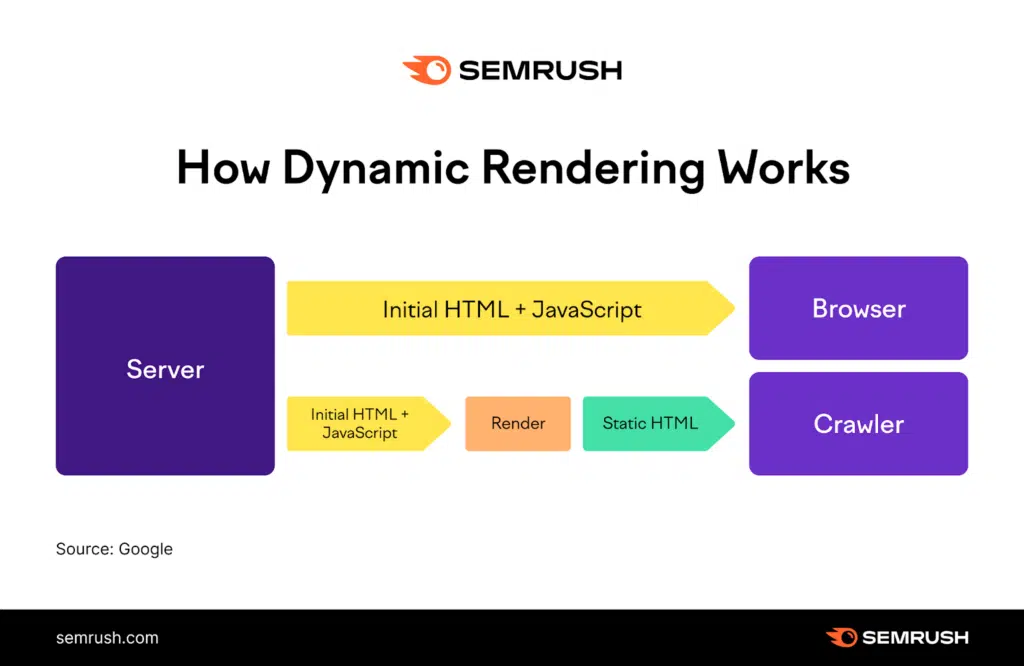
Image Source: Semrush
Building and Using Distributed Scraping Systems
Data experts often employ distributed scraping systems to enhance efficiency and reduce detection risks. Such systems involve distributing scraping tasks across multiple servers or IP addresses, thus mimicking organic traffic patterns. Key elements include:
- Load Balancers: Equitably distribute requests across servers.
- Proxy Pools: Rotate proxies to avoid IP bans.
- Task Queues: Manage and schedule scraping tasks.
- Data Processing Pipelines: Ensure efficient data extraction and storage.
These components, when effectively combined, can help in scaling operations while minimizing the chances of getting blocked by target websites.
Ethical Web Scraping: Key Considerations & Best Practices

- Respect Website Terms: Always review and comply with a website’s terms of service. Ignoring terms can lead to legal ramifications.
- Rate Limiting: Implement rate limiting to avoid overwhelming servers. Integrate delays between requests.
- Use API when Available: Prefer using official APIs over scraping whenever available to minimize risks and ensure data accuracy.
- Avoid Personal Data: Stay clear of scraping personal or sensitive data to comply with privacy laws like GDPR and CCPA.
- Seek Permissions: Whenever possible, seek explicit permission from website owners.
- Attribution and Copyright: Respect intellectual property rights by properly attributing and citing the data source.
- Monitoring Legal Changes: Regularly update policies on data usage to align with evolving web scraping laws and regulations.
- Data Quality and Representation: Ensure scraped data is accurately represented to avoid misinformation.
- Robust Error Handling: Incorporate error handling mechanisms to avoid triggering security measures on target websites.
Conclusion
Implementing strategies to avoid getting blocked while web scraping is crucial for successful data extraction. Engineers focus on respecting robots.txt, managing request rates, and using IP rotation.
PromptCloud offers professional web scraping services with comprehensive data extraction solutions, advanced anti-blocking technologies, and seamless data delivery systems.
We focus on helping businesses gather actionable insights without the technical hassles of manual web scraping. To take your web scraping endeavors to the next level, consider leveraging PromptCloud’s expertise.
Schedule a demo today. Reach out to us to discover how our solutions can meet your data needs efficiently.















