




Web scraping is a widely known term these days; not just because so much data exists around us, but more because there’s already so much being done with that data. Let’s try to analyze the differences between opting for software that comes with DIY components over picking a hosted data acquisition or hosted crawl solution on a vendor’s stack. Web crawler helps in extracting data from the web at scale.
We can broadly categorize scraping requirements into onetime and ongoing. These two needs further fork into large-scale vs. small-scale.
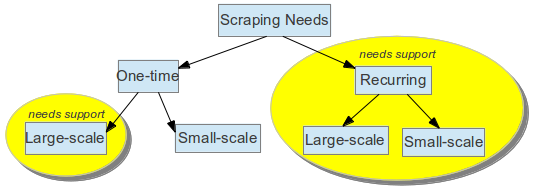
Web Scraper Categorization
For the reasons of visualization, let’s assume large-scale involves 100 websites or more, whereas small scale involves 5 or less.
Onetime scraping requirements on a tool
Usually, with onetime needs, folks seek a do-it-yourself software since they wouldn’t like to spend much time explaining their requirements to a vendor. This works when you have really simple and few sources to deal with. You indicate the fields that you’d like scraped to the tool, press the submit button, and after a few minutes of background processing, you have your CSV files on the screen. Neat!
Challenges while using a tool
The problem changes when you add in a few more websites, not all that simple, and have many more fields to collect. It’s not unusual when you click on each field to be captured from every site on your list and then be annoyed by surprises after you have submitted your request. Worse though, sometimes the crawls would have progressed to 99% and failed thereafter, leaving you in a wonderland. You wouldn’t know if re-running it will solve the problem. So you shoot a question to the software’s support centre and wait to hear something like the site blocked their bots.
Vis-à-vis hosted solution
Let’s compare this situation when you are on a hosted solution of a vendor with crawling expertise.
Up-time – A vendor dedicated to crawling has clusters running on several machines 24 by 7. This is needed to ensure that their platform is continuously feeding data to all its customers. A failure might occur with a scraping tool when it has not servers available to perform the crawls.
Scalability
Most of these vendors design their platform to scale with as many customers and sources as possible. As long as such design decisions are incorporated, the scale is not an issue and any kind of requirements can be dealt with. Most of the tools get bogged down when the scale increases. We have had clients who tried running a scraping tool for a complete day to extract data from a huge site, and their laptops died. Web crawler can be used to extract data at scale.
Monitoring Using Web Crawler
Monitoring is rarely accompanied with any DIY solution. Imagine if you use a tool to extract data from a site every week, and that site changes structure almost every month. Such issues are taken care of with a hosted solution because their platforms have alert mechanisms in place.
Fail-over and Support – Support is largely provided by vendors if anything goes wrong with the crawl jobs or if data hasn’t arrived on time. Basically, life is too easy there. When it’s a tool you’re using, you’re at the mercy of the support centre.
Web Crawler – In Summary
“Is it possible to harvest content according to our specifications rather than crawling the domain by setting a depth because already we are using X and we are finding very difficult to get the entire core content from a page and also the depth of the crawling obstacles us by not getting content for all subjects?” – X is a Platform as a Service where you can write plugins to set up your crawlers. i.e. more than just a software. Web crawler has multiple uses and in diverse industries.
“We are currently using Y for crawling and would be interested to understand the advantages you can provide. Is there any way you could frame a workflow and harvest content according to our needs because using Y has only been helpful to a limit.” – Y is a desktop software for crawling web pages.
Irrespective of onetime or recurring requirements, large-scale crawls always require monitoring and support, whereas recurring requirements call for continuous monitoring, be it small-scale or large-scale. You can take a shot at using a scraping tool if the cost of interacting with a vendor for eliciting your small requirements are higher than you trying out a scraping tool. The essence is, if the crawl is not your forte, then it’s best to be with a vendor because crawling is a painful workflow in itself. Read Site Crawling Services to learn more about how Data as a Service helps.















