



**TL;DR**
Financial data no longer comes from filings alone. In 2025, fund managers and quant researchers extract market-moving signals directly from the web — scanning earnings sentiment, job listings, product reviews, supply chain updates, and social chatter. APIs capture the basics, but true alpha lives in unstructured sources.
Web scraping for finance bridges that gap. It delivers structured, real-time alternative data that reveals what numbers hide, how customers react, how competitors expand, and how markets move before disclosures hit the tape.
Takeaways:
- Alpha increasingly depends on information asymmetry derived from public data.
- Financial APIs offer speed but not depth; scraping unlocks overlooked sources.
- Alternative datasets power sentiment, trend, and risk models in real time.
- Managed scraping reduces compliance, QA, and infrastructure burdens.
- PromptCloud enables funds to operate at scale with fully governed data feeds.
How Financial Institutions Use Web Scraping for Alpha in 2025?
Every investment firm wants an edge. But as market data becomes commoditized, the next frontier for alpha lies outside traditional terminals.
Bloomberg and Refinitiv offer structured feeds. EDGAR filings give disclosure data. Yet, by the time those updates appear, high-frequency algorithms and data vendors have already priced them in. The differentiator now comes from what’s not yet indexed the overlooked signals sitting in millions of unstructured pages across the web.
Web scraping turns those scattered traces into alternative datasets: organized, timestamped, and ready for quantitative models. It’s not just about collecting text; it’s about discovering early patterns: the supplier hiring faster than peers, the airline quietly trimming routes, or the retail chain posting delayed shipping updates.
This article breaks down how funds and financial institutions are using web scraping for alpha generation in 2025: the sources, signals, architecture, and governance models behind their advantage.
Need clean, real-time alternative data feeds that uncover alpha others miss?
If you want AI-ready data without building the infrastructure yourself, our team can deliver model-ready web data for any workflow. You can schedule a demo with the PromptCloud team.
Why Financial APIs Aren’t Enough Anymore
APIs were meant to simplify market data access. They do, but only for structured, pre-approved information that everyone else also sees. Stock prices, earnings calendars, filings, and macro indicators are now near-instant commodities. For funds competing on edge and speed, that sameness kills differentiation.
1. Everyone Has the Same Feed
APIs from Bloomberg, Refinitiv, or Nasdaq give identical values to every subscriber. When thousands of funds read the same ticker updates or quarterly data, price discovery becomes uniform. The result? Margins shrink, and returns converge toward zero.
Web scraping, on the other hand, surfaces exclusive insights before they reach mainstream data feeds.
Example: Supplier job postings, regional ad spend data, or social forum sentiment can all predict market trends days or even weeks ahead of formal disclosures.
2. Coverage Gaps in Alternative Data
Financial APIs rarely cover unstructured domains such as:
- Earnings sentiment from executive quotes in press coverage
- Retail investor behavior across forums or community threads
- Hiring and layoff patterns from corporate career pages
- Product pricing or availability on ecommerce sites
- M&A chatter or patent filings hidden in regulatory subpages
Each of these categories contains alpha-generating potential, but none are standardized enough to appear in traditional APIs. Scraping bridges the gap by capturing and structuring these non-traditional sources in near real time.
3. Latency and Update Frequency
APIs often batch data daily or weekly. Web signals change by the minute. When a brand announces a product recall on its website before issuing an SEC filing, or a CFO’s quote shifts sentiment mid-conference, the first mover gains an informational advantage. Scraping provides that immediacy & continuously collecting updates the moment they appear online.
4. Regulatory and Contextual Blind Spots
APIs are clean but narrow. They rarely capture contextual information like disclaimers, wording, or tone that influences sentiment models. For example, APIs might tag an earnings release as “positive” based on headline keywords, but the full transcript may reveal cautious forward guidance detectable only through text scraping and NLP.
In short: APIs are built for distribution. Scraping is built for discovery.
5. Data Freshness as a Competitive Variable
Speed isn’t just about low latency — it’s about data freshness. The quicker a firm identifies a shift in consumer demand, job hiring, or product recall, the stronger its alpha opportunity. By integrating a web scraping layer over public data sources, financial institutions build live, event-driven intelligence systems that capture value in real time instead of reacting hours later.
Where the Edge Comes From: Key Web Data Sources for Alpha Generation
Not all data is created equal. In finance, what matters most isn’t the volume of data collected, but its timing and interpretability. Alpha is generated when you identify a pattern before consensus forms. That means focusing on the right alternative data sources: public, traceable, and predictive of financial movement.
Here’s where modern funds and quant teams extract their edge.
1. Earnings Sentiment and Executive Tone
Earnings calls, CEO interviews, and investor-day presentations hold enormous predictive value. Yet APIs only index the text. The real alpha lives in tone, phrasing, and context.
Scraping enables the extraction of:
- Lexical sentiment across thousands of earnings transcripts
- Keyword frequency drift (e.g., “cautious optimism” rising before downturns)
- Management emotion markers (word choice, uncertainty expressions)
When paired with NLP models, this data transforms into quantifiable sentiment scores — early indicators of revenue shifts and market confidence.
2. Job Postings and Workforce Signals
Hiring activity is one of the most reliable real-world indicators of company performance. A surge in postings for logistics managers often precedes product expansion. A sudden freeze or deletion pattern signals contraction or restructuring.
Funds scrape:
- Corporate career pages and ATS systems
- Regional job boards
- LinkedIn listings with historical snapshots
This “workforce heat map” provides forward-looking intelligence on operational changes before they appear in financial statements.
3. Product Pricing, Stock, and Promotion Data
Ecommerce listings, retail catalogues, and product pages reveal microeconomic shifts. A price drop across SKUs may hint at margin pressure; persistent stock-outs can forecast revenue jumps. By scraping price, stock, and promotional metadata across retailers, funds build dynamic product baskets that correlate with company performance.
For example:
- Smartphone out-of-stock rates at major retailers can anticipate quarterly shipment growth.
- Airline fare scraping predicts ticket yield performance before investor disclosures.
PromptCloud’s retail data feeds already power similar intelligence pipelines for market analysts tracking consumer categories.
4. Regulatory and Legal Filings
Government portals and regional disclosure sites often publish critical documents days before they reach aggregation feeds. Scraping these portals gives early access to:
- Environmental or compliance disclosures
- Legal proceedings and patent filings
- Tender notices or subsidy announcements
For funds covering energy, defense, or infrastructure, these early signals can directly affect valuations.
5. Social and Community Sentiment
Retail traders move markets faster than ever. Forums, Discord groups, and niche subreddits act as collective momentum indicators. Scraping these discussions lets analysts track:
- Mention frequency by ticker or company
- Bullish vs bearish sentiment over time
- Event-driven surges tied to catalysts
This “crowd layer” supplements institutional data, creating a blended sentiment model that detects hype cycles before they move mainstream.
6. Supply Chain and Geospatial Clues
Scraping B2B directories, shipping databases, and supplier websites can expose hidden dependencies.
When a component supplier increases production or posts new export manifests, analysts can link that back to listed clients & uncovering bottom-up alpha invisible to API-driven systems.
7. Analyst Coverage and Consensus Shifts
Tracking analyst reports, ratings changes, and coverage updates across public broker sites helps detect early consensus drift. Scraping these updates across firms surfaces subtle revisions, when analysts start trimming price targets quietly before an official downgrade.
Together, these sources form an alternative data matrix; a holistic, multi-signal layer that feeds into quant models for forecasting, sentiment tracking, and risk scoring.
Next, we’ll break down how institutions structure and process this data pipeline, from raw HTML to structured, validated financial intelligence.
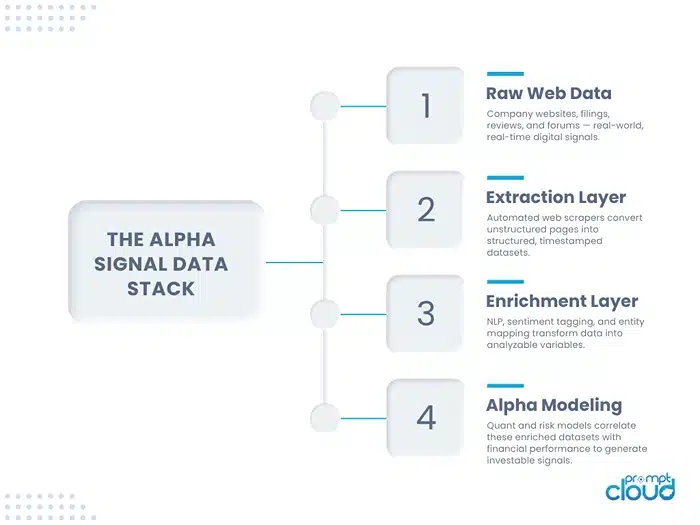
The Alpha Signal Data Stack — how financial institutions transform scraped web data into predictive, model-ready features.
How Financial Institutions Turn Scraped Data into Alpha
Collecting alternative data is only half the story. The real edge comes from how financial institutions convert that raw, unstructured data into quantifiable signals while maintaining compliance, speed, and quality. A modern financial data pipeline mirrors what you’d see in a technology company, not a trading desk. It’s event-driven, validated, and optimized for latency.
1. Discovery and Extraction Layer
The process starts with identifying and collecting sources. Scrapers are scheduled to fetch data across targeted pages, APIs, or JSON payloads embedded within HTML. Each extraction job carries metadata (source URL, timestamp, region, language) that helps trace data lineage.
For heavily dynamic sites, institutions rely on headless browsers that render JavaScript elements and parse content beyond the simple DOM. This ensures that earnings sentiment, product listings, or job postings hidden behind interactive interfaces are fully captured.
Scraping Amazon Prices at Scale — shows how scalable pipelines manage rotating proxies and data freshness without downtime.
2. Enrichment and Normalization
Once data is collected, it’s normalized into machine-readable schemas. For example:
- Convert text sentiment into numeric polarity scores.
- Standardize timestamps across time zones.
- Tag entities (company, sector, ticker) via NLP models.
- Convert prices into base currency values.
This makes otherwise noisy data ready for modeling. PromptCloud’s managed solutions include these normalization layers, eliminating the need for hedge funds to maintain custom ETL pipelines internally.
3. Real-Time Data Streaming and Event Architecture
Alpha decays fast. Delays of even minutes can render a signal useless. That’s why leading funds use event-driven scraping architectures that push updates instantly into analytics engines.
When a company posts a new investor FAQ or removes a hiring ad, that change is published as an event to a message queue (Kafka, Pub/Sub). This data can then trigger downstream alerts or feed real-time dashboards for portfolio managers.
Real-Time Scraping for LLM Agents — explains event-driven systems built to stream live data into analytical pipelines and AI models.
Read more: According to the State of Alternative Data 2025 report by Nasdaq, more than 60% of institutional investors now integrate real-time web data streams into portfolio strategy, up from 28% in 2022.
4. Signal Modeling and Correlation
The normalized dataset becomes input for alpha signal modeling. Quant teams correlate trend shifts with fundamentals, sentiment changes, or price reactions to backtest predictive value.
Examples:
- Job posting increases vs quarterly revenue growth.
- Product price cuts vs margin contraction.
- Forum sentiment spikes vs volatility expansion.
To ensure accuracy, these signals are recalibrated weekly through regression tests and out-of-sample validation.
5. Visual and Media Enrichment
Some of the richest signals are hidden in product visuals or marketing assets. Funds scrape image libraries, charts, or investor presentation decks to detect subtle visual indicators: logo changes, product packaging updates, or sustainability disclosures.
Computer vision models analyze this scraped imagery for brand presence and marketing intensity, enhancing sentiment and ESG models.
Image Scraping for eCommerce AI — covers how automated media extraction supports visual intelligence at scale.
6. Validation and Governance
Compliance is paramount. Every scraped source must be publicly accessible, non-gated, and documented for audit. Managed providers like PromptCloud maintain logs, access patterns, and validation records that ensure every dataset adheres to legal and ethical collection guidelines.
This QA process involves:
- Schema validation for missing or malformed fields.
- Freshness checks for each time window.
- Sampling for outliers or duplication.
- Manual review for anomalous events.
The result: high-trust, ready-to-model datasets that pass both compliance and investor due diligence.
7. Build vs Buy: Why Managed Pipelines Win
Internal scraping teams often underestimate maintenance complexity. Endpoint changes, proxy rotation, and validation logic can consume weeks of engineering time each quarter. That’s why even large quant funds now outsource the extraction layer to specialized partners.
Instant Data Scraper Comparison: Build vs Buy — details total cost of ownership and operational trade-offs between in-house scripts and managed feeds.
PromptCloud’s managed model provides continuous delivery of normalized datasets with full SLAs, allowing financial teams to focus on research, not repairs.
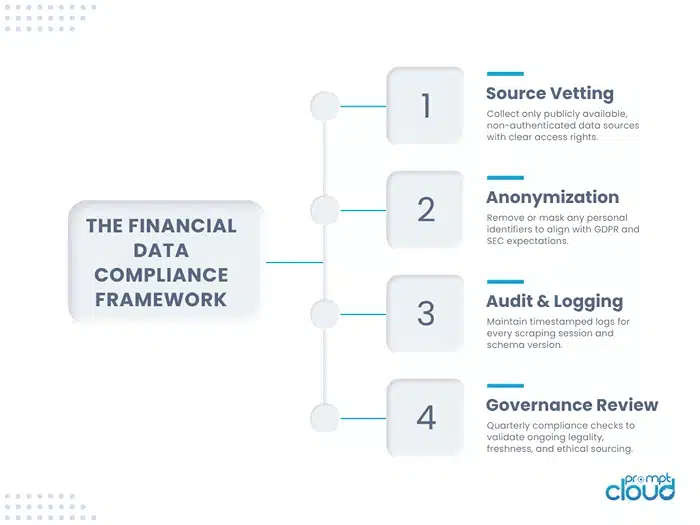
The Compliance Framework — the governance process ensuring that alternative data collection meets institutional and regulatory standards.
The Compliance Layer: Building Trust Around Web Data
For financial institutions, compliance isn’t a checklist, it’s survival. Every dataset that influences investment decisions must be defensible, auditable, and ethically sourced. Web scraping introduces new capabilities, but without a strong compliance layer, it can quickly turn from asset to liability.
PromptCloud’s approach to financial web data acquisition is built around transparency, traceability, and governance. Here’s how the best institutions maintain that trust.
1. Source Legitimacy and Access Rights
The foundation of compliant scraping is knowing where your data comes from. Every source must be publicly accessible, non-authenticated, and free from explicit restrictions in its robots.txt or terms of service.
PromptCloud performs source vetting before onboarding any new feed. Each domain is categorized as:
- Open public source (e.g., corporate career pages, press releases, retail listings)
- Limited public source (requires pagination or form interactions, still anonymous)
- Restricted source (behind logins, gated APIs, or paywalls — excluded)
This classification ensures every dataset can pass compliance review during investor audits or regulatory scrutiny.
2. Data Anonymization and Aggregation
Raw data may contain incidental identifiers ; names, emails, or other user references from public forums. To stay within data protection frameworks such as GDPR, PromptCloud anonymizes or removes personal identifiers before delivery.
Scraped datasets are aggregated at a signal level, not an individual one. For example:
- Instead of delivering user-level reviews, aggregate average sentiment per brand.
- Replace personal handles with hashed IDs to maintain continuity without identity exposure.
This balance preserves analytical value while eliminating privacy risks.
3. Documentation and Audit Trails
Every scraping pipeline includes a source registry, detailing:
- Domains and access timestamps
- Request frequency and data volume
- Selector logic and schema versions
- QA outcomes and manual reviews
These records form an immutable audit trail, making it possible to trace any data point back to its origin and validate its compliance lineage. This transparency is critical when presenting datasets to limited partners, regulators, or auditors.
4. Regional Regulations and Data Protection
Regulations governing alternative data are evolving. While the U.S. SEC and European ESMA do not currently prohibit web scraping of public data, they expect funds to demonstrate:
- Ethical sourcing
- Documentation of consent (implicit or explicit access rights)
- Proper data security practices
PromptCloud’s managed services operate under ISO/IEC 27001 standards for information security.
Data is processed and stored in compliance with:
- GDPR (EU/EEA)
- CCPA (California)
- DPDP Act (India, 2023)
This ensures legal harmony across jurisdictions — a must-have for global funds operating under multiple regulatory umbrellas.
5. Internal Controls and Escalation Protocols
Compliance isn’t static. It’s enforced continuously. PromptCloud employs a tiered control system:
- Automated validation – checks rate limits, robots directives, and data structure.
- Human review – compliance analysts verify intent, access, and content types.
- Client-specific policy overlays – custom rules (e.g., “no personal data from user forums”).
If a violation or ambiguity is detected, scraping for that domain is paused instantly until cleared by compliance review. This structured process ensures nothing questionable slips through.
6. Transparency as Differentiation
In the arms race for alpha, some firms treat data sources as trade secrets. But opaque sourcing is a reputational risk. Institutional investors increasingly demand data provenance reports that show how insights were derived.
By maintaining transparent pipelines, PromptCloud’s clients can share datasets confidently with regulators, compliance officers, and portfolio stakeholders. This traceability isn’t just ethical — it’s a competitive advantage in a market that rewards responsible innovation.
From Data to Decisions — How Funds Turn Signals into Alpha
The ultimate goal of financial web scraping isn’t more data. It’s better conviction. Every dataset scraped from the web—whether sentiment, job listings, or product pricing needs to translate into actionable, measurable alpha. In practice, that means transforming raw, noisy inputs into structured, model-ready variables that connect to returns.
Here’s how institutional investors operationalize that journey from data to decision.
1. From Raw Inputs to Modeled Signals
Each category of scraped data follows a similar three-step conversion path.
| Data Source | Processing Step | Example Output |
| Earnings Sentiment | NLP sentiment scoring across transcripts | “Positive tone score = +0.34; correlated with next-quarter price increase” |
| Job Listings | Classification and trend smoothing | “Hiring growth index: +8% QoQ for supply chain roles” |
| Product Prices | Aggregation and inflation adjustment | “Average retail price up 4.2% across core SKUs” |
| Social Mentions | Frequency tracking, de-duplication, and clustering | “Ticker mentions up 210% on forums pre-announcement” |
By normalizing these signals to consistent time intervals (daily, weekly, or monthly), funds feed them into econometric or machine learning models that link to financial outcomes.
2. Combining Scraped Data with Traditional Fundamentals
Web data doesn’t replace fundamentals; it enhances them. Analysts create hybrid feature sets, blending scraped variables with conventional financial indicators like EPS growth or balance sheet ratios.
| Model Type | Core Variables | Scraped Enhancements | Use Case |
| Revenue Growth Predictor | Historical sales, GDP growth | Product stock levels, search interest, hiring velocity | Forecast quarterly earnings |
| ESG Risk Score | Carbon disclosures, governance rating | News tone, supplier diversity data | Monitor sustainability risks |
| Sentiment Momentum Model | Analyst ratings, news flow | Forum sentiment, executive speech tone | Identify overbought or oversold stocks |
This integration creates more resilient models that reflect real-world behavior, not just reported results.
3. The Role of Visualization and Decision Systems
Once data becomes model output, it must be accessible to decision-makers. Funds embed scraped signal dashboards into BI tools such as Tableau, Looker, or Power BI. Common visuals include:
- Trend overlays for job activity vs. price moves
- Heatmaps of product availability vs. regional sales
- Sentiment curves aligned with stock volatility
Portfolio managers consume these dashboards daily, using them to adjust positions, rebalance exposure, or identify new entry points before market consensus shifts.
4. Backtesting Alpha and Measuring Predictive Power
Before integrating a new signal into production, quant teams run rigorous backtests to verify its predictive strength. Key evaluation metrics include:
- Information Coefficient (IC) — correlation between signal and future returns
- T-statistics — statistical significance of prediction accuracy
- Decay Half-Life — how quickly signal alpha erodes over time
| Metric | Acceptable Range | Interpretation |
| IC | 0.05 – 0.15 | Strong short-term predictive power |
| T-stat | > 2.0 | Statistically reliable |
| Half-Life | 7–30 days | Retains useful alpha for rebalancing window |
These metrics help analysts distinguish noise from actionable insight, refining which scraped features deserve ongoing collection.
5. Why Visualization Matters for Investor Communication
Investors increasingly expect transparency around data-driven strategies. By visualizing how alternative data feeds map to portfolio results, fund managers can demonstrate repeatability and discipline—two traits that separate credible quant strategies from black-box experimentation.
Need clean, real-time alternative data feeds that uncover alpha others miss?
If you want AI-ready data without building the infrastructure yourself, our team can deliver model-ready web data for any workflow. You can schedule a demo with the PromptCloud team.
FAQs
1. What does web scraping for finance mean?
Web scraping for finance refers to extracting publicly available data from online sources such as company websites, product pages, job portals, or regulatory sites and converting it into structured datasets for investment analysis. It enables hedge funds, asset managers, and research teams to detect alternative signals that aren’t available through standard APIs or data vendors.
2. What is alternative data, and why is it valuable for hedge funds?
Alternative data includes non-traditional information like hiring activity, product availability, social sentiment, or customer reviews that can anticipate company performance. Hedge funds use this data to generate alpha—returns beyond market benchmarks—by identifying early indicators of business momentum or risk.
3. Is it legal for financial institutions to use scraped web data?
Yes, when it’s sourced ethically and from publicly accessible domains. Managed services like PromptCloud ensure that all financial web scraping follows legal frameworks such as GDPR, SEC guidance, and local data privacy laws. This includes avoiding login-gated or paywalled content and maintaining auditable records for every data source used.
4. How does PromptCloud ensure data quality and compliance for financial clients?
PromptCloud applies multi-layer validation—schema consistency checks, timestamp alignment, and human-in-the-loop QA—to keep data accurate and compliant. It also maintains documentation trails for every domain scraped, ensuring full transparency during audits or investor reviews.
5. What types of financial models benefit most from web-scraped data?
Web-scraped datasets support quantitative models for revenue forecasting, ESG scoring, sentiment momentum, and risk monitoring. They complement structured financial data by adding behavioral and contextual layers, giving analysts a richer understanding of company performance and investor sentiment.















