




Web Scraping Advantages for Data-Driven Businesses
Web scraping allows organizations to collect large volumes of publicly available data from websites automatically, making it possible to monitor competitors, track market trends, and build AI-ready datasets at scale. The main web scraping advantages include faster data collection, lower operational costs compared to manual research, access to diverse online data sources, and continuous market intelligence.
However, web scraping also comes with limitations. Website structures change frequently, anti-bot protections can block automated requests, and raw web data often requires cleaning and normalization before it becomes usable. For organizations monitoring dozens of sources or requiring frequent data updates, managed web scraping infrastructure can eliminate the operational burden of maintaining scraping systems internally.
Organizations today rely heavily on external data to understand markets, track competitors, and build analytics systems. Much of that information lives across thousands of websites, marketplaces, and digital platforms. Manually collecting this data is slow, inconsistent, and nearly impossible to scale. This is where web scraping advantages become clear.
Web scraping allows companies to automatically extract large volumes of publicly available web data and convert it into structured datasets. Instead of manually copying information from websites, automated systems collect data continuously, enabling businesses to analyze markets, monitor competitors, and power AI models with fresh information.
For modern enterprises, web scraping is not just about collecting data faster. It enables organizations to build data acquisition pipelines that transform raw web pages into structured datasets suitable for analytics, machine learning, and business intelligence systems.
Businesses across industries rely on web scraping to collect signals such as:
- competitor pricing and product catalogs
- customer reviews and sentiment trends
- job postings and hiring signals
- financial announcements and market news
- product availability across marketplaces
These signals help organizations detect market shifts earlier and make faster strategic decisions.
However, while the web scraping advantages are significant, the technology also comes with technical and operational limitations. Websites change frequently, anti-bot protections can block automated requests, and raw web data often requires significant cleaning before it becomes usable.
Understanding both the benefits and limitations of web scraping is therefore essential before implementing large-scale web data pipelines.
In the following sections, we will examine the major web scraping advantages, the limitations organizations should consider, and how modern data teams overcome these challenges when building enterprise data pipelines.
External data is also growing rapidly across the internet. According to IDC’s Global DataSphere research, the total amount of data created worldwide is expected to exceed 175 zettabytes by 2025, much of it generated across digital platforms such as e-commerce marketplaces, job portals, and review platforms. At the same time, the Imperva Bad Bot Report estimates that automated traffic accounts for roughly 47 percent of global internet traffic, highlighting how much activity now occurs through automated systems rather than manual browsing.
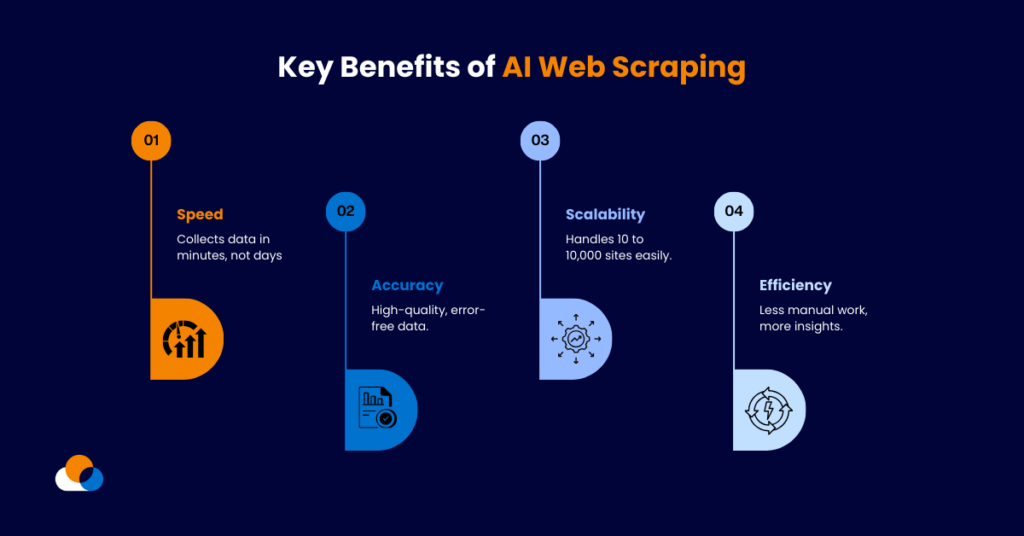
Key Web Scraping Advantages for Businesses
When organizations begin collecting external market data, they quickly realize how inefficient manual data collection can be. Visiting hundreds of websites, copying information into spreadsheets, and repeating the process daily is not practical for modern data teams.
This is where the web scraping advantages become clear. Automated data extraction allows companies to collect and analyze large volumes of web data quickly and consistently. Below are the most important advantages businesses gain when they implement web scraping systems.
Source: webdataguru.com
Faster Data Collection at Scale
One of the biggest web scraping advantages is the ability to collect data from thousands of pages within minutes. Instead of manually gathering information from multiple websites, automated scraping tools can continuously monitor and extract data from entire domains.
For example, e-commerce businesses frequently track thousands of product listings across competitor marketplaces. A manual process would require teams to repeatedly visit individual pages, but scraping systems can capture pricing, stock levels, product descriptions, and ratings automatically.
This allows organizations to build datasets that update continuously, giving teams access to fresh market signals.
Cost Efficiency Compared to Manual Research
Another important web scraping advantage is cost efficiency. Large-scale data collection through manual research often requires significant human resources. Analysts must repeatedly search websites, copy information, and verify results.
Automated scraping systems dramatically reduce this operational effort. Once extraction pipelines are configured, they can collect data continuously with minimal human intervention.
For companies that depend on ongoing market monitoring, automation significantly lowers the cost of maintaining data pipelines.
Improved Data Accuracy and Consistency
Manual data collection often introduces errors such as missing fields, incorrect values, or inconsistent formatting. Automated scraping pipelines reduce these risks by extracting data using predefined rules and structured schemas rather than manual copy-paste processes.
When scraping pipelines include validation rules and schema standardization, extraction accuracy improves significantly compared to manual collection. However, raw web data still requires cleaning and normalization before it becomes analytics-ready, especially when information is collected from multiple sources with different formats.
However, maintaining structured data becomes more important as organizations begin using web data for analytics or AI workflows. Structuring and labeling extracted datasets correctly ensures that they can be integrated into downstream systems.
Access to Large and Diverse Data Sources
Another key web scraping advantage is the ability to collect information from many different sources across the internet. Businesses can gather data from marketplaces, job portals, review platforms, news sites, forums, and corporate websites.
This wide coverage allows organizations to analyze patterns that would otherwise remain hidden. For example:
- retailers can track pricing trends across competitors
- financial analysts can monitor hiring signals across industries
- marketing teams can study customer sentiment across review platforms
The more sources organizations monitor, the stronger their ability to detect market changes early.
Continuous Market Intelligence
Finally, web scraping enables companies to build continuous intelligence systems rather than one-time research reports.
Instead of collecting information occasionally, scraping pipelines run on schedules that refresh datasets regularly. This allows companies to monitor real-time signals such as:
- pricing changes
- product launches
- competitor promotions
- customer feedback trends
For organizations operating in competitive digital markets, these continuous signals become a major strategic advantage.
Turning Web Data Into Structured Business Datasets
Get clean, structured web data delivered on your cadence from a managed pipeline built around your specific sources and schema.
PromptCloud provides managed web scraping services that collect data from target websites, structure it into clean datasets, and deliver it directly to analytics and AI systems.
Instead of building crawler infrastructure internally, data teams can focus on analysis and decision-making.
• No contracts • No credit card required • No scraping infrastructure to maintain
Web Scraping Disadvantages and Limitations to Consider
While the web scraping advantages are significant, organizations must also understand the limitations of this technology before implementing large-scale data pipelines. Collecting web data at scale introduces technical, operational, and compliance challenges that businesses must address to maintain reliable datasets.
Understanding these limitations helps organizations design better scraping infrastructure and avoid common mistakes when building web data pipelines.
For teams requiring reliable large-scale web data pipelines, managed web scraping services provide structured datasets and continuous monitoring without maintaining complex scraping infrastructure.
Data Cleaning and Preparation Requirements
One of the most overlooked challenges of web scraping is the amount of post-processing required before data becomes usable. Web pages are designed for human reading, not structured data extraction. As a result, scraped datasets often contain inconsistent formats, duplicate entries, or missing fields.
Before this data can be used for analytics or machine learning, it must go through processes such as:
- normalization of formats across sources
- deduplication of records
- labeling and categorization
- schema standardization
Without these steps, web data can introduce noise into analytics systems.
Website Structure Changes
Websites frequently update their layout, HTML structure, or page elements. Even small design changes can break scraping scripts that depend on specific page elements.
For example, if a product page changes the location of a price field or modifies HTML tags, extraction rules may fail. This requires scraping systems to be continuously monitored and updated.
For organizations running large scraping pipelines, this becomes an ongoing maintenance task rather than a one-time implementation.
Anti-Scraping Mechanisms
Many websites implement technologies designed to prevent automated data extraction. These protections may include:
- rate limiting
- IP blocking
- CAPTCHA challenges
- bot detection systems
These restrictions can slow down or interrupt scraping pipelines. Enterprise systems therefore require sophisticated crawling infrastructure, proxy management, and request scheduling to operate reliably.
Legal and Compliance Considerations
Another limitation organizations must consider is the legal and ethical dimension of web data collection.
Although web scraping itself is not inherently illegal, businesses must ensure they follow responsible data practices such as:
- respecting website terms of service
- collecting only publicly available data
- complying with privacy regulations
- maintaining proper governance and traceability of datasets
Maintaining lineage and provenance records becomes especially important when datasets feed into analytics or AI systems. Proper tracking ensures teams understand where data originated and how it has been transformed.
Complexity of Large-Scale Web Data Pipelines
Finally, building reliable scraping infrastructure at enterprise scale requires technical expertise. Large data pipelines must handle distributed crawling, data validation, storage systems, and integration with analytics platforms.
Organizations that underestimate this complexity often struggle with unstable pipelines and inconsistent datasets.
For this reason, many companies move beyond DIY scraping scripts and adopt enterprise-grade web scraping solutions that provide managed infrastructure, data structuring, and continuous monitoring.
How Businesses Use Web Scraping Data for Analytics and AI Systems
Once organizations begin collecting web data consistently, the next step is turning that data into actionable insights. The true value of web scraping advantages appears when scraped datasets are integrated into analytics platforms, business intelligence tools, and machine learning systems.
Instead of treating web scraping as a standalone activity, modern companies incorporate web data into their broader data infrastructure. This allows teams across the organization to analyze external signals alongside internal metrics.
Below are some of the most common ways businesses operationalize web scraping data.
Evaluating Managed Web Data Solutions
Get clean, structured web data delivered on your cadence from a managed pipeline built around your specific sources and schema.
PromptCloud delivers structured web datasets from target websites without requiring teams to build or maintain crawler infrastructure.
Data pipelines include monitoring, anti-bot mitigation, schema validation, and structured delivery formats suitable for analytics platforms and machine learning systems.
Competitive Intelligence and Market Monitoring
One of the most widespread uses of web scraping is competitive monitoring. Companies continuously collect data from competitor websites to track changes in pricing, product assortments, and promotional strategies.
For example, e-commerce retailers often monitor competitor marketplaces to understand:
- price fluctuations across product categories
- availability and stock levels
- new product launches
- promotional campaigns
These signals help businesses adjust pricing strategies and respond quickly to market changes.
Customer Sentiment and Review Analysis
Customer feedback scattered across review platforms, forums, and social channels provides valuable insights into product performance and brand perception. Web scraping allows businesses to gather large volumes of review data and analyze patterns in customer sentiment.
Marketing and product teams can use this information to identify recurring issues, detect product improvement opportunities, and understand how customers compare competing brands.
Training Data for AI and Machine Learning
Another major reason organizations invest in web scraping pipelines is the need for large datasets used in machine learning and AI systems.
Many AI applications rely on web data for:
- natural language processing models
- recommendation engines
- market forecasting systems
- trend detection algorithms
However, AI systems require datasets that are structured, labeled, and consistent across sources. Raw scraped data must often be transformed into standardized schemas before it becomes useful for training models.
Companies also increasingly combine scraped datasets with synthetic data when building training pipelines for AI systems. Understanding the differences between real-world web data and generated datasets helps organizations design stronger training strategies.
Market Research and Industry Trend Analysis
Web scraping also supports large-scale research projects. Analysts can gather data from multiple online sources to identify emerging patterns in industries, customer preferences, or economic signals.
For example, job posting data can reveal hiring trends across sectors, while product listings across marketplaces can indicate demand shifts for specific categories.
Because scraped data can be updated continuously, businesses gain a dynamic view of markets rather than relying on static reports.
Building Data Pipelines for Enterprise Intelligence
Ultimately, the biggest impact of web scraping appears when organizations build automated data pipelines that feed external signals into decision systems.
When web data is structured and delivered reliably, companies can integrate it into:
- business intelligence dashboards
- pricing engines
- demand forecasting models
- AI-driven analytics platforms
These systems transform raw web data into continuous intelligence that helps organizations move faster and make more informed decisions.
Web Scraping Advantages vs Limitations: A Practical Comparison
When evaluating web scraping advantages, it is important to view them alongside the practical limitations organizations face when collecting web data. While the benefits of automation, scale, and market intelligence are significant, the technology also requires thoughtful implementation to ensure reliability and compliance.
For many businesses, the difference between successful and unsuccessful web scraping projects lies in how the data pipeline is designed and maintained. Simple scripts may work for small data collection tasks, but enterprise use cases require infrastructure that handles scale, schema stability, and data validation.
The table below summarizes the key advantages and limitations organizations should consider when implementing web scraping systems.
| Aspect | Web Scraping Advantages | Practical Limitations |
| Data Collection Speed | Automated systems can extract data from thousands of pages within minutes, enabling continuous monitoring of market signals. | Websites may limit request speeds or block automated access, requiring careful request scheduling and proxy management. |
| Scale of Data Coverage | Scraping allows businesses to gather information from large numbers of websites and digital platforms simultaneously. | Managing data pipelines across thousands of sources requires monitoring, infrastructure, and maintenance. |
| Cost Efficiency | Automated data collection reduces the need for manual research teams and repetitive data entry tasks. | Initial setup, infrastructure costs, and ongoing maintenance may require specialized expertise. |
| Market Intelligence | Businesses gain real-time insights into competitor pricing, product listings, reviews, and hiring signals. | Data collected from different sources may require cleaning and normalization before it becomes usable. |
| Integration with Analytics and AI | Scraped data can power analytics dashboards, forecasting systems, and machine learning models. | Raw web data must often be structured and validated before it can feed downstream systems. |
| Continuous Data Updates | Scraping pipelines can refresh datasets regularly, allowing organizations to monitor trends as they emerge. | Website layout changes may break extraction rules, requiring continuous updates to scraping logic. |
| Access to Public Web Data | Businesses can collect publicly available information from across the web to improve decision-making. | Legal and compliance considerations must be evaluated carefully to ensure responsible data collection. |
For organizations that rely heavily on external data signals, these trade-offs are manageable when the scraping system is designed correctly. Reliable infrastructure, structured data pipelines, and continuous monitoring help reduce the operational challenges associated with web data extraction.
As web data becomes increasingly important for analytics and AI systems, companies are moving beyond basic scraping scripts toward managed web scraping solutions that deliver structured datasets and stable pipelines.
Turning Web Scraping Advantages Into Reliable Business Intelligence
Understanding web scraping advantages is only the first step. The real impact appears when organizations turn automated web data collection into reliable data pipelines that support decision-making across the business.
Today’s digital economy generates an enormous volume of public data across websites, marketplaces, review platforms, and news sources. Companies that can systematically collect and structure this information gain a clearer understanding of markets, competitors, and customer behavior.
However, web scraping is not simply about extracting information from web pages. To generate real value, businesses must ensure that the collected data is structured, validated, and integrated into analytics systems. When implemented correctly, web scraping becomes an ongoing intelligence layer rather than a one-time data collection activity.
Key Takeaways on Web Scraping Advantages
Organizations across industries adopt web scraping because it provides several operational and strategic benefits:
1. Large-scale data access
Web scraping enables companies to collect information from thousands of websites simultaneously. This allows businesses to monitor pricing trends, product catalogs, hiring activity, and customer sentiment across multiple markets.
2. Automation of repetitive data collection
Manual research is time-consuming and prone to human error. Automated scraping pipelines collect and update data continuously, allowing teams to focus on analysis rather than data gathering.
3. Better market visibility
Continuous monitoring of online sources helps businesses identify market changes earlier. For example, companies can track competitor product launches, price adjustments, or changes in customer reviews.
4. Data-driven decision making
Scraped web data supports analytics dashboards, forecasting systems, and machine learning models. When integrated into business intelligence platforms, external web data provides additional context for strategic decisions.
Practical Considerations When Implementing Web Scraping
While the advantages are substantial, organizations must also account for the operational realities of maintaining web data pipelines. Website structure changes, anti-bot protections, and inconsistent data formats can affect the stability of scraping systems.
The table below summarizes how businesses can balance web scraping advantages with practical implementation considerations.
| Web Scraping Benefit | Business Impact | Implementation Consideration |
| Automated data collection | Reduces manual effort and accelerates research | Requires well-designed extraction rules |
| Continuous data monitoring | Enables real-time market intelligence | Requires scheduled crawls and monitoring |
| Access to large datasets | Supports analytics and AI training data | Data must be cleaned and standardized |
| Competitive intelligence | Helps businesses track competitors and market shifts | Multiple sources must be integrated reliably |
| Scalable data pipelines | Allows organizations to expand monitoring across markets | Infrastructure and maintenance are required |
Ready to evaluate? Compare managed web scraping services options →
The Future of Web Scraping for Businesses in 2026
Web scraping advantages become most valuable when automated data collection evolves into reliable data pipelines that support analytics and AI systems. Organizations that consistently collect and structure web data gain early visibility into market changes, competitor activity, and customer sentiment across digital platforms.
When implemented with reliable infrastructure and structured data workflows, web scraping becomes a continuous intelligence layer that supports faster, data-driven decisions.
Build Reliable Web Data Pipelines Without Managing Scrapers
Get clean, structured web data delivered on your cadence from a managed pipeline built around your specific sources and schema.
PromptCloud provides fully managed web data pipelines that collect, structure, and deliver datasets from target websites without requiring teams to build scraping infrastructure internally.
• No contracts • No credit card required • No scraping infrastructure to maintain
FAQs
1. What are the main web scraping advantages for businesses?
The main web scraping advantages include automated data collection, faster market research, large-scale data access, and improved competitive intelligence. Businesses can monitor pricing, customer sentiment, product listings, and industry trends without manual data collection.
2. Is web scraping legal for businesses?
Web scraping itself is not illegal, but organizations must follow responsible practices. Businesses should collect only publicly available data, respect website terms of service, and comply with privacy regulations such as GDPR or other regional data protection laws.
3. What industries benefit the most from web scraping?
Many industries rely on web scraping, including e-commerce, finance, real estate, travel, and recruitment. Companies in these sectors use web data to monitor competitor pricing, analyze customer reviews, track job postings, and detect market trends.
4. What challenges should companies consider when using web scraping?
Some common challenges include website structure changes, anti-scraping protections, inconsistent data formats, and the need for data cleaning before analysis. Organizations must also maintain reliable infrastructure to ensure stable data pipelines.
5. How do companies use web scraping data for analytics and AI?
Businesses often use scraped datasets to power analytics dashboards, market research models, and machine learning systems. Web data helps train algorithms, detect trends, and provide real-time signals that support data-driven decision making.















