



Nobody today has time to manually scan through Google News all day. Headlines change by the minute, new stories break around the clock, and if you blink, you miss something big. For anyone working in media, finance, marketing, or competitive intelligence, that’s a problem.
That’s where scraping Google News comes in. Done right, it gives you a constant feed of fresh, relevant headlines, without lifting a finger. Whether you’re tracking a trending topic, analyzing sentiment, or pulling insights for a report, being able to pull structured news data fast can make your job a lot easier.
Image Source: Google News Initiative
And here’s the thing: Google News scraping isn’t just about grabbing headlines. It’s about doing it ethically, efficiently, and without getting blocked or violating terms of service. That’s what this guide is about, how to get the data you need without crossing the line.
By the end of this, you’ll know how to:
- Stay within ethical boundaries when scraping Google News
- Choose the right tools (including Google News scraping using Python scripts and APIs)
- Optimize your scrapers to be fast, accurate, and low-maintenance
If you’re in media, PR, finance, or just need news data that doesn’t come in a messy RSS feed, this is for you. Let’s get into it.
Is It Legal to Scrape Google News? Understanding the Ethical Boundaries
Before you even write your first line of code, let’s clear up one big question: Is scraping Google News legal?
The short answer? It depends.
Google News doesn’t offer its own public API anymore (the old one was deprecated years ago), and its content is aggregated from thousands of publishers. So, when you’re scraping Google News, you’re technically scraping content that often doesn’t belong to Google—it belongs to the news sites they list.
Now, does that mean web scraping Google News is illegal? Not necessarily. Web scraping exists in a legal gray area. There’s no global law that says “you can’t scrape a website,” but there are rules around how you do it, what you do with the data, and whether you’re violating the website’s terms of service.
Here are a few things to think about:

Terms of Service Matter
Google’s Terms of Service don’t explicitly ban scraping in all cases, but they do prohibit using automated tools to access or extract content unless you have permission. So, technically, automated Google News scraping could go against those terms, especially if you’re hammering their servers with lots of requests.
But here’s where it gets interesting: Google doesn’t always enforce this strictly, especially if you’re respectful in how you scrape (think low frequency, no personal data, no monetization of scraped content).
Robots.txt Isn’t a Law, But It’s Still a Signal
If you’ve been around scraping circles, you’ve probably heard of robots.txt. It’s a file that tells bots which pages they’re allowed to crawl. Google News’s robots.txt generally disallows bots from hitting certain paths. Violating it won’t get you sued, but it might get your scraper blocked.
Ethical scrapers use robots.txt as a guide—not just because it’s polite, but because it helps you avoid wasting resources on restricted content.
So, What’s Ethical?
Let’s break it down simply:
- Don’t overload Google’s servers. Space out your requests.
- Don’t scrape paywalled or private content.
- Don’t resell scraped content as-is.
- Do use the data internally, like for sentiment analysis, media tracking, or research.
- Do respect publishers. Link back, quote properly, or better yet, just extract metadata like headlines, source names, and timestamps.
Ethical Google News scraping is possible, and a lot of professionals do it. But always ask: Would I be okay if someone used my content this way?
Best Tools and Methods for Google News Scraping (That Won’t Get You Blocked)
If you’re thinking of writing your own scraper or using a tool to extract data from Google News, you’ve got options. But not all scraping methods are created equal—some are slow, some are clunky, and some will get you blocked after just a few requests.
Let’s walk through some of the most efficient and reliable ways to scrape Google News, including both custom code and scraping services. Whether you’re a Python developer or just someone who wants structured news data fast, there’s a method here for you.
1. Python: The Scraper’s Best Friend
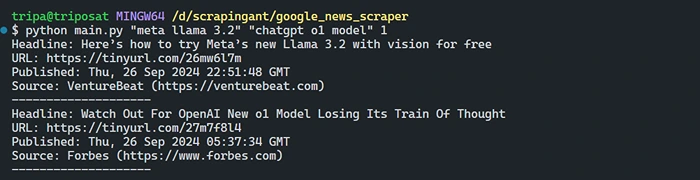
Image Source: scrapingant
Python is the go-to language for scraping for a reason: it’s powerful, easy to learn, and backed by a massive ecosystem. If you’re building your own Google News scraping Python script, here’s what you’ll need:
- Requests to make HTTP calls
- BeautifulSoup or lxml for parsing HTML
- Fake headers and rotating user agents to avoid detection
- Proxies or throttling to keep your requests under the radar
Here’s a very basic example:
python
CopyEdit
import requests
from bs4 import BeautifulSoup
query = ‘ai technology’
url = f’https://news.google.com/search?q={query}’
headers = {‘User-Agent’: ‘Mozilla/5.0’}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, ‘html.parser’)
for item in soup.select(‘article’):
headline = item.get_text()
print(headline)
This just scratches the surface. For large-scale scraping, you’ll want to add error handling, IP rotation, headless browsers (like Selenium or Playwright), and maybe even an asynchronous framework like aiohttp for speed.
2. Google News API Alternatives
Google shut down its official News API years ago. But that hasn’t stopped developers from building Google News API alternatives. These services don’t always scrape Google News directly—instead, they offer access to similar news aggregation or search results via a clean API.
Some worth exploring:
- GNews API (https://gnews.io)
- NewsCatcher
- ContextualWeb News API
These APIs can help you scrape Google News-style data without worrying about HTML structure or scraping hygiene. They’re especially useful if you need results in JSON format and don’t want to maintain your own crawler.
3. Web Scraping Services (If You Don’t Want to Code)
If you don’t have the time or team to build your own solution, a web scraping service like PromptCloud can do the heavy lifting. Services like this are especially valuable if you:
- Need clean, structured news data regularly
- Don’t want to deal with proxy issues, captchas, or rotating headers
- Want to stay compliant with content use policies
Web scraping services also offer custom pipelines—so if you need just the headlines, timestamps, and URLs, they’ll deliver exactly that in the format you want (like CSV, JSON, or directly to your database).
4. Browser Automation: When HTML Keeps Changing
Sometimes Google updates its HTML just enough to break your static parser. When that happens, tools like Selenium or Playwright can mimic real users and load the page like a browser would.
These are heavier on resources and slower than API-style scraping, but they’re great for dynamic content or testing.
Just remember: scraping with a browser doesn’t make you immune to detection. You still need to throttle requests and behave like a human.
How to Scrape Google News Efficiently Without Sacrificing Quality
When you’re building a Google News scraping workflow, it’s easy to focus only on getting the data. But scraping fast without a plan usually leads to junk—duplicate results, broken content, irrelevant articles, and worse, getting blocked.
So, how do you scrape efficiently and maintain high data quality? It starts with optimizing both how you scrape and what you scrape.
Use Query Parameters to Target Results
Instead of scraping everything on the page, narrow your focus using query parameters. Google News lets you customize search URLs to filter content by keywords, topics, locations, or dates.
For example:
pgsql
CopyEdit
https://news.google.com/search?q=cryptocurrency+after:2024-12-01+before:2025-01-01&hl=en
This URL only shows articles about cryptocurrency published in December 2024. This small trick helps you avoid scraping unrelated news, which reduces noise in your dataset and speeds up your workflow.
The more specific your search, the less data you have to clean later.
Minimize HTTP Requests
Making too many requests per minute not only slows down your scraper, it increases your chances of being blocked. Efficient scraping is about balance.
A few smart practices:
- Scrape only the HTML elements you need. Headlines, source names, timestamps, and links are often enough.
- Avoid loading unnecessary resources like images, scripts, and stylesheets. If you’re using a browser-based scraper like Selenium, disable these by tweaking the settings.
- Use connection pooling and keep-alive sessions in requests or aiohttp to reuse network connections. This speeds things up significantly.
These techniques make your web scraping Google News process lighter, faster, and more sustainable over time.
Normalize and Clean the Data as You Go
The sooner you clean your scraped data, the less trouble you’ll have later. Here’s how to improve data quality right during extraction:
- Strip white space and special characters from headlines.
- Parse timestamps into a consistent date format (like ISO 8601).
- Use domain names as source identifiers instead of full URLs.
- Deduplicate articles by comparing headline text or URLs.
If you let bad data pile up, cleaning it afterward becomes a massive chore. So, build your normalization rules into your scraper from the beginning.
Add Metadata for Contextual Relevance
Sometimes the article’s headline isn’t enough. If you’re doing sentiment analysis, brand monitoring, or trend tracking, you’ll need more context.
Add fields like:
- Scrape timestamp (when your crawler fetched the article)
- Search keyword (what you were querying for)
- Geo or language info (from the URL or content)
- Rank/order on the page (useful for visibility analysis)
These fields aren’t part of the article itself, but they add value to the dataset when used in analytics dashboards or machine learning models.
Test and Log Everything
Don’t trust your scraper blindly. HTML changes all the time, and Google News is no exception. Built in logging and alerts that tell you:
- When elements are missing
- When response codes start failing (403, 429, etc.)
- When unexpected data formats are returned
A robust Google News scraping Python script should handle failure gracefully. If your script quietly breaks and logs nothing, you could be collecting empty rows for weeks.
Common Challenges in Scraping Google News and How to Overcome Them
If you’ve ever tried scraping Google News regularly, you already know it’s not always smooth sailing. While Google doesn’t offer an official News API anymore, scraping its news results still happens widely, but not without hurdles. From technical roadblocks to structural shifts in HTML, let’s break down the most common challenges and how to overcome them efficiently and ethically.
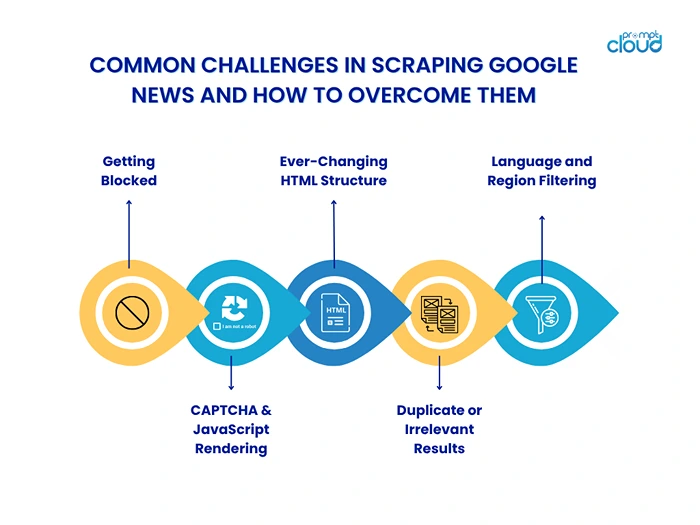
1. Getting Blocked (403 or 429 Errors)
Google isn’t fond of automated scraping, especially at scale. If your scraper is hitting Google News too fast or from the same IP repeatedly, it’ll start throwing HTTP 403 (forbidden) or 429 (too many requests) errors.
Solution:
- Rotate IP addresses using a reliable proxy provider.
- Add random time delays between requests. Mimic human behavior by scraping at irregular intervals.
- Use a rotating User-Agent pool to avoid pattern detection.
- Limit your requests per minute to stay under the radar.
If you’re using a web scraping service, most of this is handled automatically, but if you’re writing your own Google News scraping Python script, you’ll need to implement these techniques manually.
2. CAPTCHA and JavaScript Rendering
Sometimes, when Google detects unusual behavior, it presents a CAPTCHA or requires JavaScript to load certain content. Plain HTML scrapers (like BeautifulSoup) won’t work in these cases.
Solution:
- Use headless browsers like Selenium or Playwright that can interact with JavaScript content.
- For CAPTCHAs, consider using captcha-solving APIs—though these can add costs and ethical complexity.
- Reduce scraping frequency and simulate more “natural” browsing behavior to avoid triggering these protections in the first place.
If scraping CAPTCHAs consistently becomes a bottleneck, it may be time to consider using a web scraping service that already handles these blocks at scale.
3. Ever-Changing HTML Structure
Google often updates its front-end layout to improve the user experience. That means the div or article tags your script relied on yesterday might be gone today. This is one of the most frustrating challenges in web scraping Google News.
Solution:
- Avoid using absolute tag paths like html > body > div > article. Instead, target classes or attributes that are less likely to change, such as aria-label, role, or data-* attributes.
- Regularly monitor HTML changes and set up alerts when your script captures too little data or nothing at all.
- Write modular scraping functions so that updating a selector doesn’t require rewriting the whole scraper.
Many professionals rely on Google News API alternatives or paid data services to reduce the maintenance overhead that comes with structure changes.
4. Duplicate or Irrelevant Results
Scraping from search-based pages like Google News often means you’ll get repetitive articles across multiple queries or similar content from syndicated sources.
Solution:
- Use hashing or fuzzy string matching (like Levenshtein distance) to filter out duplicates based on titles or URLs.
- Add a relevance filter using NLP libraries such as spaCy or keyword-based rules. For example, drop results that don’t mention your target entity in the first 100 words.
- Track canonical links when available—they help in identifying the original source.
Filtering duplicates is a crucial step if you’re building a news analytics pipeline for media monitoring or competitive intelligence.
5. Language and Region Filtering
Sometimes, Google News mixes stories from different regions and languages, which may not fit your use case, especially for localized marketing or political analysis.
Solution:
- Use regional parameters like &hl=en-IN (for Indian English) or &gl=US (for US results).
- Implement language detection on scraped text using tools like langdetect or fastText to automatically sort or filter.
This is especially useful if you’re scraping multiple versions of Google News across different geographies for cross-market trend tracking.
Why Ethical Scraping Matters (And How to Stay Compliant)
When it comes to scraping Google News, the technical part is only half the equation. The other half, often overlooked, is ethics and legality. Just because you can scrape something doesn’t always mean you should. Respecting terms of service, handling copyrighted content carefully, and being transparent about how you use scraped data are crucial if you want to stay out of trouble and build a sustainable data pipeline.
Let’s unpack what ethical scraping really means and how you can apply it in real-world workflows.
Understand Google’s Terms of Service
Google’s Terms of Service explicitly discourage automated scraping of their search engine results, including Google News. That doesn’t mean you can’t collect publicly available news articles—but it does mean you need to be careful about how you access that information.
If you’re pulling headlines and links (but not overloading their servers or bypassing technical barriers), you may be operating in a legally gray area. However, scraping full content or ignoring robots.txt restrictions can put you at risk.
Best practice: Use scraping techniques to discover news URLs, then retrieve full articles directly from the publisher’s website, not Google News itself.
Respect Robots.txt and Crawling Rules
The robots.txt file tells scrapers which parts of a website are off-limits. While it’s not legally binding in many jurisdictions, it’s considered a strong ethical guideline.
Google’s own robots.txt file restricts automated access to some paths, especially those used by Google News and Search. You should honor these rules unless you have explicit permission or are working with tools that use public APIs.
Tip: Always check https://news.google.com/robots.txt before you start building or running scrapers. Respecting these boundaries helps keep your operations under the radar and ethically sound.
Credit the Original Sources
When you’re extracting data from Google News, you’re technically pulling aggregated headlines from many different publishers. That content is often copyrighted, and simply copying it into your system without attribution isn’t just unethical—it may also be illegal.
If you’re using scraped news data for analytics, trend detection, or visualization:
- Always store and reference the source URL.
- Avoid storing or redistributing full article content unless you’re certain you have legal clearance.
- Link back to the original story when presenting insights publicly.
This is particularly important for users in public relations, media monitoring, or market research, where data often gets published or shared.
Avoid Data Hoarding and Abuse
Just because you can scrape thousands of articles per day doesn’t mean you should. Over-scraping is wasteful and increases the risk of being blocked or flagged. Worse, it can lead to partial data that creates misleading insights.
Build a purpose-driven strategy around scraping:
- Focus only on the keywords, topics, or regions that matter to your business.
- Schedule scraping sessions to avoid peak hours.
- Clean and use the data thoughtfully instead of stockpiling it for “just in case” scenarios.
Being selective and efficient isn’t just smart—it’s ethical.
Consider Alternative Approaches
Sometimes the best way to avoid ethical issues is to look beyond scraping altogether. A few options worth exploring:
- Use a Google News API alternative, such as GNews, ContextualWeb, or NewsCatcher, which offer news aggregation from licensed sources.
- Partner with a web scraping service that handles compliance and legality on your behalf.
- Work directly with publishers or licensed news aggregators to access structured feeds legally.
For organizations with serious compliance needs, like those in finance, healthcare, or public policy, outsourcing scraping to a service provider may be the safest and most scalable path.
Turning Scraped News Data into Actionable Intelligence
Image Source: serphouse
Scraping Google News isn’t just about collecting URLs or headlines—it’s about uncovering trends, monitoring sentiment, tracking competitors, and making data-driven decisions. Whether you’re in finance, public relations, or digital marketing, the real value lies in what you do after the data lands in your database.
This final section focuses on transforming your scraped news into insights that help your organization stay ahead.
1. Trend Analysis for Market Signals
One of the biggest advantages of web scraping Google News is early access to emerging trends. By analyzing headline frequency, keyword spikes, and topic clustering, you can detect shifts in public sentiment, market movements, or crisis signals before your competitors do.
For example:
- A spike in negative headlines around a competitor’s product could signal a branding issue you can capitalize on.
- Repeated mentions of regulatory changes in a specific industry might indicate a shift in compliance standards.
By visualizing news data over time (e.g., via time series charts or word clouds), teams can surface hidden patterns and take action faster.
2. Sentiment Monitoring and Brand Perception
Using NLP (Natural Language Processing) tools like TextBlob, spaCy, or transformers-based models, you can apply sentiment scoring to news headlines or summaries. This is particularly useful for PR teams and digital marketing professionals.
Say you’re monitoring how your brand or a partner company is being covered. You can categorize headlines as:
- Positive: Product launches, awards, strong earnings.
- Neutral: General industry mentions, event participation.
- Negative: Scandals, lawsuits, product failures.
Google News scraping Python workflows can integrate sentiment scoring as a post-processing step, allowing teams to filter news based on polarity and urgency.
3. Competitive Intelligence
News data gives you real-time visibility into what your competitors are doing—whether it’s entering a new market, facing a public backlash, or securing funding.
You can scrape and categorize news articles by company, industry, geography, or event type. Over time, this builds a searchable intelligence layer that helps with:
- Product planning
- Crisis preparedness
- M&A research
- Strategic positioning
A daily feed of Google News results, filtered through the lens of competitive tracking, can help leadership teams make faster, smarter decisions.
4. PR and Media Outreach Planning
Digital PR teams often use Google News scraping to analyze how different media outlets cover certain topics, industries, or brands. This helps in:
- Identifying influential journalists and publications.
- Finding gaps in media coverage.
- Timing press releases when interest in a topic is peaking.
By building a database of publication patterns and journalist bylines from news articles, you can personalize pitches and boost your chances of media coverage.
5. Data Enrichment for Business Intelligence
Scraped Google News data can also be layered with internal datasets, such as CRM records, sales data, or stock performance, to add context.
For instance:
- Linking customer churn to negative media coverage.
- Mapping regional sales dips to adverse news in local markets.
- Associating funding rounds or acquisitions with spikes in media sentiment.
This kind of enriched intelligence adds nuance and depth to internal reporting and dashboards, making news data a strategic asset, not just noise.
How PromptCloud Powers Media Monitoring with Web Scraping at Scale
For organizations that rely on real-time information from global newsrooms to PR agencies to competitive intelligence teams, staying updated with media coverage isn’t optional. It’s mission-critical. That’s where PromptCloud comes in.
At PromptCloud, we specialize in large-scale web data extraction that helps businesses track, analyze, and act on news and media trends with precision and speed. Whether you’re monitoring news coverage of your brand, tracking your competitors’ press exposure, or analyzing trends across thousands of global publications, our media monitoring solutions give you the data foundation you need.
What You Get with PromptCloud’s Media Monitoring Services:

1. Real-Time Access to Structured News Data
We help you scrape and structure data from Google News and thousands of other online sources, so you can build a unified stream of articles, headlines, summaries, URLs, timestamps, and more—ready for analysis or integration.
2. Customized Workflows for Specific Use Cases
Need to monitor just the top 50 financial publications? Or extract tech-related articles from specific geographies? We tailor every pipeline to your unique industry or use case, ensuring high relevance and accuracy.
3. Scalable Infrastructure for High-Volume Monitoring
Our cloud-based architecture can support scraping thousands of URLs every day, which is essential for real-time alerts, sentiment dashboards, and daily executive summaries across industries like media, finance, pharmaceuticals, and public relations.
4. Built-in Compliance and Ethical Standards
We ensure that every Google News scraping workflow we create follows responsible scraping practices. We honor site policies, implement polite crawling strategies, and help you stay compliant with data usage norms.
5. Seamless Integration with BI Tools
PromptCloud delivers cleaned, ready-to-use data. This means your analysts can work on insights, not data wrangling.
If you’re ready to power your media monitoring efforts with reliable, structured, and ethical Google News data, PromptCloud’s web scraping services are built for your needs. Whether you’re a startup building a media dashboard or an enterprise scaling its intelligence operations, we’ve got the infrastructure and expertise to deliver news data that moves the needle.
Reach out to us today and discover how PromptCloud can be your strategic data partner in the world of fast-moving news and competitive insights.















