




From market research and price tracking to data collection, web scraping has provided businesses with a plethora of information. The challenge, however, comes with the increasing complexity of websites, which makes obtaining data much more difficult. This is where Large Language Models (LLMs) come into play. With the implementation of LLMs into the web scraping workflow, data scientists, AI researchers, and web scraping engineers have much more control over their scraping processes.
This article will explain how LLMs are transforming web scraping. We will discuss the range of possibilities where LLMs can facilitate better data extraction, processing, and analysis to ensure web scraping is done accurately and efficiently.
What is Web Scraping?
Before discussing the fine points of LLM integration, let us first examine the fundamentals. To web scrape is to obtain information from a website. This process includes making requests to a website and receiving and retrieving its HTML content, which is the skeleton of the website, and scanning through it to extract pertinent information. Usually, the data is in raw form meaning it needs to go through steps to convert it into a format that is usable for analysis.
Not all websites function equally though. Many modern websites are dynamic, meaning that their content changes based on user interactivity, person’s geolocation, or even specific time window during the day. This adds to the level of difficulty in the scraping procedure because employing the conventional scraping methods, it will be nearly impossible to extract useful information.
How Large Language Models (LLMs) Are Transforming Web Scraping?

Image Source: Project Pro
OpenAI’s GPT, Google’s BERT, and T5 are some of the large language models (LLMs) that have deeply transformed the field of Natural Language Processing (NLP). These models achieve high understanding, generation, and processing of human language due to being trained on gargantuan datasets. So, how does this relate to web scraping?
Incorporating LLMs into the workflow of web scraping improves data extraction and processing. An example would be their use in identifying and interpreting complex content, such as natural language text, product descriptions, or social media posts. To sum up, LLMs can result in smarter and more agile web scraping to keep up with the increasing complexity of websites.
1. Improved Data Extraction
One of the areas LLMs excel in is improving the accuracy and relevance of data extraction. Traditionally, automated web scraping employed static patterns such as HTML tags or XPath queries to find data. However, modern websites that incorporate JavaScript and dynamic content render static scraping techniques less effective.
This content can be processed more dynamically. As an example, if a webpage contains comments about a product, an LLM will capture sentiment or key themes, regardless of how their layout changes with respect to the page. While cleaning web pages, you do not have to worry about the fixed structure of HTML tags because an LLM will do it for you. You can now perform web scraping in a more flexible way by extracting and interpreting information based on context rather than position on a page.
2. Enhanced Data Processing
In the processes of web scraping, the most difficult thing is probably to process the data. Information that is collected is often in a raw form and most of the time is incomplete and needs to be cleaned so it can be used for analysis. One way to do this is for LLMs to perform the scraping actions automatically for cleaning, parsing, and structuring the data.
For example, when scraping prices for a product across several online marketplaces, LLMs will assist in recognizing the price tag even if they are located in different positions on the webpage. They will also help recognize product names, categories, descriptions, and other relevant data. A lot of custom complex scripts will not be needed that would otherwise require constant changes. A lot of the work is done through the LLM which smoothens the process.
3. Natural Language Understanding for Unstructured Data
With the use of LLMs, web scraping is advanced to the stage of retrieving unstructured information like reviews, comments, and social media postings. The analysis and measurement of such types of data is troublesome because they are too informal.
For instance, imagine that you want to scrape customer reviews on an e-commerce website. Typical scrapers may simply extract the text, which can be utterly useless. Reviews can be emotionally analyzed and described as frustrated, content, or having suggestions for the item. This makes the data more useful, which can be even more insightful to companies.
4. Improved Handling of JavaScript-Heavy Websites
Scraping websites that use JavaScript extensively is a challenge for most traditional scraping tools because they cannot interact with JavaScript. Modern websites heavily depend on JavaScript to load information. However, LLMs come with vast benefits, especially when used with headless browsers.
Incorporating LLMs into your scraping workflow makes it easier to work with content displayed by JavaScript. Instead of only extracting the HTML code, LLMs comprehend the logic and reasoning behind the dynamically loaded content. This enables better scraping of websites that rely heavily on JavaScript.
5. Scalability and Automation
Web scraping using LLMs is highly scalable. Once trained or fine-tuned for a particular task, LLMs can automate the extraction and analysis of data from numerous websites simultaneously. Whether you’re scraping news articles, product listings, or competitor information, LLMs can efficiently scale to handle large volumes of data without compromising on quality.
Additionally, as web scraping tasks evolve or new websites are targeted, LLMs can be easily retrained or adjusted. This adaptability makes LLMs a future-proof solution for web scraping, allowing engineers and data scientists to scale their operations with minimal overhead.
How to Leverage LLMs for Smarter Web Scraping Workflows?
Integrating LLMs into web scraping processes can be achieved with relative ease. The following are the steps that need to be carried out:
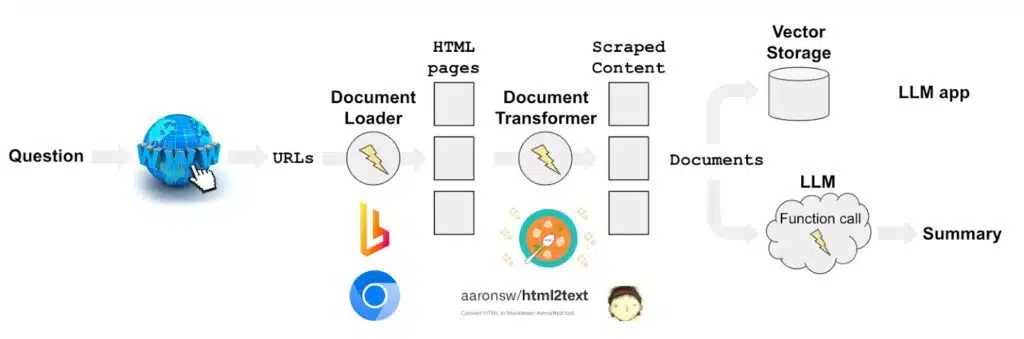
Image Source: Medium
1. Choose the Right LLM
To start off, select which model would best suit your web scraping needs. Your options may include OpenAI’s GPT models or Google’s BERT. Selecting which model to go for depends on the specific criteria your scraping tasks are going to have. Some models perform better in generating language while some specialize in understanding the language.
2. Fine-Tune the Model
Although LLMs come equipped with a great amount of data and therefore have a good baseline, they can be customized and made more precise by incorporating your specific scraping tasks. You can fine-tune the model with the set of URLs of your target web pages or the specific type of content that you are scraping. This includes, but is not limited to, product descriptions, user reviews, and articles or news pieces.
3. Integrate the LLM with Your Scraping Framework
Lastly, the LLM has to be placed within the existing web scraping framework. Usually, this requires setting up scripts or APIs to handle the scraping activities and send post-processed data to the LLM. The LLM can facilitate tasks such as sentiment analysis, categorization, and entity extraction.
4. Monitor and Optimize the Model
Proper oversight ensures the optimal functioning of LLMs, just like any other AI model. Regular checks should be put in place to assess processing and extraction accuracy for possible planned model retraining. The model can be kept up to date as new data is collected and changes in content types are encountered.
How LLMs Are Shaping the Future of Web Scraping?
The need to control web scraping activities using LLMs will notably increase with the advancement of these technologies. In the coming times, the entire process of data extraction will be automated, with little to no user involvement. Moreover, advanced LLMs will be able to perform higher-level tasks like intent recognition, sarcasm detection, or understanding scraped data cultural context.
With the introduction of LLMs, web scrapers, data scientists, and AI researchers stand to benefit from these innovations and help structure the data in a more refined way for deep analysis and incorporation of new algorithms.
Conclusion
It wouldn’t be far-fetched to say that implementing LLMs in web scraping is poised to transform data extraction, processing, and analysis. The unstructured data handling capabilities of LLMs make it possible for them to improve accuracy and scale in ways previously unseen.
For data scientists and web scraping engineers, the level of ease in performing their tasks will drastically change. For those wishing to improve their web scraping skillset, this is the opportunity they have been looking for.
LLMs could also be the answer you’ve been looking for when trying to scrape product information, market research, and reviews as they afford greater accuracy, more time, and deeper analysis. With LLM’s efficiency in web scraping, data collection will be easier than it has ever been.
With the adoption of web scraping applied LLMs, you will outpace rivals, improve your data collection strategies, and most importantly, be in a position to make wiser, more informed decisions. Schedule a demo with PromptCloud today to see how our solutions can take your data extraction to the next level. Get in touch now and explore the future of smart data scraping!















