




Introduction to LLMs and the Importance of GPU Optimization
In today’s era of natural language processing (NLP) advancements, Large Language Models(LLMs) have emerged as powerful tools for a myriad of tasks, from text generation to question-answering and summarization. These are more than a next-probable token generator. However, the growing complexity and size of these models pose significant challenges in terms of computational efficiency and performance.
In this blog, we delve into the intricacies of GPU architecture, exploring how different components contribute to LLM inference. We will discuss key performance metrics, such as memory bandwidth and tensor core utilization, and elucidate the differences between various GPU cards, enabling you to make informed decisions when selecting hardware for your large language models tasks.
In a rapidly evolving landscape where NLP tasks demand ever-increasing computational resources, optimizing LLM inference throughput is paramount. Join us as we embark on this journey to unlock the full potential of LLMs through GPU optimization techniques, and delve into various tools that enable us to effectively improve the performance.
GPU Architecture Essentials for LLMs – Know your GPU Internals
With the nature of performing highly efficient parallel computation, GPUs become the device of choice to run all deep learning tasks, so it is important to understand the high level overview of GPU architecture to understand the underlying bottlenecks that arise during the inference stage. Nvidia cards are preferred due to CUDA(Compute Unified Device Architecture), a proprietary parallel computing platform and API developed by NVIDIA, which allows developers to specify thread-level parallelism in C programming language, providing direct access to the GPU’s virtual instruction set and parallel computational elements.
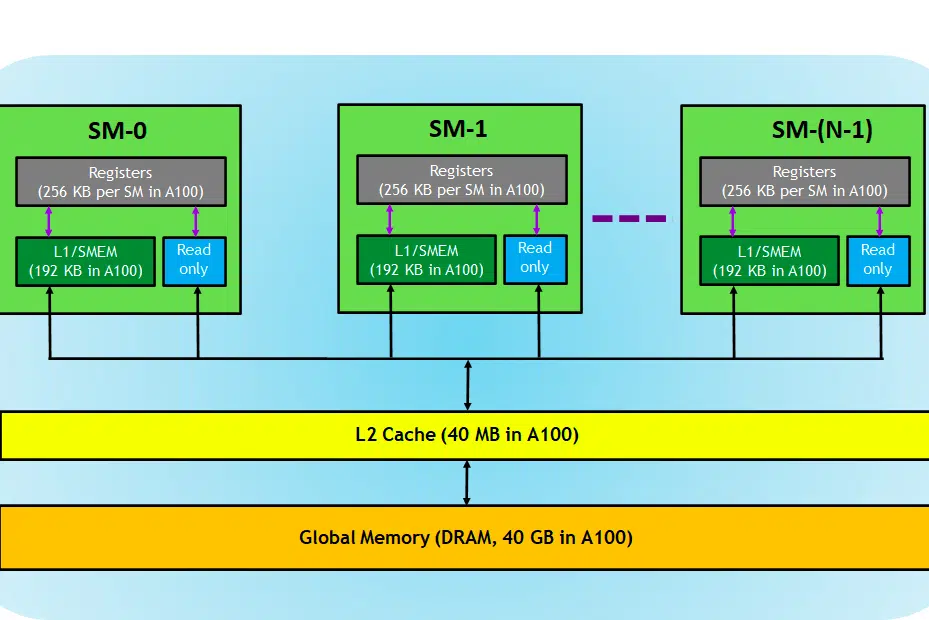
For the context, we used a NVIDIA card for explanation because it is widely preferred for Deep Learning tasks as already stated and few other terms like Tensor Cores are applicable to that.
Let’s take a look at GPU card, here in the image, we can see three main parts and(one more major hidden part) of a GPU device
- SM (Streaming Multiprocessors)
- L2 cache
- Memory Bandwidth
- Global Memory(DRAM)
Just like your CPU-RAM plays together, RAM being the place for data residence (i.e memory) and CPU for processing tasks (i.e process). In a GPU, the High bandwidth Global Memory(DRAM) holds the model(e.g LLAMA 7B) weights that are loaded into memory and when needed, these weights are transferred to the processing unit (i.e. SM processor) for calculations.
Streaming Multiprocessors
A streaming multiprocessor or SM is a collection of smaller execution units called CUDA cores(Proprietary parallel computing platform by NVIDIA), along with additional functional units responsible for instruction fetch, decode, scheduling, and dispatch. Each SM operates independently and contains its own register file, shared memory, L1 cache, and texture unit. SMs are highly parallelized, allowing them to process thousands of threads concurrently, which is essential for achieving high throughput in GPU computing tasks. Performance of the processor is generally measured in FLOPS, the no. of floating operations it can perform each sec.
Deep learning tasks mostly consist of tensor operations i.e matrix-matrix multiplication, nvidia introduced tensor cores in newer generation GPUs, which are designed specifically to perform these tensor operations in a highly efficient manner. As mentioned, tensor cores are useful when it comes to deep learning tasks and instead of CUDA cores, we must check on the Tensor cores to determine how efficiently a GPU can perform the training/ inference of LLM.
L2 Cache
L2 cache is a high bandwidth memory that is shared among SMs aimed to optimize memory access and data transfer efficiency within the system. It is a smaller, faster type of memory that resides closer to the processing units (such as Streaming Multiprocessors) compared to DRAM. It helps improve overall memory access efficiency by reducing the need to access the slower DRAM for every memory request.
Memory Bandwidth
So, the performance depends on how quickly we can transfer the weights from memory to processor and how efficiently and quickly the processor can process the given calculations.
When the compute capacity is higher/ faster than the data transfer rate between memory to SM, the SM will starve for data to process and thus compute is underutilized, this situation where memory bandwidth is lower than the consumption rate is known as memory-bound phase. This is very important to note as this is the prevailing bottleneck in the inference process.
To the contrary, if the compute is taking more time for processing and if more data is queued for computation, this state is a compute-bound phase.
To fully take advantage of the GPU, we must be in a compute-bound state while making the occuring computations as efficiently as possible.
DRAM Memory
DRAM serves as the primary memory in a GPU, providing a large pool of memory for storing data and instructions needed for computation. It is typically organized in a hierarchy, with multiple memory banks and channels to enable high-speed access.
For the inference task the DRAM of the GPU determines how big of a model we can load and the compute FLOPS and bandwidth determines the throughput which we can obtain.
Comparing GPU Cards for LLM Tasks
For getting info about the numbers of the tensor cores, bandwidth speed, one can go through the whitepaper released by the GPU manufacturer. Here is a example,
| RTX A6000 | RTX 4090 | RTX 3090 | |
| Memory Size | 48 GB | 24 GB | 24 GB |
| Memory Type | GDDR6 | GDDR6X | |
| Bandwidth | 768.0 GB/s | 1008 GB/sec | 936.2 GB/s |
| CUDA Cores / GPU | 10752 | 16384 | 10496 |
| Tensor Cores | 336 | 512 | 328 |
| L1 Cache | 128 KB (per SM) | 128 KB (per SM) | 128 KB (per SM) |
| FP16 Non-Tensor | 38.71 TFLOPS (1:1) | 82.6 | 35.58 TFLOPS (1:1) |
| FP32 Non-Tensor | 38.71 TFLOPS | 82.6 | 35.58 TFLOPS |
| FP64 Non-Tensor | 1,210 GFLOPS (1:32) | 556.0 GFLOPS (1:64) | |
| Peak FP16 Tensor TFLOPS with FP16 Accumulate | 154.8/309.6 | 330.3/660.6 | 142/284 |
| Peak FP16 Tensor TFLOPS with FP32 Accumulate | 154.8/309.6 | 165.2/330.4 | 71/142 |
| Peak BF16 Tensor TFLOPS with FP32 | 154.8/309.6 | 165.2/330.4 | 71/142 |
| Peak TF32 Tensor TFLOPS | 77.4/154.8 | 82.6/165.2 | 35.6/71 |
| Peak INT8 Tensor TOPS | 309.7/619.4 | 660.6/1321.2 | 284/568 |
| Peak INT4 Tensor TOPS | 619.3/1238.6 | 1321.2/2642.4 | 568/1136 |
| L2 Cache | 6 MB | 72 MB | 6 MB |
| Memory Bus | 384 bit | 384 bit | 384 bit |
| TMUs | 336 | 512 | 328 |
| ROPs | 112 | 176 | 112 |
| SM Count | 84 | 128 | 82 |
| RT Cores | 84 | 128 | 82 |
Here we can see FLOPS is specifically mentioned for Tensor operations, this data will help us compare the different GPU cards and shortlist the suitable one for our use case. From the table, although the A6000 has twice the memory of 4090, the tensore flops and memory bandwidth of 4090 are better in numbers and thus more powerful for the large language models inference.
Further read: Nvidia CUDA in 100 Seconds
Conclusion
In the rapidly advancing field of NLP, the optimization of Large Language Models (LLMs) for inference tasks has become a critical area of focus. As we have explored, the architecture of GPUs plays a pivotal role in achieving high performance and efficiency in these tasks. Understanding the internal components of GPUs, such as Streaming Multiprocessors (SMs), L2 cache, memory bandwidth, and DRAM, is essential for identifying the potential bottlenecks in LLM inference processes.
The comparison between different NVIDIA GPU cards—RTX A6000, RTX 4090, and RTX 3090 – reveals significant differences in terms of memory size, bandwidth, and the number of CUDA and Tensor Cores, among other factors. These distinctions are crucial for making informed decisions about which GPU is best suited for specific LLM tasks. For instance, while the RTX A6000 offers a larger memory size, the RTX 4090 excels in terms of Tensor FLOPS and memory bandwidth, making it a more potent choice for demanding LLM inference tasks.
Optimizing LLM inference requires a balanced approach that considers both the computational capacity of the GPU and the specific requirements of the LLM task at hand. Selecting the right GPU involves understanding the trade-offs between memory capacity, processing power, and bandwidth to ensure that the GPU can efficiently handle the model’s weights and perform calculations without becoming a bottleneck. As the field of NLP continues to evolve, staying informed about the latest GPU technologies and their capabilities will be paramount for those looking to push the boundaries of what is possible with Large Language Models.
Terminology Used
- Throughput:
Incase of inference, throughput is the measure of how many requests/ prompts are processed for a given period of time. Throughput is typically measured in two ways:
- Requests per Second (RPS):
- RPS measures the number of inference requests a model can handle within a second. An inference request typically involves generating a response or prediction based on input data.
- For LLM generation, RPS indicates how quickly the model can respond to incoming prompts or queries. Higher RPS values suggest better responsiveness and scalability for real-time or near-real-time applications.
- Achieving high RPS values often requires efficient deployment strategies, such as batching multiple requests together to amortize overhead and maximize utilization of computational resources.
- Tokens per Second (TPS):
- TPS measures the speed at which a model can process and generate tokens (words or subwords) during text generation.
- In the context of LLM generation, TPS reflects the model’s throughput in terms of generating text. It indicates how quickly the model can produce coherent and meaningful responses.
- Higher TPS values imply faster text generation, allowing the model to process more input data and generate longer responses in a given amount of time.
- Achieving high TPS values often involves optimizing model architecture, parallelizing computations, and leveraging hardware accelerators like GPUs to expedite token generation.
- Latency:
Latency in LLMs refers to the time delay between input and output during inference. Minimizing latency is essential for enhancing user experience and enabling real-time interactions in applications leveraging LLMs. It is essential to strike a balance between throughput and latency based on the service we need to provide. Low latency is desirable for the case like real-time interaction chatbots/ copilot but not necessary for bulk data processing cases like internal data reprocess.
Read more on Advanced Techniques for Enhancing LLM Throughput here.















