




In the fast-paced world of technology, Large Language Model (LLMs) have become key players in how we interact with digital information. These powerful tools can write articles, answer questions, and even hold conversations, but they’re not without their challenges. As we demand more from these models, we run into hurdles, especially when it comes to making them work faster and more efficiently. This blog is about tackling those hurdles head-on.
We’re diving into some smart strategies designed to boost the speed at which these models operate, without losing the quality of their output. Imagine trying to improve the speed of a race car while ensuring it can still navigate tight corners flawlessly—that’s what we’re aiming for with large language models. We’ll look into methods like Continuous Batching, which helps process information more smoothly, and innovative approaches like Paged and Flash Attention, which make LLMs more attentive and quicker in their digital reasoning.
So, if you’re curious about pushing the limits of what these AI giants can do, you’re in the right place. Let’s explore together how these advanced techniques are shaping the future of LLMs, making them faster and better than ever before.
Challenges in Achieving Higher Throughput for LLMs
Achieving higher throughput in Large Language Models (LLMs) faces several significant challenges, each acting as a hurdle to the speed and efficiency with which these models can operate. One primary obstacle is the sheer memory requirement needed to process and store the vast amounts of data these models work with. As LLMs grow in complexity and size, the demand on computational resources intensifies, making it challenging to maintain, let alone enhance, processing speeds.
Another major challenge is the auto-regressive nature of LLMs, especially in models used for generating text. This means that the output at each step is dependent on the previous ones, creating a sequential processing requirement that inherently limits how quickly tasks can be executed. This sequential dependency often results in a bottleneck, as each step must wait for its predecessor to complete before it can proceed, hampering efforts to achieve higher throughput.
Additionally, the balance between accuracy and speed is a delicate one. Enhancing throughput without compromising the quality of the output is a tightrope walk, requiring innovative solutions that can navigate the complex landscape of computational efficiency and model effectiveness.
These challenges form the backdrop against which advancements in LLM optimization are made, pushing the boundaries of what’s possible in the realm of natural language processing and beyond.
Memory Requirement
The decode phase generates a single token at each time step, but each token depends on the key and value tensors of all previous tokens (including the input tokens’ KV tensors computed at prefill, and any new KV tensors computed until the current time step).
Therefore, as to minimize the redundant calculations every time and to avoid recomputing all these tensors for all tokens at each time step, it is possible to cache them in GPU memory. Every iteration, when new elements are computed, they are simply added to the running cache to be used in the next iteration. This is essentially known as the KV cache.
This majorly reduces the computation needed greatly but introduces a memory requirement along with already higher memory requirements for large language models which makes it difficult to run on commodity GPUs. With the increasing model parameters size(7B to 33B) and the higher precision (fp16 to fp32) the memory requirements also increases. Lets see an example for the required memory capacity,
As we know the two major memory occupants are
- Model’s own weights in memory, this comes with no. of parameters like 7B and data type of each parameter e.g, 7B in fp16(2 byte) ~= 14GB in memory
- KV cache: The cache used for key value of self-attention stage to avoid redundant calculation.
Size of KV cache per token in bytes = 2 * (num_layers) * (hidden_size) * precision_in_bytes
The first factor 2 accounts for K and V matrices. These hidden_size and dim_head can be obtained from the model’s card or the config file.
The above formula is per token, so for a sequence of input, it will be seq_len * size_of_kv_per_token. So the above formula will transform to,
Total size of KV cache in bytes = (sequence_length) * 2 * (num_layers) * (hidden_size) * precision_in_bytes
For eg, with LLAMA 2 in fp16, the size will be (4096) * 2 * (32) * (4096) * 2, which is ~2GB.
This above is for a single input, with multiple inputs this grows quickly, this on-flight memory allocation and management thus becomes a crucial step to achieve optimal performance, if not results in Out of Memory and fragmentation issues.
Sometimes, the memory requirement is more than the capacity of our GPU, in those cases, we need to look into model parallelism, tensor parallelism which is not covered here but you can explore in that direction.
Auto-regressiveness & memory bound operation
As we can see, the output generation part of large language models is auto-regressive in nature. The indicates for any new token to be generated, it depends on all the previous tokens and its intermediate states. Since in the output stage not all tokens are available to do further calculation, and it has only one vector(for next token) and the block of previous stage, this becomes like a matrix-vector operation which under-utilizes the GPU compute ability when compared to the prefill phase. The speed at which the data (weights, keys, values, activations) is transferred to the GPU from memory dominates the latency, not how fast the computations actually happen. In other words, this is a memory-bound operation.
Innovative Solutions to Overcome Throughput Challenges
Continuous batching
The very simple step to reduce the memory bound nature of the decode stage is to batch the input and do computations for multiple inputs at once. But a simple constant batching has resulted in poor performance due to the nature of varying sequence lengths being generated and here the latency of a batch is dependent on the longest sequence that is being generated in a batch and also with growing memory requirement since multiple inputs are now processed at once.
Therefore, simple static batching is ineffective and there comes the continuous batching. Its essence lies in dynamically aggregating incoming request batches, adapting to fluctuating arrival rates, and exploiting opportunities for parallel processing whenever feasible. This also optimizes memory utilization by grouping sequences of similar lengths together in each batch which minimizes the amount of padding needed for shorter sequences and avoids wasting computational resources on excessive padding.
It adaptively adjusts the batch size based on factors such as the current memory capacity, computational resources, and input sequence lengths. This ensures that the model operates optimally under varying conditions without exceeding memory constraints. This in help with paged attention(explained below) helps in reducing the latency and increasing the throughput.
Further read: How continuous batching enables 23x throughput in LLM inference while reducing p50 latency
Paged Attention
As we do batching to improve the throughput, it also comes at the cost of increased KV cache memory requirement, since we are now processing multiple inputs at once. These sequences can exceed the memory capacity of available computational resources, making it impractical to process them in their entirety.
It is also observed that naive memory allocation of KV cache results in a lot of memory fragmentation just like how we observe in computer systems due to uneven allocation of memory. vLLM introduced Paged Attention which is a memory management technique inspired from operating system concepts of paging and virtual memory to efficiently handle the growing requirement of KV cache.
Paged Attention addresses memory constraints by dividing the attention mechanism into smaller pages or segments, each covering a subset of the input sequence. Rather than computing attention scores for the entire input sequence at once, the model focuses on one page at a time, processing it sequentially.
During inference or training, the model iterates through each page of the input sequence, computing attention scores and generating output accordingly. Once a page is processed, its results are stored, and the model moves on to the next page.
By dividing the attention mechanism into pages, Paged Attention allows Large language model to handle input sequences of arbitrary length without exceeding memory constraints. It effectively reduces the memory footprint required for processing long sequences, making it feasible to work with large documents and batches.
Further read: Fast LLM Serving with vLLM and PagedAttention
Flash attention
As the attention mechanism is crucial for transformer models which the large language models are based on, it helps the model focus on relevant parts of the input text when making predictions. However, as transformer-based models become larger and more complex, the self-attention mechanism becomes increasingly slow and memory-intensive, leading to a memory bottleneck problem as mentioned earlier. Flash Attention is another optimization technique which aims to mitigate this issue by optimizing attention operations, allowing for faster training and inference.
Key Features of Flash Attention:
Kernel Fusion: It is important to not just maximize the GPU compute usage, but also make it do as efficient operations are possible. Flash Attention combines multiple computation steps into a single operation, reducing the need for repetitive data transfers. This streamlined approach simplifies the implementation process and enhances computational efficiency.
Tiling: Flash Attention divides the loaded data into smaller blocks, aiding parallel processing. This strategy optimizes memory usage, enabling scalable solutions for models with larger input sizes.
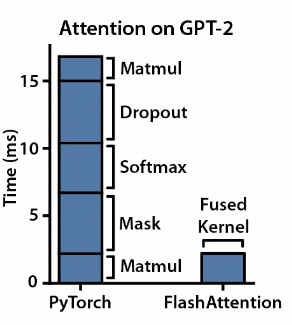
(Fused CUDA kernel depicting how tiling and fusion reduces the time required for calculation, Image source: FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness)
Memory Optimization: Flash Attention loads parameters for only the past few tokens, reusing activations from recently computed tokens. This sliding window approach reduces the number of IO requests to load weights and maximizes flash memory throughput.
Reduced Data Transfers: Flash Attention minimizes the back-and-forth data transfers between memory types, such as High Bandwidth Memory (HBM) and SRAM (Static Random-Access Memory). By loading all the data (queries, keys, and values) just once, it reduces the overhead of repetitive data transfers.
Case Study – Optimizing Inference with Speculative Decoding
Another method employed to expedite text generation in autoregressive language model is speculative decoding. The main objective of speculative decoding is to fasten text generation while preserving the quality of the generated text at a level comparable to that of the target distribution.
Speculative decoding introduces a small/ draft model which predicts the subsequent tokens in the sequence, which are then accepted/ rejected by the main model based on predefined criteria. Integrating a smaller draft model with the target model significantly enhances the speed of text generation, this is due to the nature of memory requirement. Since the draft model is small, it requires less no. of neuron weights to be loaded and the no. of computation is also less now compared to the main model, this reduces latency and speeds up the output generation process. The main model then evaluates the results which are generated and ensures it fits within the target distribution of the next probable token.
In essence, speculative decoding streamlines the text generation process by leveraging a smaller, swifter draft model to predict the subsequent tokens, thereby accelerating the overall speed of text generation while maintaining the quality of the generated content close to the target distribution.
It is very important that the tokens generated by smaller models are not always constantly rejected, this case leads to performance decrease instead of improvement. Through experiments and the nature of use cases we can select a smaller model/ introduce speculative decoding into the inference process.
Conclusion
The journey through the advanced techniques for enhancing Large Language Model (LLM) throughput illuminates a path forward in the realm of natural language processing, showcasing not just the challenges but the innovative solutions that can meet them head-on. These techniques, from Continuous Batching to Paged and Flash Attention, and the intriguing approach of Speculative Decoding, are more than just incremental improvements. They represent significant leaps forward in our ability to make large language models faster, more efficient, and ultimately more accessible for a wide range of applications.
The significance of these advancements cannot be overstated. In optimizing LLM throughput and improving performance, we’re not just tweaking the engines of these powerful models; we’re redefining what’s possible in terms of processing speed and efficiency. This, in turn, opens up new horizons for the application of large language model, from real-time language translation services that can operate at the speed of conversation, to advanced analytics tools capable of processing vast datasets with unprecedented speed.
Moreover, these techniques underscore the importance of a balanced approach to large language model optimization – one that carefully considers the interplay between speed, accuracy, and computational resources. As we push the boundaries of LLM capabilities, maintaining this balance will be crucial for ensuring that these models can continue to serve as versatile and reliable tools across a myriad of industries.
The advanced techniques for enhancing large language model throughput are more than just technical achievements; they are milestones in the ongoing evolution of artificial intelligence. They promise to make LLMs more adaptable, more efficient, and more powerful, paving the way for future innovations that will continue to transform our digital landscape.
Read more about GPU Architecture for large language model Inference Optimization in our recent blog post















