




If you’ve ever scraped a website that loads half its content with JavaScript, you know how frustrating it can be. One minute you’re pulling clean HTML; the next, you’re staring at empty divs or “Loading…” messages. That’s usually the point where most people realize they need something more powerful than just requests and BeautifulSoup.
Enter the headless browser.
In plain terms, a headless browser is just a regular web browser, but without the visual part. No tabs, no windows, nothing pops up. It runs in the background, loading pages, clicking buttons, scrolling through content, just like a human would, but invisibly.
So, why does this matter for scraping? Because modern websites aren’t static anymore. They load data on the fly, hide things behind scripts, and require interaction. A headless browser handles all of that for you. It gives your script eyes and hands, but doesn’t slow you down with a visible interface.
If you’re serious about web scraping, whether you’re pulling product data, prices, reviews, or listings, you will want something that can keep up. A Python headless browser setup with Selenium is one of the best ways to do that right now.
Let’s break down how it works and how you can set it up.
How Headless Browsers Work: The Brains Behind the Curtain
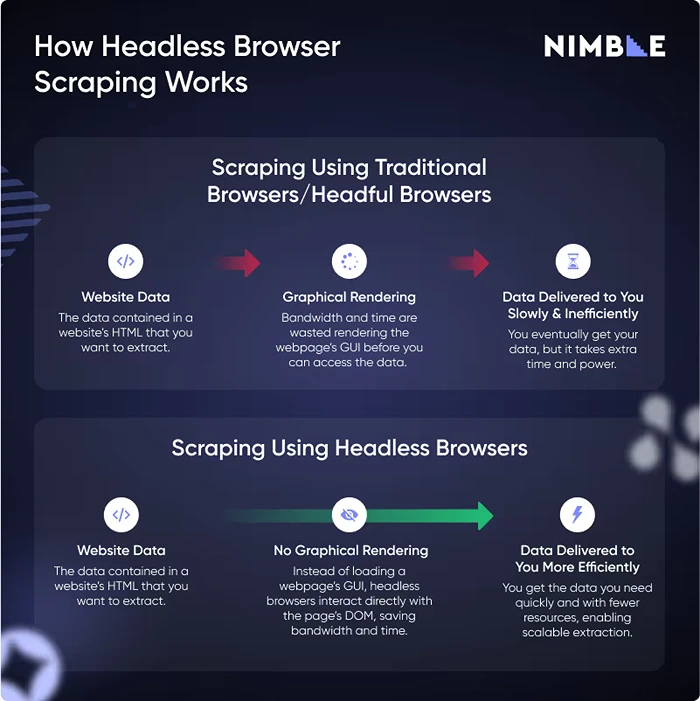
Image Source: Nimbleway
Let’s get something straight—a headless browser doesn’t do anything magical. It just does everything a normal browser does, without showing you anything. It opens a webpage, runs the scripts, renders the layout, and even clicks around if you tell it to. The only difference? You don’t see any of it happen.
This is huge for scraping because a lot of modern websites are built to serve content after the page loads. The HTML you see when you “view source” is often just a shell. The actual data, like prices, reviews, or even the product list, gets filled in later by JavaScript. Simple scraping tools miss all of that.
A headless browser for scraping doesn’t. It waits for the page to fully load, runs the scripts, and gives you the final result, just like you’d see in a normal browser window.
And since it skips the visual stuff, it runs faster and uses fewer resources. That means you can run multiple scrapers in parallel without slowing your machine to a crawl. This is especially helpful when you’re dealing with a high number of URLs or scraping on a schedule.
If you’re wondering whether headless browser Selenium setups can handle interactive pages, yes, they can. You can tell them to click buttons, fill out forms, or scroll through infinite content. And since it’s all happening without a GUI, it runs quietly in the background, letting your machine breathe.
Setting Up Python and Selenium for Headless Browsing
Alright, now that you know why headless browsers matter, let’s get our hands dirty. Setting up a Python headless browser using Selenium is actually easier than most people think. If you’ve already got Python installed, you’re halfway there.
Step 1: Install the Required Packages
You’ll need two main things: Selenium and a browser driver (we’ll use Chrome for this guide). Open your terminal or command prompt and run:
bash
CopyEdit
pip install selenium
Next, download ChromeDriver from the official site (make sure the version matches your Chrome browser) and either place it in your working directory or set the path in your script.
If you don’t want to manually manage ChromeDriver, you can use webdriver-manager:
bash
CopyEdit
pip install webdriver-manager
Step 2: Write a Basic Headless Script
Here’s a simple example of how to launch a headless Chrome browser with Selenium:
Image Source: Lambdatest
python
CopyEdit
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
# Set up headless mode
options = Options()
options.headless = True # or: options.add_argument(‘–headless’)
# Start the browser
driver = webdriver.Chrome(ChromeDriverManager().install(), options=options)
# Open a page
driver.get(“https://example.com”)
# Print the title to confirm it worked
print(driver.title)
# Always quit when done
driver.quit()
That’s it. You just opened a browser, loaded a page, and grabbed its title—all without ever seeing a browser window pop up.
What’s Happening Behind the Scenes?
- Options() lets you configure how Chrome runs. When you set it to headless, it skips the GUI entirely.
- webdriver.Chrome() starts up Chrome in the background.
- driver.get() loads the webpage as if you were clicking it yourself.
- You can now inspect elements, click buttons, or extract text—exactly as you would with a normal browser.
This setup is the backbone of most headless browsers for scraping workflows in Python. From here, it’s all about scaling and targeting the right data.
Advantages of Using Headless Browsers for Web Scraping
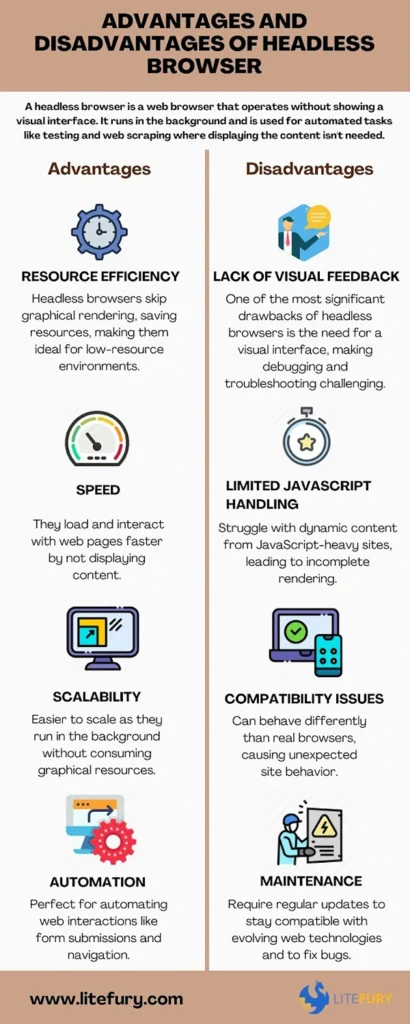
Image Source: litefury
You might be wondering, “Why go through all this trouble when I can just use requests or BeautifulSoup?” Totally fair question. The truth is, those tools are great—but only for static pages. The second JavaScript enters the picture, they start to fall short. That’s where a headless browser for scraping really earns its keep.
Speed and Efficiency
A headless browser skips all the GUI overhead—no rendering tabs, windows, buttons, or visuals. That means it loads faster and uses less memory. When you’re scraping hundreds or thousands of pages, this makes a real difference. You can even run multiple scraping sessions at once without crushing your system.
Handles JavaScript Like a Pro
A lot of sites now use frameworks like React, Angular, or Vue. These don’t load content in the raw HTML—they generate it dynamically after the page loads. A headless browser runs all that JavaScript in the background, waits for it to finish, and gives you access to the fully rendered page.
So if you’re scraping something like an e-commerce site where product prices or availability only appear after the page loads, headless browser Selenium is the tool you want.
Works Just Like a Real User
Want to log into a site, click buttons, or scroll down to trigger infinite loading? A Python headless browser can do all of that. It behaves like a real user, which means websites are less likely to break your scraper with anti-bot tactics, especially if you add some smart delays and user-agent headers.
Lower Resource Use
This might not sound like a big deal at first, but when you scale up—running multiple scrapers, or deploying them on cloud servers—lower CPU and RAM usage starts to matter. Since there’s no graphical interface, headless browser setups use fewer resources, which saves both time and money.
Automation-Friendly
Because everything runs behind the scenes, it’s easy to plug headless browsers into automated workflows. Want to schedule a scraper every night to pull updated pricing data? Easy. Want to run 10 scrapers in parallel inside Docker containers? Headless mode makes it possible.
A Practical Example: Using Headless Browser Selenium to Scrape Dynamic Data
Let’s put all this theory into action. Suppose you want to scrape product listings, including names and prices, from a website that loads data dynamically (like most e-commerce sites today). This is a common use case where a headless browser really shines.
Here’s a practical script using Python, Selenium, and headless Chrome to extract dynamic content:
Goal: Scrape Product Names and Prices from a Dynamically Rendered Page
Let’s assume we’re targeting a basic structure like this (you can swap in your own site):
html
CopyEdit
<div class=”product”>
<span class=”product-name”>Cool T-Shirt</span>
<span class=”price”>$25.99</span>
</div>
Python Code Example:
python
CopyEdit
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
import time
# Set up headless Chrome
options = Options()
options.add_argument(“–headless”)
options.add_argument(“–disable-gpu”)
options.add_argument(“–no-sandbox”)
# Start browser
driver = webdriver.Chrome(ChromeDriverManager().install(), options=options)
# Go to the target website
driver.get(“https://example.com/products”)
# Wait for JavaScript to load (adjust as needed)
time.sleep(3)
# Find product containers
products = driver.find_elements(By.CLASS_NAME, “product”)
# Loop through products and extract info
for product in products:
name = product.find_element(By.CLASS_NAME, “product-name”).text
price = product.find_element(By.CLASS_NAME, “price”).text
print(f”{name}: {price}”)
# Clean up
driver.quit()
Why This Works
- The script launches a headless browser, loads the page, and gives JavaScript time to render.
- It then grabs all the div.product elements and pulls out the product-name and price inside each.
- Even though the data wasn’t visible in the raw HTML at first, the headless browser waited for the full page to finish loading before scraping it.
You could also extend this to:
- Scroll the page for infinite loading
- Click “Load More” buttons
- Log in with credentials and scrape data behind a login wall
This is where using a headless browser for scraping beats traditional scrapers every time. You’re working with real-time, fully-loaded content, not just a snapshot of raw HTML.
Best Practices and Considerations When Scraping with a Headless Browser
Using a headless browser for web scraping is a powerful move, but there’s a line between scraping smart and scraping sloppy. If you want your scrapers to last, perform well, and stay out of trouble, there are a few things you’ll want to keep in mind.
Understand What You’re Allowed to Scrape
Just because data is on a website doesn’t always mean it’s free to take. Some sites are fine with bots pulling data; others, not so much. Before you start scraping, take a quick look at the site’s robots.txt file. It’s like a polite note from the site telling bots where they’re welcome and where they’re not.
Now, robots.txt isn’t legally binding, but ignoring it can get you blocked fast. And if you’re scraping pages behind a login, or grabbing copyrighted data for resale? That’s where things can get legally murky. If you’re doing this for a business, make sure your legal team is in the loop.
Don’t Hit the Site Like a Sledgehammer
It’s tempting to spin up a headless browser Selenium scraper and blast through hundreds of pages in minutes. But websites notice that kind of traffic, and they don’t like it. Too many rapid requests can get your IP blocked, or worse, your business blacklisted.
Instead, slow things down a bit. Add random delays between page loads so you don’t look like a machine. You can do something as simple as:
python
CopyEdit
import time, random
time.sleep(random.uniform(1, 3)) # Pause 1–3 seconds
It makes your scraper feel more “human” and helps you stay under the radar.
Plan for Things to Break (Because They Will)
Web pages change. Elements move around. Sometimes, a page doesn’t load at all. If your scraper falls apart the moment something goes wrong, it won’t get very far.
Wrap your scraping logic in try-except blocks, add error logs, and have a plan for what to do when an element is missing or a request times out. A little resilience goes a long way.
Don’t Always Use a Headless Browser
Here’s a quick tip: not every scraping job needs Selenium. If the page is simple, with no JavaScript-generated content, a regular request + BeautifulSoup setup is faster and lighter.
Headless browsers shine when you need to wait for JavaScript, click buttons, or mimic a real user. Otherwise, keep it simple—you’ll save time and server resources.
Watch Out for Bot Detection
Websites are getting smarter. They know the tricks. If you’re using default Selenium settings or running Chrome in headless mode without any disguises, you’ll stick out like a sore thumb.
To stay under the radar, you can:
- Set a realistic user-agent string (something a real browser would use).
- Avoid using options.headless = True if a site seems suspicious—some sites can detect it.
- Randomize your headers and add natural behavior like scrolling or mouse movement if needed.
Here’s one quick tweak that helps:
python
CopyEdit
options.add_argument(“user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/114.0”)
It won’t fool every site, but it’s better than rolling with the default Selenium signature.
Why Headless Browsers Make Scraping Smarter, Not Harder
If you’ve ever tried scraping a modern website and hit a wall because the content just wouldn’t load with plain HTML parsing, now you know why a headless browser can be a game-changer.
It’s not just about getting the data, it’s about getting it the right way. With a Python headless browser setup using Selenium, you can interact with sites like a real user. You can wait for content to load, click buttons, handle JavaScript, and scrape exactly what you see on the page. No missing data. No messy workarounds.
And while running a headless browser for scraping does require more setup than basic tools like requests or BeautifulSoup, it pays off in flexibility. Especially for dynamic, JavaScript-heavy websites—think e-commerce stores, real estate listings, stock data feeds, this is where headless automation really earns its keep.
That said, scraping responsibly is just as important as scraping effectively. The best scripts are built to respect site policies, avoid unnecessary load, and handle errors without falling apart.
At PromptCloud, we’ve worked with hundreds of businesses that needed scalable, smart scraping solutions, ones that go beyond basic HTML crawling. If your use case demands reliable extraction from dynamic websites, a headless browser-based approach might be exactly what you need.
Ready to scale up your scraping efforts without the hassle of writing and maintaining the infrastructure yourself? Schedule a demo with us. We’ll help you extract web data at scale: ethically, reliably, and efficiently.















