




**TL;DR**
Earlier, scraping used to mean code, proxies, and a lot of debugging. Now, genAI web scraping tools like ScraperGPT and LangChain scrapers are making a shift from rule-based crawlers to self-generating, zero-code systems. They understand your prompt, infer what to extract, build a pipeline, and even debug themselves when a site changes.
Takeaways:
- GenAI turns human intent into executable scraping logic.
- Prompts can now define what to crawl, extract, and store.
- Models like ScraperGPT and LangChain scrapers bridge NLP and data engineering.
FYI: Within seconds, an AI model interprets the prompt, builds the scraper, handles pagination, and connects it to your preferred data destination. That’s GenAI web scraping: an emerging fusion of language models, workflow automation, and zero-code engineering. Instead of coding logic manually, you guide it with text.
This new approach is powered by frameworks like ScraperGPT and LangChain scrapers, which combine language understanding with structured task execution. They translate plain prompts into full scraping blueprints – selectors, validation logic, and data delivery all stitched together automatically.
This isn’t a distant concept. Enterprises are already using GenAI to:
- Spin up scraping jobs from text prompts or chat interfaces.
- Generate and test extraction logic autonomously.
- Chain multiple steps like extraction, validation, and upload into one workflow.
In this article, we’ll unpack how prompt-driven scraping works, what tools power it, and why it’s the next step in making data pipelines as simple as asking a question.
What Is GenAI Web Scraping and How It Differs from Traditional Methods
Let’s start with the basics. Traditional web scraping has always been a manual sport. GenAI web scraping changes that entire workflow. It removes the line between human instruction and machine execution. The system instantly designs the scraper, chooses the fields, sets the frequency, and even includes a cleanup step before sending data to your dashboard.
That is the power of GenAI. It transforms intent into automation.
Want to see how PromptCloud uses GenAI to design self-building scraping pipelines?
If you're evaluating whether to continue scaling DIY infrastructure or move to govern global feeds, this is the conversation to have.
How It Works Behind the Scenes
At the heart of these systems are large language models combined with task-specific tools. The model reads your text, predicts what type of website you mean, detects patterns in its structure, and then composes a scraping workflow.
A single prompt triggers a series of steps:
- Understanding what kind of data is needed.
- Detecting which parts of the page contain that data.
- Generating the extraction logic automatically.
- Running tests and adjusting the plan until results look clean.
Where traditional scraping is about coding instructions, GenAI scraping is about teaching intent.
Why This Shift Matters
The biggest difference lies in ownership of complexity. In the old model, every developer carried that weight. In the GenAI model, the AI absorbs it.
- You no longer manage selectors or pagination.
- The model generates code that adapts to structure changes.
- Human teams spend time on data strategy, not on maintenance.
For enterprises dealing with hundreds of sources, that shift means less friction, faster deployment, and lower overhead. GenAI web scraping also democratizes access. A marketing analyst or product manager can now build and launch a data workflow simply by describing what they want. Technical fluency stops being a requirement.
This is not the end of engineering; it is the start of creative control.
How GenAI Builds a Scraper [Step by Step]
If you think of GenAI web scraping as magic, it helps to see what is really happening under the hood. A single prompt travels through several distinct phases before you ever see a dataset appear.
The Complete Process
- Prompt Interpretation: The model reads the user input, breaks it into intent phrases, and checks what kind of website it is dealing with.
- Layout Understanding: Using a combination of training data and live inspection, the system detects where meaningful information lives on the page.
- Workflow Generation: It translates that understanding into a scraping plan, defining selectors, pagination logic, and delivery formats automatically.
- Validation and Adjustment: The AI tests a sample run, cleans errors, and adjusts extraction rules until it returns a consistent structure.
- Pipeline Assembly: The system finally connects extraction, validation, and delivery into a single continuous workflow.
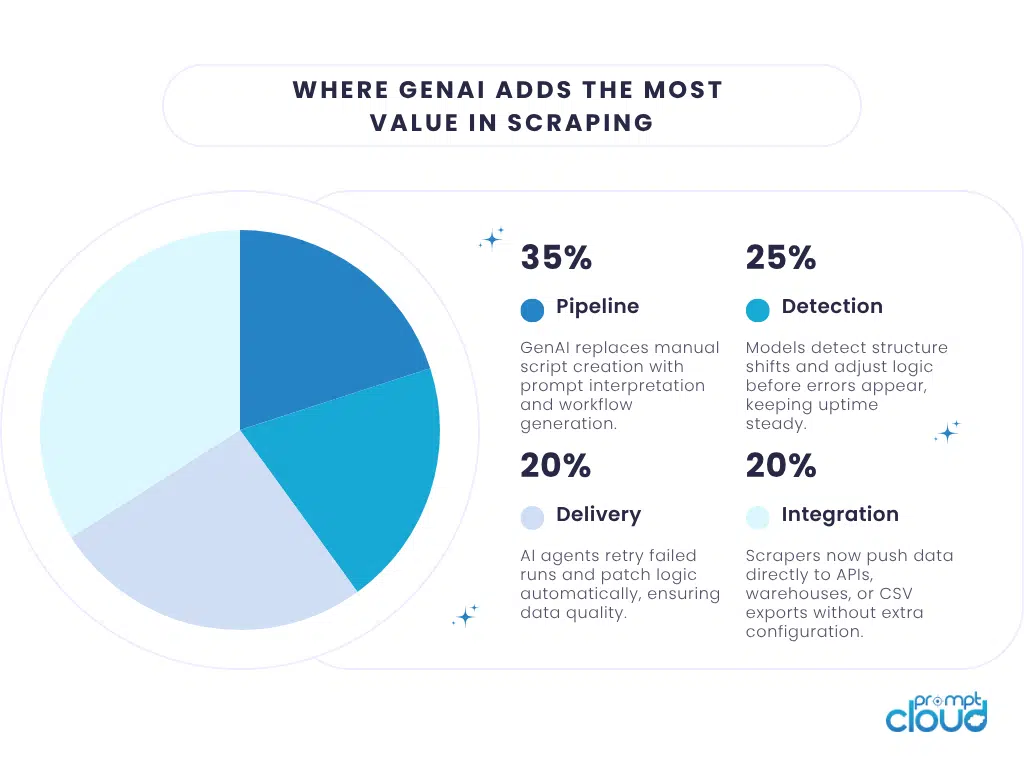
Figure 1: Distribution of automation value across different stages of a GenAI-powered scraping workflow.
Here’s how this flow compares to a traditional approach:
| Stage | Traditional Scraping | GenAI Web Scraping |
| Setup | Developer defines rules manually | AI understands intent and designs workflow |
| Coding | Requires writing and maintaining scripts | Generates dynamic extraction logic automatically |
| Testing | Manual debugging for every break | Built-in validation and self-correction |
| Scaling | Needs engineering resources | Launches multiple scrapers through prompts |
| Delivery | Requires integration work | Auto-publishes to preferred format or API |
Why Does It Feel Effortless?
GenAI works because it blends language comprehension with procedural logic. When you say “extract prices,” it knows what “price” looks like across different domains. When you mention “daily refresh,” it adds scheduling automatically.
It is not magic; it is machine pattern recognition meeting linguistic understanding.
The Tools Behind It – ScraperGPT, LangChain, and Zero-Code Builders
The GenAI scraping ecosystem has exploded in the past year. What began as a few experimental scripts has grown into full frameworks that build, test, and manage scrapers with minimal human input.
The key players here are ScraperGPT, LangChain scrapers, and a new wave of zero-code builders. Each brings its own approach to turning language into structured action.
ScraperGPT – The Autonomous Builder
ScraperGPT is designed to translate text prompts directly into working scrapers. It handles everything from layout detection to output formatting. Give it a sentence like “Collect the top news headlines from Reuters and export them in JSON,” and it generates the script, the schema, and the output configuration in seconds.
ScraperGPT also includes self-repair logic. When it detects missing or malformed fields, it revises its own instructions and relaunches the crawl. That means fewer failed runs and more consistent datasets.
The concept feels similar to how we treat structured extraction across different layers of the web, where intelligent agents decide what content is accessible, indexable, or restricted. You can see this layered logic applied in surface web, deep web, and dark web crawling, where automation defines the boundary between what can and cannot be scraped responsibly.
LangChain Scrapers – The Modular Thinkers
LangChain scrapers bring composability. Instead of one large model handling everything, they use smaller chained models that specialize in tasks like discovery, extraction, validation, or summarization. The “chain” in LangChain comes from the idea of connecting reasoning modules.
This approach lets teams build scrapers that evolve as they run. Each module can retrain or replace itself without rewriting the entire system. The result is flexibility and stability; two qualities that traditional scraping architectures rarely deliver at the same time.
Zero-Code Builders – Scraping for Everyone
Zero-code builders are where the accessibility revolution really happens. These tools give non-technical users drag-and-drop control over scraping tasks. But under the hood, they still rely on GenAI logic. When you describe your goal or upload a prompt, the system generates extraction logic automatically.
This mirrors what PromptCloud users already experience through managed workflows. The concept of automated delivery and format selection parallels what is described in the export website to CSV, where clean, structured data arrives ready for integration without engineering overhead.
Together, these tools create a feedback loop: prompts define logic, models execute it, and validation layers refine it. The system learns and improves, turning a single instruction into a production-grade workflow.
Building a Prompt that Builds a Scraper – Best Practices and Real Examples
Every GenAI scraper begins with one thing: your prompt. The clearer your prompt, the smarter your pipeline.
Best Practices for Writing Effective Scraping Prompts
- Start with an outcome, not a method – Instead of saying, “Extract all product divs,” write “Collect product names, prices, and availability from all pages under this category.” The model then focuses on what matters, not on your technical assumptions.
- Add context where possible – Include details about frequency, format, and filters. Example: “Gather restaurant ratings from Zomato for Delhi, export to JSON weekly, and ignore ads.”
- Specify your data type clearly – Use words like article, review, listing, or product to help the model identify structure.
- Use stepwise logic if the task is complex – Example: “First, identify all laptop categories on BestBuy. Then extract product details under each category and merge duplicates by SKU.”
- Always validate once before scaling – Test your prompt on one or two pages before applying it site-wide. That feedback helps the AI adjust extraction rules early.
What a Good Prompt Looks Like
| Weak Prompt | Improved Prompt |
| Scrape this website for data. | Scrape all new articles from TechCrunch in the AI category, collect title, author, and date, and export to CSV daily. |
| Get product details. | Collect all smartphone listings from Amazon India with name, price, and delivery estimate. Save in JSON format. |
| Extract reviews. | Extract reviews for Nike Air Zoom shoes from the official site and summarize top positive and negative themes. |
You can see how the second column gives the model structure and boundaries. The clearer your language, the cleaner your output.
How Enterprises Apply Prompt Patterns
Enterprises now maintain prompt libraries that work like code repositories. Each entry represents a reusable template for product tracking, news aggregation, sentiment extraction, or pricing analysis.This pattern is already transforming how teams collect data in sectors like finance and eCommerce. For instance, financial analysts use prompt templates that monitor earnings announcements, detect tone changes, and flag anomalies automatically. That is similar to the logic behind web scraping for finance in 2025, where structured automation ensures every event-driven dataset stays fresh and complete.
A Quick Real Example
Prompt: “Scrape Google Trends for the top five search queries in the technology category for the past month and return a CSV sorted by search volume.” The GenAI system does the following:
- Locates the right endpoint in Google Trends
- Extracts and parses the trending query data
- Cleans and validates the output
- Delivers a downloadable file ready for analysis
That is not theoretical. It mirrors the workflow explained in Google Trends Scraper 2025, where automated data collection blends seamlessly with prompt-driven execution.
Benefits and Limitations of Prompt-Driven Scraping
The Benefits
You feel the lift right away. Fewer moving parts to wrangle. More time back.
- Speed and scale: One clear prompt can replace hours of hand coding. You can spin up several scrapers in parallel and tweak them by changing a few words. Teams often keep a small library of proven prompts so a new feed becomes a quick clone and edit rather than a new build. That habit compounds speed across quarters.
- Access for non developers: Marketers, researchers, and analysts can set up real data flows without writing code. Iteration speeds up and engineering queues shrink. A simple chat style interface lowers the barrier even further, which means more experiments, more learning, and fewer abandoned ideas.
- Resilience to change: When a page layout shifts, GenAI adjusts the extraction logic instead of falling over. The scraper learns the new pattern and keeps going. Small breaks that used to trigger on-call fixes now resolve quietly, which keeps refresh schedules on time.
- Smarter recovery: If fields are missing or messy, the model tries again, fills the gaps, or raises a clean alert before the data reaches production. You can pair this with sampling checks, so a tiny slice of each run is reviewed by a human once a week to keep quality high.
- Improvement over time: Each run leaves a memory. The system remembers which structures worked and applies those lessons to the next job. Over months this becomes a real advantage because the platform builds a private playbook for your domains and use cases.
Figure 2: How prompt-based workflows improve speed, flexibility, and accessibility across enterprise scraping operations.
The Limitations
There are still edges. You should know where they are and plan for them.
- Occasional wrong turns: Models can misread a pattern or propose selectors that return nothing. Keep a simple human review step. A small canary run before full execution catches most of these issues with little cost.
- Opaque decisions: Some choices happen inside the model and are hard to trace. Good logging and clear audit trails make debugging possible. Add reason summaries to each job so an analyst can see what the agent believed and why it chose a specific path.
- Compute cost: Large models are not free to run. Use orchestration that calls heavy reasoning only when needed. Budget guards, cooldown windows, and light retrievers keep spend predictable without choking performance.
- Rules of the road: Terms of service, robots rules, and privacy laws still apply. Guardrails and managed collection keep you on the right side of policy. Train your team to recognize sensitive sources and route anything uncertain to a review queue.
- Model drift: Accuracy can slide without care. Schedule refreshes for prompts, validation sets, and model versions to hold quality steady. A monthly health check and a quarterly tune up is often enough for most enterprise workloads.
Comparing Traditional vs GenAI Scraping
| Dimension | Traditional Scraping | GenAI Web Scraping |
| Setup Time | Days or weeks | Minutes |
| Skill Requirement | Developer-heavy | Text-based and accessible |
| Maintenance | Manual and recurring | Automated and adaptive |
| Error Handling | Script debugging | Self-correction with feedback |
| Cost Over Time | High maintenance cost | Higher upfront compute, lower upkeep |
| Transparency | Fully controllable but static | Dynamic, requires audit logging |
Prompt-driven scraping saves enormous time, but it still needs human direction and oversight.
Think of it like driving an autonomous car: you can take your hands off the wheel, but you still need to keep your eyes on the road.
The Future of GenAI Web Scraping – From Tools to Ecosystems
We are only at the starting line of what GenAI can do for data extraction. What began as prompt-based automation is quickly evolving into full ecosystems where AI agents communicate, collaborate, and maintain scraping pipelines without intervention. The next wave will look less like a single tool and more like a coordinated network of agents that learn from each other. Instead of managing hundreds of scrapers individually, you will manage an ecosystem of intelligent scrapers that delegate tasks, share error logs, and retrain themselves based on performance feedback.
What the Future Looks Like
- Multi-Agent Collaboration
Different agents will specialize one for discovery, one for extraction, one for validation, one for summarization. Each will share updates through a unified memory layer. - Cross-Domain Learning
When an agent masters scraping logic for one website, it will apply that knowledge to similar structures across industries. That kind of transfer learning could cut new scraper setup time to seconds. - Integration with RAG and LLM Platforms
Scraped data will feed directly into Retrieval-Augmented Generation systems and enterprise LLMs, powering real-time insights instead of static dashboards. - Natural Language Governance
Compliance and QA processes will become conversational. You will be able to ask, “Which pipelines are using outdated schemas?” and get an instant answer from your AI data assistant.
Why It Matters
The promise of GenAI web scraping is not just faster data collection. It is about turning data operations into adaptive systems that run as smoothly as language itself. In the same way ChatGPT changed how we write, GenAI scraping will change how organizations think about acquiring and maintaining web data.
This movement has already caught global attention in the data engineering community. A recent article from TechCrunch explores how enterprises are adopting generative AI to automate data workflows, connecting web extraction, cleaning, and delivery through language-based orchestration. It is not just innovation for convenience; it is innovation for resilience.
What Comes Next
Soon, prompt-driven scrapers will not just collect information. They will decide when to crawl, which fields to prioritize, and how to enrich results before delivery. This marks a shift from data pipelines as code to data pipelines as conversation. Enterprises that adopt early will spend less time fixing scripts and more time using data to make decisions.
Want to see how PromptCloud uses GenAI to design self-building scraping pipelines?
If you're evaluating whether to continue scaling DIY infrastructure or move to govern global feeds, this is the conversation to have.
FAQs
1. What is GenAI web scraping?
GenAI web scraping uses generative AI models to turn written prompts into full scraping workflows. Instead of coding manually, you describe your goal in plain language, and the AI builds, tests, and runs the scraper automatically.
2. How does prompt-driven scraping differ from traditional scraping?
Traditional scraping requires coding, debugging, and constant maintenance. Prompt-driven scraping replaces that manual setup with language-based automation. The system interprets your intent, generates extraction logic, and self-adjusts when a site changes.
3. What are some real-world use cases for GenAI web scraping?
Businesses use it for price tracking, sentiment monitoring, product discovery, financial signal extraction, and news aggregation. Anywhere structured data changes often, GenAI scraping delivers faster and cleaner results.
4. What tools are most commonly used for GenAI scraping?
Frameworks such as ScraperGPT, LangChain scrapers, and other zero-code builders are leading the space. They combine language understanding with code generation to automate every step from extraction to data delivery.
5. Does GenAI web scraping still require technical oversight?
Yes. While these systems can generate and adapt scrapers on their own, human review is important for validation and compliance. Enterprises usually keep a quality check process to ensure data accuracy and ethical use.
6. Can GenAI scrapers integrate with existing data pipelines?
Absolutely. Most GenAI frameworks export data in structured formats like CSV, JSON, or connect directly to APIs and cloud warehouses. They can fit into your existing ETL, BI, or LLM-based analysis stack with minimal setup.
7. What are the biggest risks with GenAI web scraping?
The main risks are hallucination, overgeneralization, and limited visibility into internal reasoning. Without monitoring, the system might collect irrelevant or inconsistent data. Managed frameworks solve this through validation layers and retraining.
8. What skills do teams need to adopt GenAI scraping?
Teams benefit from prompt-writing, data literacy, and some understanding of APIs or schema structures. The technical barrier is far lower than traditional scraping but still benefits from a strong data strategy mindset.















