



In the era of big data, crawling websites has emerged as an indispensable process for businesses aiming to harness the vast wealth of information available online. By efficiently collecting, processing, and analyzing web data at scale, companies can unlock valuable insights and gain a competitive edge across various industries.
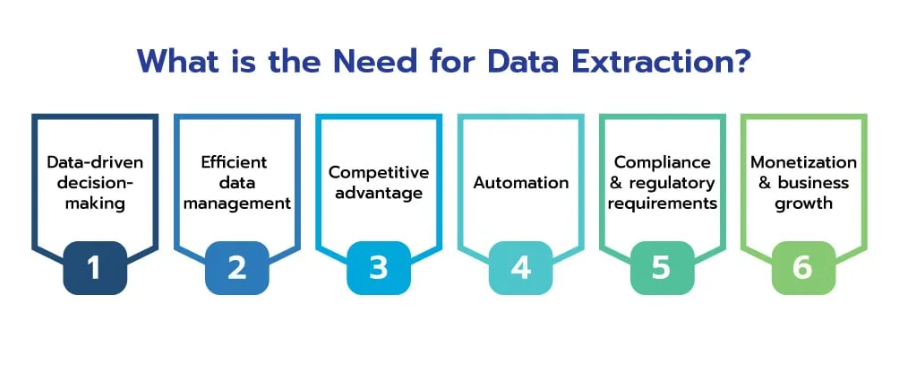
Web data holds immense potential, offering deep insights into market trends, consumer behavior, and competitive landscapes. The ability to efficiently gather and analyze this data can transform raw information into actionable intelligence, driving strategic decision-making and business growth.
Source: scrapehero
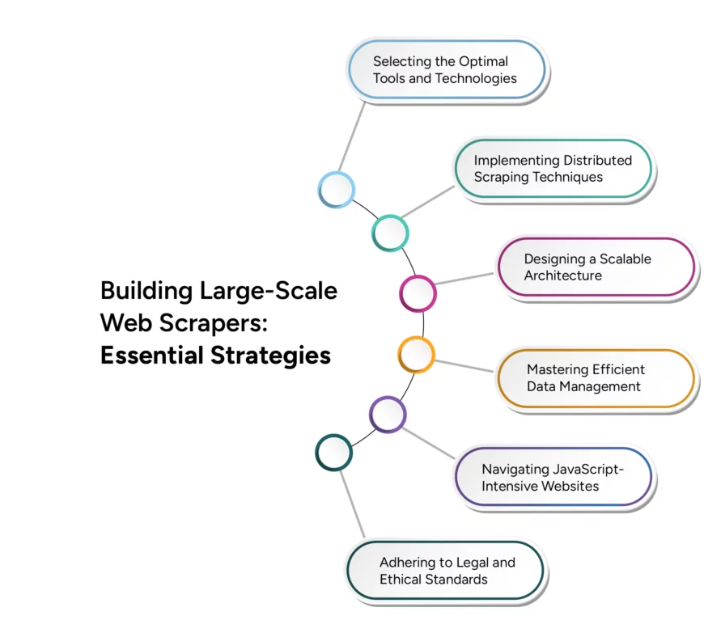
However, transitioning from small-scale web scraping to large-scale web crawling presents significant technical challenges. Effective scaling requires careful consideration of various factors, including infrastructure, data management, and processing efficiency. This article delves into advanced techniques and strategies necessary to overcome these challenges, ensuring that your web crawling operations can grow to meet the demands of big data applications.
Challenges of Crawling Websites for Big Data Applications
Crawling websites for big data applications presents several significant challenges that businesses must address to effectively harness the power of vast online information. Understanding and overcoming these challenges is crucial for building a robust and scalable web crawling infrastructure.
One of the primary challenges is the sheer volume and variety of data on the web, which continues to grow exponentially. Additionally, the diversity of data types, from text and images to videos and dynamic content adds complexity to the crawling websites process. Modern websites often use dynamic content generated by JavaScript and AJAX, making it difficult for
traditional crawlers to capture all relevant information. Moreover, websites may impose rate limits or block IP addresses to prevent excessive crawling, which can disrupt data collection efforts.
Ensuring the Data accuracy and consistency of the data collected from various sources can be difficult, especially when dealing with large datasets. Scaling web crawling operations to handle increasing data loads without compromising performance is a major technical challenge. Furthermore, adhering to legal and ethical guidelines for crawling websites is crucial to avoid potential legal issues and maintain a good reputation. Efficiently managing computing resources to balance crawling speed and cost-effectiveness is also critical.
Techniques for Efficient Data Extraction
Implementing advanced data extraction techniques ensures that the data collected is relevant, accurate, and ready for analysis. Here are some key techniques for enhancing the efficiency of data extraction:
- Parallel Processing: Utilize parallel processing to distribute data extraction tasks across multiple threads or machines, increasing the speed of data extraction by handling multiple requests simultaneously and reducing the overall time required to collect data.
- Incremental Crawling: Implement incremental crawling to update only the parts of the dataset that have changed since the last crawl, reducing the amount of data processed and the load on web servers, making the crawling process more efficient and less resource-intensive.
- Headless Browsers: Use headless browsers like Puppeteer or Selenium for rendering and interacting with dynamic web content, enabling accurate extraction of data from websites that rely heavily on JavaScript and AJAX, ensuring comprehensive data collection.
- Content Prioritization: Prioritize content based on relevance and importance, focusing on high-value data first, ensuring that the most critical data is collected promptly and optimizing resource utilization and data relevance.
- URL Scheduling and Politeness Policies: Implement smart URL scheduling and politeness policies to manage the frequency of requests to a single server, preventing overloading web servers and reducing the risk of IP blocking, ensuring sustained access to data sources.
- Data Deduplication: Employ data deduplication techniques to eliminate duplicate entries during the extraction process, enhancing data quality and reducing storage requirements by ensuring that only unique data is stored and processed.
Real-Time Web Crawling Solutions
Source: Medium
In today’s fast-paced digital landscape, the ability to extract and process data in real time is
crucial for businesses seeking to maintain a competitive edge. Real-time web crawling solutions enable continuous and instantaneous data collection, allowing for immediate analysis and action. Implementing an event-driven architecture can significantly enhance real-time capabilities, where crawlers are triggered by specific events or changes on the web, ensuring that data is collected as soon as it becomes available.
Scalability in Multi-Language Web Crawling
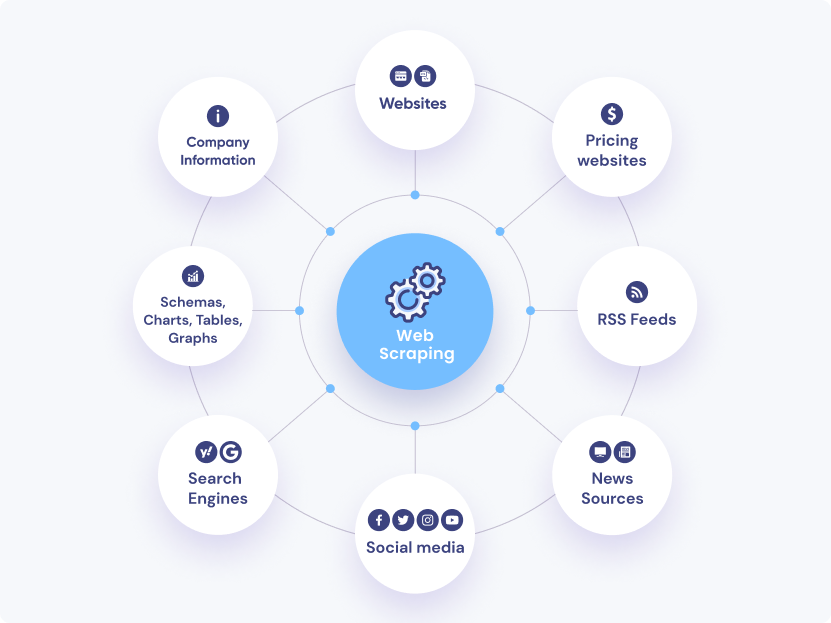
The global nature of the internet necessitates the ability to crawl and process data in multiple languages, presenting unique challenges that require specialized solutions. Crawling websites operations to handle multilingual content involves implementing language detection algorithms to automatically identify the language of web pages and ensure the appropriate language-specific processing techniques are applied. Using parsing libraries and frameworks that support multiple languages, such as BeautifulSoup, provides robust tools for extracting content from diverse web pages. Integrating scalable translation services like Google Cloud Translation into the data processing pipeline allows for real-time translation of content, enabling seamless analysis across different languages.
Conclusion
Source: groupbwt
As we move further into the digital age, the importance of crawling websites for big data applications continues to grow. The future of web crawling lies in its ability to scale efficiently, adapt to dynamic web environments, and provide real-time insights. Advances in artificial intelligence and machine learning will play a pivotal role in enhancing the capabilities of web crawlers, making them smarter and more efficient in processing vast amounts of data.
The integration of distributed systems and cloud-based infrastructures will further improve scalability, allowing businesses to handle increasingly larger datasets with ease. As web crawling technologies continue to evolve, they will not only enhance data collection processes but also ensure that businesses can maintain a competitive edge in an ever-changing digital landscape.
Embracing these advancements is not just an option but a necessity for organizations aiming to leverage big data effectively. The future of web crawling promises to be a transformative force, driving innovation and providing the tools needed to unlock the full potential of the vast web data ecosystem.
Take your big data applications to the next level with PromptCloud’s customizable web scraping services with seamless integration and scalability. Contact us today to harness the power of advanced web crawling for your business.















