Building a Data-Driven Culture: Integrating Web Scraping into Business Intelligence
Data from the US Census Bureau shows a record-breaking 5,481,437 new businesses were started in 2023. With competition intensifying in
Read more






PromptCloud offers managed data scraping services. From setting up crawlers to data normalisation, we ensure that the harvested data meets your quality standards.

We work with strong SLAs, to provide prompt support and deliver more than we promise. Our data wizards are obsessed about making clients happy!

Irrespective of the complexity of data requirement, our web crawlers are flexible enough to deliver customized data feeds by making use the best web scraping techniques.
Our high-performance machines and the optimized scraping techniques make sure that the scrapes run smoothly to deliver data as per the timeline.

Need customized external data feed running into millions? We’ve got you covered, with our strong web scraping infrastructure and technical expertise, we help you scale with your data.

Our sophisticated monitoring system keeps track of the slightest change in the site structure and alerts the engineering team so that swift updates can be made.

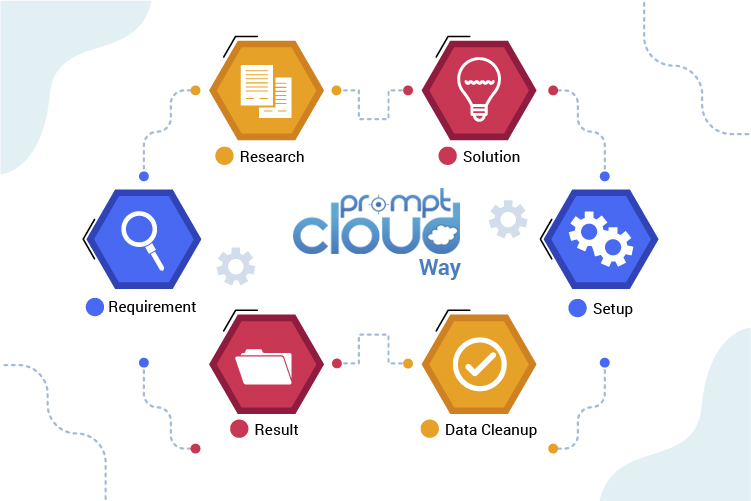
To start your data mining project, provide information to us on the sites to be crawled, fields to be extracted and desired frequency of these crawls.

According to your specified requirement, we’ll provide the sample data by setting up the web crawler. You need to validate the data and the data fields present in the sample file.

After you consent, we’ll finalize the crawler setup to proceed with the web scraping service project and upload the data.

Finally, you’ll download the data either directly from CrawlBoard or via our API in XML, JSON, or CSV format. Data can also be uploaded to your Amazon S3, Dropbox, Google Drive, and FTP accounts.
We meet all your data mining requirements.
I have used PromptCloud for my business, and was very happy with the experience. PromptCloud’s customer support was excellent and they worked with me to ensure the data harvested was exactly what I needed.

Promptcloud has provided us with an excellent data quality for many years. They are our first web scraping solution when it comes to getting accessible data from the internet. I highly recommend them, they are indeed the best web crawlers.

PromptCloud provides an excellent data quality service at highly competitive pricing. Their web scraping service quality allowed our engineers to concentrate on the projects closer to the core of the business, with the security of knowing PromptCloud is servicing these other projects with the same level of rigour and precision we’d expect from our core team.


















News From the world Of data mining and how different industries can use solutions from web scraping.

Data from the US Census Bureau shows a record-breaking 5,481,437 new businesses were started in 2023. With competition intensifying in
Read more
In an era where data is the new currency, enterprises are increasingly turning to sophisticated data extraction solutions to drive
Read more









