



If you’re looking to extract data from a website, you’ll see that the web is filled with tutorials on how to do this using a DIY tool or by writing a web crawler program yourself. These options might suit the needs of some tech savvy users who are either looking to learn web scraping or are interested in extracting small volumes of data from a few websites. However, if your requirement demands recurring, large scale web data extraction, you’re better off with a fully managed solution.

Not all custom solutions involve sending emails back and forth to get started. CrawlBoard, our requirement gathering dashboard is a one-stop solution that’s a mix of a tool, service and a framework. Let’s see how to extract data from a website using CrawlBoard.
Getting started
Starting a project on Crawlboard is easy. After signing up, it only takes a few clicks to specify details of your data requirements by adding the target sites, data fields and crawling frequency. Once your project is up and running after the feasibility study, you will get all the updates on data upload notifications in real time.
How to crawl a website using CrawlBoard: Step-by-step guide
Step 1
Go to CrawlBoard and enter your details like first name, last name, company email and job role, and finally hit sign up.
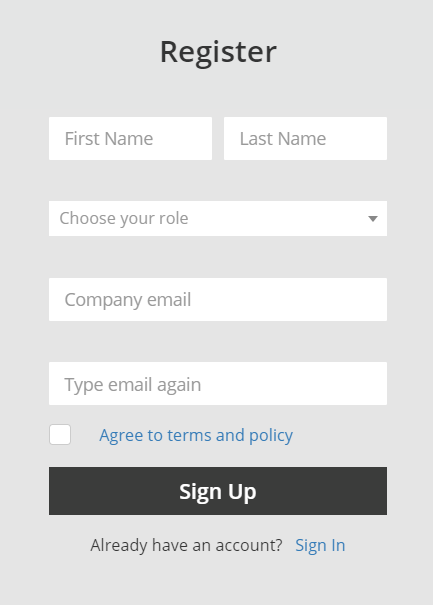
Once done, activate your account by clicking on the verification link sent to your registered email address.
Step 2
To add a site, click on the Add link next to your email address on the top right corner of the dashboard and select Site.
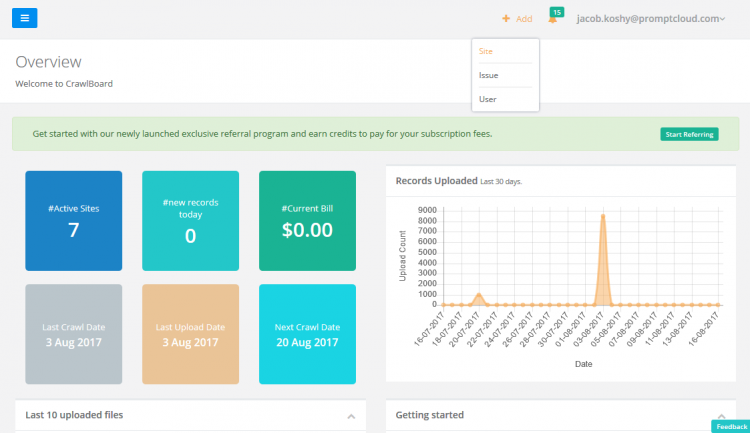
Before you can start adding sites, you first have to create a Sitegroup. To create a Sitegroup, click on the Create a new sitegroup link to the right side of Sitegroup selection box.
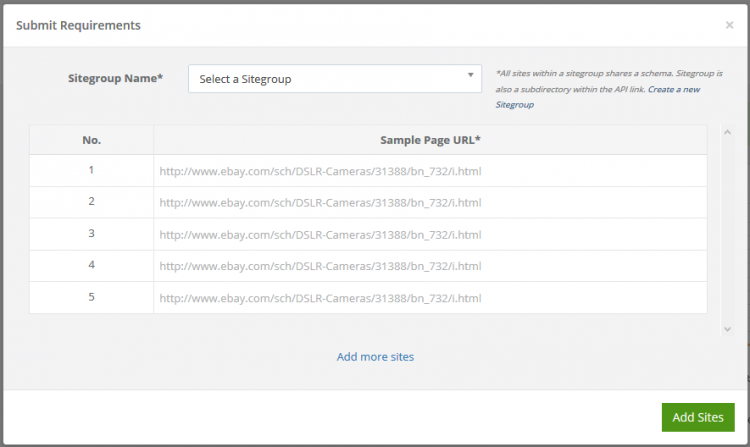
Step 3
In the sitegroup creation window, enter a unique name for your Sitegroup. All the sites within a Sitegroup will have the same schema (structure).
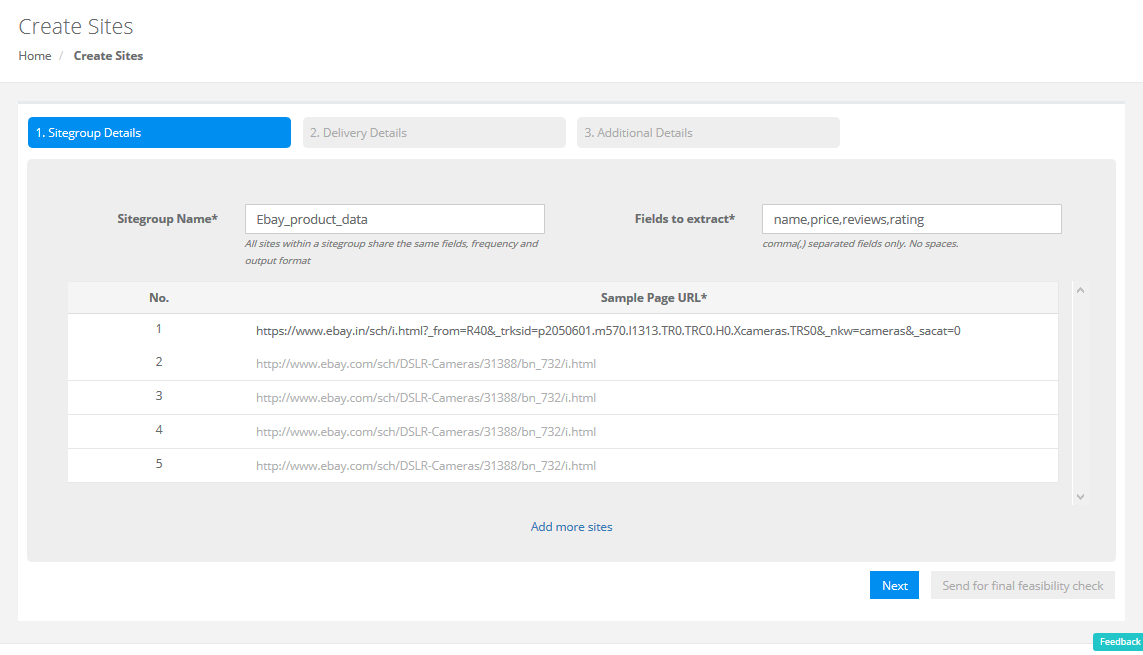
For example, if you want to crawl reviews for products on some ecommerce portals, you will have to create a sitegroup for that and if you’re scraping job listings from a job board, you will be creating another sitegroup for that. You can include pages that follow a very similar structure under a single sitegroup.
Next, enter the data points that you are looking to extract in the ‘Fields to extract’ box. Separate the data points using commas.
In the sample page URL box, enter at least one page URL where the data points that you need are available and click Next.
Step 4
You can choose your preferred frequency of crawls, data delivery format and delivery method here. The options for frequency are daily, weekly, monthly and custom. You can opt to get the data in CSV, JSON or XML via different delivery methods like REST API, Amazon S3, Dropbox and FTP.
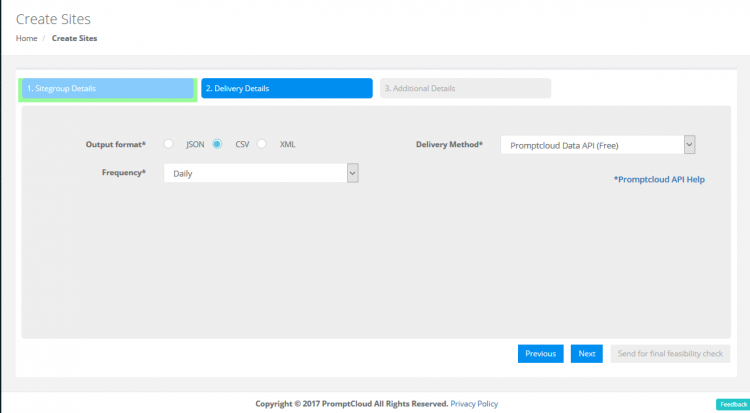
If you opt to get the data via a third party service like Dropbox, the necessary credentials will also have to be shared with us. Once done, click Next.
Step 5
In the next screen, you can let us know of any additional information by entering it in the ‘Further description’ box.
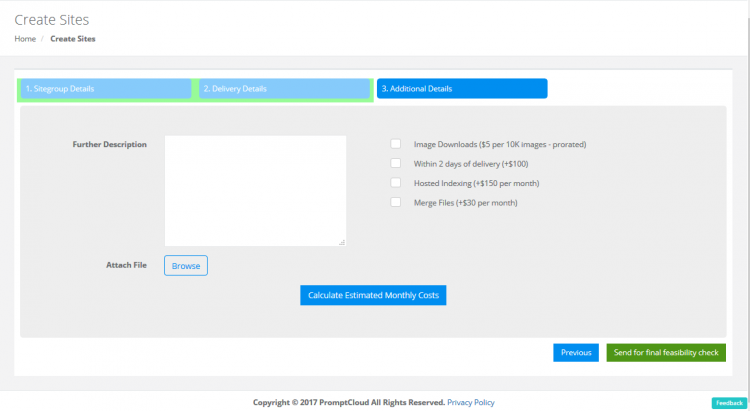
You can also opt for our value added services like ‘Expedited delivery’, ‘Image downloads’, ‘File merging’ and ‘Hosted indexing’.
Step 6
Finally, click on the Send for feasibility check and you’ve added your first website to crawl using CrawlBoard.
You will soon receive an email once the feasibility of your web scraping project is established by our team, post which you can make the payment and start getting your data feeds via the delivery method chosen by you.
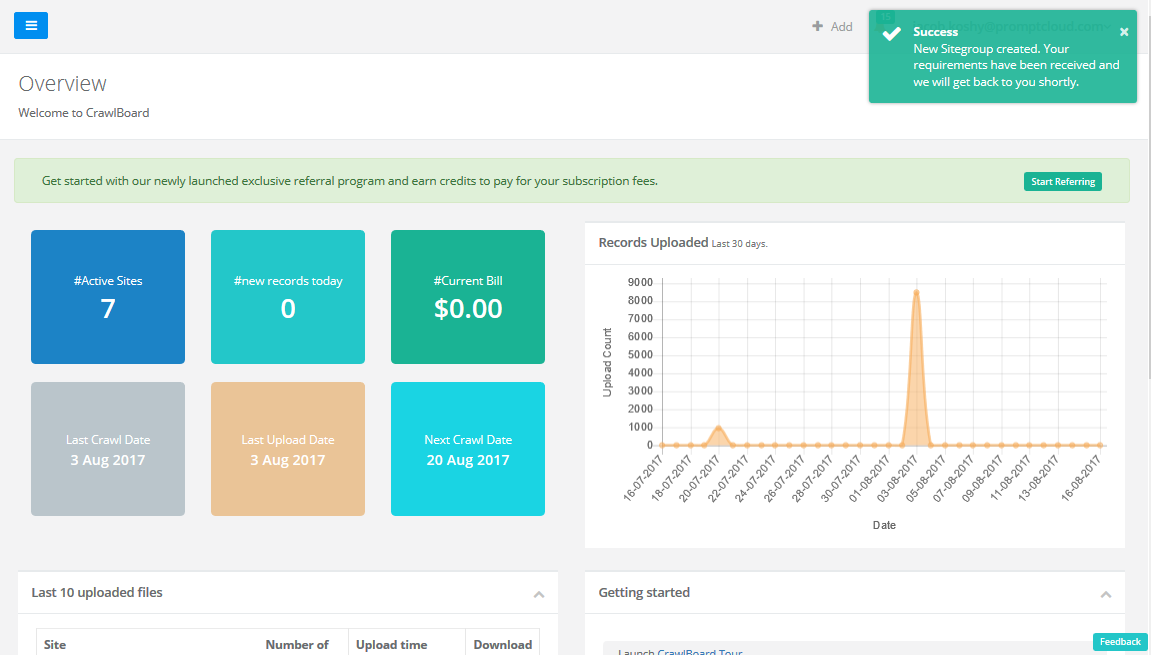
That’s how easy it is to start scraping a website using CrawlBoard. All the technically complex procedures involved in web scraping happens behind the stage while you consume clean and ready-to-use data feeds.
What CrawlBoard is not
Many new users of CrawlBoard often get confused by the different aspects of it that signal a product, service and framework. To clear the air, let’s explain what CrawlBoard is in its core.
CrawlBoard is a blend of different types of offerings as we mentioned earlier. Being the client-facing dashboard of our web crawling service, it’s only natural that it appears to be a tool to the new users. But, users cannot use this as a DIY tool to crawl data on their own — it can only be used to manage the data acquisition project and consume data delivered via our REST API.
The requirement gathering part doesn’t involve any communication with our team and as it’s completely doable on CrawlBoard. Once we receive the requirements, the feasibility is established and the payment can be made through CrawlBoard again. Post this, it acts as a reporting tool for the crawls running on your account, data download portal while the service aspect is being taken care of by our team to ensure only the best quality data gets to you.















