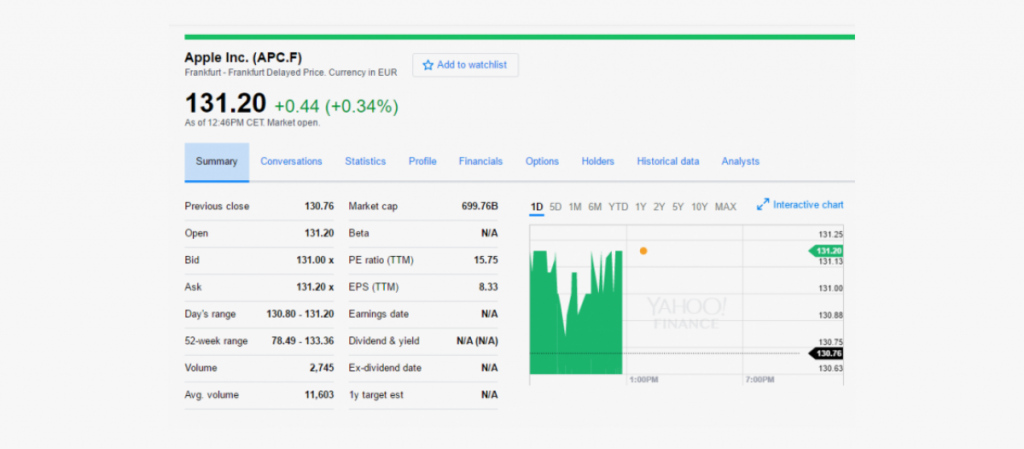
If you are looking to crawl financial data of thousands of companies across the world, there is no question of doing it manually or with a simple DIY tool. Analysts, Portfolio managers, and Traders working in the financial industry are spending huge amounts of money to gain access to data that could potentially move the market. Getting hold of financial data doesn’t have to be so expensive and time consuming. With PromptCloud’s
live crawling services, scraping financial data from publicly available sources on the web is fast, efficient, and easy. Here are some of the use cases that we have encountered from our clients’ requests to crawl financial data.