




**TL;DR**
Most teams talk about AI but overlook the one ingredient that determines whether models perform well or fall apart. AI-ready data is not just clean data. It is structured, validated, consistent, and governed so models can rely on it without drifting, breaking, or learning the wrong patterns.
An Introduction to AI Readiness
Models do not perform well or poorly on their own. They perform well or poorly because of the data that feeds them. And that is where most teams struggle. Raw data looks useful when you first collect it, but the moment you try training a model with it, the cracks show up everywhere.
AI-ready data solves that problem. It gives your model a stable set of inputs that keep their shape, meaning, and quality over time. It is the difference between feeding your AI whatever comes out of a scraper and feeding it data that follows a structure you can trust. AI-ready data stays consistent even when websites change. It carries the right labels and context. It passes validation, follows governance rules, and reflects a balanced view of the environment you are modeling.
This article breaks down what actually makes data AI-ready and why it matters more than teams realize.
Many organizations begin web scraping with internal scripts, but maintaining crawler infrastructure, handling anti-bot protections, and monitoring data quality quickly becomes a full-time operational task.
What AI-Ready Data Really Means
Most teams assume AI-ready data simply means “clean data.” It doesn’t. AI-ready data is data that stays stable even when sources shift, categories expand, formats change, or new inputs enter the pipeline. It holds its structure, meaning, and quality over time, which gives models something predictable to learn from.
Here are the qualities that define true ai ready data:
- The data follows a stable schema, so field names, types, and formats do not jump around between sources.
- Each record comes with useful labels or hints, giving the model enough context to know what it is looking at.
- Quality checks catch gaps, broken values, and contradictions before the data is allowed into training.
Models trained on this kind of dataset perform with stability instead of luck. They adapt better, drift less, and behave more predictably across new scenarios. That is what AI-ready data really means.
Why Is Most Raw Data Not AI-Ready?
Poor raw data is why teams experience unpredictable accuracy, unstable retraining cycles, and sudden performance drops. The issue isn’t the model. It’s the data underneath it.
Most raw datasets fail because they lack the basics that AI depends on. Here are the reasons raw data is rarely ai ready data:
- Hidden duplicates distort patterns, causing the model to overfit or learn false signals.
- Bias sneaks in from overrepresented sources, skewing predictions toward one segment of the dataset.
- There is no consistent labeling, which leaves the model guessing what the data represents.
- No lineage or metadata exists, making the dataset impossible to trace or audit.
- Data freshness is inconsistent, so the model learns from outdated or irrelevant patterns.
That’s why teams that rush straight from raw inputs to training often experience unstable, unpredictable results. AI-ready data removes that fragility by giving the model the stable foundation it needs.
The Core Qualities That Make Data AI-Ready
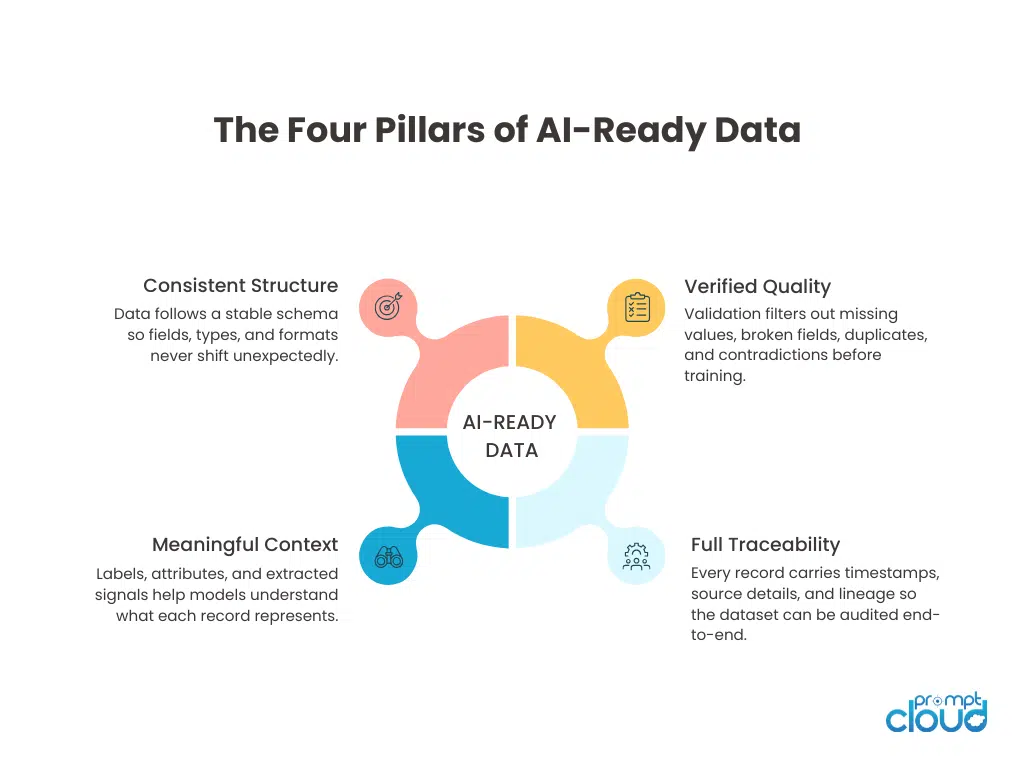
AI-ready data isn’t created by accident. It is the result of a deliberate process that shapes raw inputs into structured, consistent, trustworthy datasets. These qualities are what separate “data that works sometimes” from data that powers accurate, stable, repeatable AI systems. When these qualities show up together, the model behaves predictably. When even one is missing, the entire pipeline becomes unstable.
Below are the attributes that define truly ai-grade data.
1. A Clear and Predictable Structure
AI-ready data follows a schema that remains stable across sources and time.A model cannot form patterns when the same field changes its type, location, or format every week.
2. High Quality Values That Pass Validation
Validation rules filter out broken records so the dataset holds its quality from day one. This is the foundation of data quality for AI and directly affects training stability.
3. Labels and Context the Model Can Understand
AI models learn faster when data carries meaning, not just structure. Labeling, annotation, and enrichment add the contextual layer that transforms raw facts into usable signals.
4. Balanced Representation Across Sources
The dataset reflects the landscape, not just the loudest sources. Most raw data skews toward a few dominant sites or segments. This creates models that behave well on some scenarios and fail on others. AI-ready data prevents this by balancing inputs so no single source or category overwhelms the rest. Balanced data reduces bias and improves generalization.
5. Uniform Standards Across All Sources
Consistency outperforms volume. Many teams overcollect instead of standardizing. AI-ready data flips this. It prioritizes uniform structure, formats, and quality standards across every source. Uniform data simplifies feature engineering, strengthens model signals, and dramatically reduces noise.
6. Smooth Compatibility With Downstream AI Workflows
AI-ready data fits naturally into training, validation, and inference pipelines. This means the data is shaped with downstream needs in mind. The model gets predictable fields, clear relationships, and stable distributions. Nothing arrives as a surprise. This alignment is what keeps the entire AI lifecycle efficient.
7. Stability Over Time, Not Just at the Start
AI-ready data remains reliable long after deployment. Models fail when datasets shift in subtle ways. Structured, validated, governed data maintains its standards across months and years. This stability keeps retraining cycles smoother and prevents accuracy from collapsing unexpectedly. When all these qualities work together, data becomes ai-ready instead of “raw and risky.”
How to Transform Raw Data Into AI-Ready Data?

1. Standardize the Structure First
Create a schema that all sources must follow. Raw data arrives in different shapes. Before anything else, you define how fields should look, what types they should use, and how values should be formatted. This step immediately reduces chaos and gives the entire dataset a predictable frame. Structured datasets begin here.
2. Clean and Normalize the Values
Make every field consistent, complete, and usable. Normalization corrects odd formats, trims noise, converts types, and aligns values to a standard. It removes surprises the model shouldn’t have to handle. This is where true data quality for AI starts to appear because inaccuracies are filtered out early.
3. Deduplicate and Consolidate Records
Remove copies and merge near-duplicates.
4. Enrich the Data With Context
Add the labels and attributes the model needs to understand meaning. AI-ready data is not only structured. It is also enriched with metadata, categories, relationships, or extracted attributes. Whether it’s sentiment, product type, skills, or brand hierarchy, this added context helps models learn faster and behave more accurately.
5. Apply Validation Rules to Catch Errors Early
Filter out broken, missing, or contradictory values. Validation ensures the dataset stays clean over time, not just at the beginning. It checks ranges, formats, completeness, and logical relationships across fields. Anything that fails validation gets corrected or quarantined. This step keeps the dataset trustworthy.
6. Track Lineage and Metadata for Every Record
Make every piece of data traceable.Lineage attaches timestamps, source details, and processing history to each record. This makes the pipeline explainable.
7. Balance Sources to Reduce Hidden Bias
Ensure the dataset represents the full landscape.
If one source dominates, the model becomes skewed toward that pattern. Balancing the dataset across sites, categories, regions, or segments reduces bias and creates more generalizable AI behavior. Balanced data is more reliable data.
8. Keep the Dataset Fresh and Updated
Prevent models from learning obsolete patterns.
Fresh data is critical for accuracy in markets that shift quickly. Regular refresh cycles ensure the model reflects current behavior rather than outdated assumptions. This step keeps the model relevant and protects it from decay.
9. Govern the Entire Pipeline
Control access, retention, and updates with clear rules.
10. Monitor Drift and Adjust Continuously
Watch for slow, subtle changes that impact the model. Even with strict controls, patterns shift over time. Monitoring detects structural drift, distribution changes, or declines in quality before they affect training or inference. This final step keeps ai ready data stable long after deployment.
AI-Ready Data Examples (Real-World Scenarios)
AI-ready data becomes easier to understand when you see how it behaves in practical situations. Raw inputs look chaotic and unpredictable. AI-ready inputs look stable, structured, and meaningful. The examples below show the difference clearly. Each scenario highlights how structure, validation, and governance change the outcome for models that depend on reliable datasets.
These examples also help teams explain ai ready data to non-technical stakeholders who may not see the impact directly but feel it in model performance.
Scenario 1: Product Data From Multiple Retail Sites
When product data comes from different e-commerce sites, raw inputs rarely match. Names differ, formats shift, and values appear in unpredictable patterns. AI-ready data resolves this by aligning everything to one schema.
Table 1: Raw vs AI-Ready Product Data
| Attribute | Raw Data Example | AI-Ready Data Example |
| Product Name | “Nike Running Shoe Mens Blue” | “Nike Air Zoom Pegasus 40” |
| Price | “$149.99”, “149”, “149 USD” | 149.99 |
| Category | “MenSports”, “Men Running”, “Mens Shoes” | “men_running_shoes” |
| Availability | “In stock”, “1”, “TRUE” | true (boolean) |
| Timestamp | Missing | “2025-11-14 10:32:00” |
Why this matters: Structured datasets help the model recognize true patterns instead of fighting against inconsistent formats. Product matching, price forecasting, and search ranking all improve instantly.
Scenario 2: Customer Review Data for Sentiment Models
Review data is messy. See the table below.
Table 2: Raw vs AI-Ready Review Data
| Field | Raw Review | AI-Ready Review Output |
| Text | “Took forever to arrive but the product’s fine I guess.” | Cleaned text + metadata |
| Sentiment | None | Sentiment: Mixed |
| Key Themes | None | Themes: Delivery Delay, Product Quality |
| Star Rating | “3*” or missing | 3 (normalized integer) |
| Entity Tags | None | Entities: Delivery, Product |
When you see these examples side by side, the difference becomes obvious. Raw data is unpredictable. AI-ready data is dependable. It is the difference between training models on chaos and training them on clarity.
How AI-Ready Data Improves Model Accuracy
Below are the core ways ai ready data strengthens real-world model performance.
1. It reduces noise so the model learns real patterns
Raw data forces the model to waste capacity on errors, missing fields, and contradictory formats. AI-ready data removes that noise, which allows the model to identify real relationships instead of guessing around inconsistencies.
2. It gives the model consistent inputs across training cycles
When the dataset keeps its structure and meaning over time, the model can retrain without collapsing. Accuracy becomes repeatable instead of volatile because the inputs remain predictable.
3. It improves feature quality through labeling and enrichment
Models understand meaning only when the dataset carries meaning. Labels, attributes, extracted features, and metadata sharpen the model’s understanding of what each record represents. Better features lead directly to better predictions.
4. It reduces hidden bias and improves generalization
Balanced datasets ensure that no single source dominates. Models trained on balanced inputs perform more reliably across new markets, new conditions, and new data sources.
5. It prevents drift before it harms accuracy
Drift doesn’t break accuracy all at once. It chips away slowly. AI-ready data includes continuous monitoring, which catches early changes in distribution, formats, or values before they become accuracy problems.
Raw Data vs AI-Ready Data
| Attribute | Raw Web Data | AI-Ready Data |
| Structure | Structure varies by source and changes unpredictably. The same field may appear in different places or formats, making the dataset unstable for training. | Structure follows a stable schema with fixed field names and types. Inputs look the same across sources, making patterns easier for the model to learn. |
| Context & Meaning | Records often lack labels, categories, or metadata, leaving the model to interpret text and numbers without guidance. | Data includes labels, categories, sentiments, and extracted attributes that give the model clear context for every record. |
| Quality & Validation | Missing fields, inconsistent formats, and hidden duplicates pass through unnoticed, weakening model accuracy over time. | Validation filters out broken values, incorrect formats, and duplicates, ensuring the dataset stays consistent and reliable. |
| Lineage & Tracking | Source, timestamp, and change history are usually missing, making it hard to debug or audit the pipeline. | Each record carries timestamps, source identifiers, and processing history, giving full traceability end to end. |
| Distribution & Bias | Data often leans heavily toward a few dominant sources, creating biased training inputs. | Inputs are balanced across sources and segments, helping models generalize better and avoid skewed predictions. |
| Governance | Access, updates, and retention happen informally, leading to conflicting versions and uncontrolled changes. | Data sits under defined governance rules with controlled access, documented updates, and consistent quality standards. |
Further Reading From PromptCloud
If you want to explore how AI-ready data connects with trend analysis, financial intelligence, error-proof pipelines, and reputation monitoring, these articles are the best next steps. Each one expands on a real-world use case where clean, structured web data makes the difference between guesswork and confident decision-making.
Here are the recommended resources:
- Learn how to pull market signals at scale with our guide to building a Google Trends scraper.
- Understand how structured web data powers investment research in this detailed piece on web scraping for finance.
- Strengthen your pipeline reliability with our breakdown of how to fix common web scraping errors.
- See how brands protect reputation and customer trust using web data in this guide to online reputation monitoring with scraping.
For a broader industry framework on preparing datasets for AI workloads, you can explore Google Cloud’s guide to data readiness. It outlines the foundational principles behind enterprise-grade data maturity.
Conclusion
AI systems succeed or fail long before the model ever trains. The real work happens in the dataset underneath everything. When data is raw, inconsistent, or unlabeled, the model struggles to form reliable patterns. But when data is structured, validated, enriched, and governed, the model learns from a stable foundation. Accuracy becomes predictable instead of fragile.
AI-ready data is not a luxury or a long-term aspiration. It is the standard that modern AI requires. It reduces drift, improves generalization, stabilizes retraining cycles, and gives teams confidence in the patterns their systems use to make decisions. More importantly, it turns web data into something you can trust rather than something you constantly need to fix.
Once a team commits to AI-ready data, everything else in the pipeline becomes easier. Models improve faster. Maintenance drops. Insights become clearer. And AI stops feeling like a gamble and starts behaving like a dependable part of the business.
Many organizations begin web scraping with internal scripts, but maintaining crawler infrastructure, handling anti-bot protections, and monitoring data quality quickly becomes a full-time operational task.
FAQs
1. Does AI-ready data matter even for small or early-stage AI projects?
Yes. Small models are even more sensitive to inconsistent datasets. AI-ready data gives them clarity and stability, which improves accuracy from the very first training cycle.
2. How quickly can accuracy improve once the data becomes AI-ready?
Improvements can show up immediately. Once noise, duplicates, and inconsistencies are removed, the model begins learning from true patterns instead of distorted ones.
3. Is AI-ready data different from “clean data”?
Clean data removes errors. AI-ready data removes errors, adds structure, adds context, enforces governance, and stays consistent over time. It is a much higher standard.
4. Can AI-ready data help reduce overfitting?
Yes. Balanced inputs, strict deduplication, and consistent structure help prevent the model from memorizing narrow patterns. This leads to better real-world performance.
5. How does lineage improve accuracy?
Lineage reveals where problems start. If accuracy drops, you can trace the inputs back to source-level changes. This makes fixes faster and keeps the model stable during retraining.















