



We’re living in a time when AI is quietly powering many parts of our digital world—often without us even realizing it. From the way Netflix recommends what to watch next to how Google Translate understands multiple languages, intelligent systems are working behind the scenes, learning from data and making predictions.
The rise of advanced machine learning and deep learning models has made this possible. But here’s the thing: no matter how complex or well-designed an AI model is, it’s only as good as the data it’s trained on. And when it comes to training AI, especially deep learning AI, more data isn’t just better—it’s essential.
This is where web scraping steps in. By collecting real-time, diverse, and domain-specific data from the web, scraping gives AI systems the raw material they need to learn more effectively. In this article, we’ll take a close look at the key differences between deep learning vs machine learning, and explore how web scraping helps train smarter, more capable AI models. From understanding unstructured data to scaling deep learning architectures, we’ll dive into what it takes to build AI that learns from the real world.
Deep Learning vs Machine Learning: What’s the Difference?
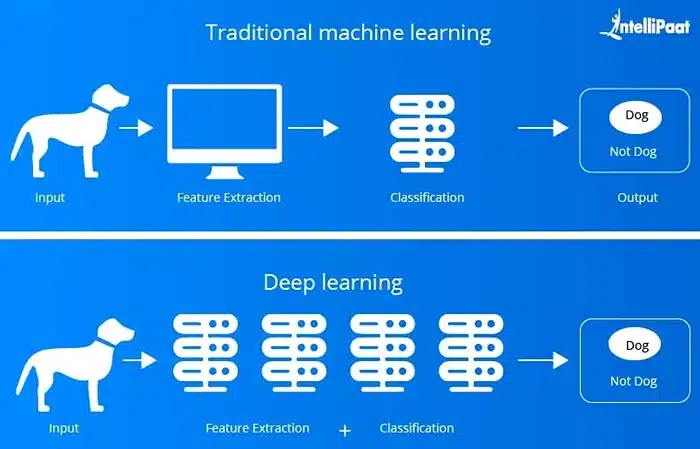
Image Source: intellipaat
Let’s be honest, terms like machine learning and deep learning get thrown around a lot. They often sound interchangeable, but they’re not. At their core, both are about helping computers learn from data. But how they do it and what they can handle differ quite a bit.
Machine learning is where most people start. You give a model some labeled data (like emails marked as spam or not spam), and it learns the patterns. It might also try to group similar data without labels—that’s called unsupervised learning. Think of it like teaching a kid to recognize cats and dogs by showing a few pictures and saying, “this is a cat,” “this is a dog.” Over time, the kid gets better at telling them apart.
Deep learning takes things to a whole new level. Instead of learning simple rules or patterns, it builds something more like a brain—artificial neural networks with layers upon layers. These deep learning models can understand way more complicated data, like photos, videos, or long blocks of text. They don’t just look at surface-level features; they dig deep to understand structure and context.
One of the biggest differences is in how much data they need. Traditional machine learning can get by with less. But deep learning AI is a data-hungry beast. It needs massive, diverse datasets to learn well. The payoff? It can solve problems that machine learning can’t, especially when the data is messy or unstructured.
So if you’re working with clean spreadsheets, ML might do the trick. But if you’re trying to teach a model to understand language, recognize faces, or generate realistic images, deep learning is the tool for the job.
Why AI Needs Tons of Real-World Data to Actually Work
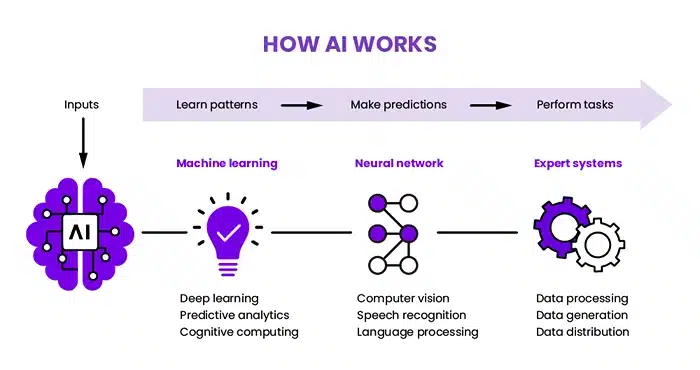
Image Source: Weka
Here’s the thing about AI: it doesn’t just “get smart” on its own. It learns by example. And the more examples you give it, the better it gets. That’s why data is everything. Not just any data, though—the right kind of data, in the right amounts.
Imagine trying to teach someone how to cook, but all they’ve seen are three recipes from 1995. That’s not going to help them whip up a trending dish today. AI models work the same way. If they’re trained on small, outdated, or overly specific datasets, their performance in the real world starts to fall apart.
Sure, there are public datasets out there—some even pretty decent. But most of them are either too generic or already heavily used. They’re not tailored to specific industries or updated often enough to keep pace with how fast things change online.
That’s why large-scale, real-world datasets matter. They help AI models learn from current information, not stale or biased samples. And this is especially true for deep learning models. These systems need thousands, sometimes millions, of examples to start recognizing patterns and making accurate predictions.
That’s where web scraping starts to make a real impact. Instead of waiting for the perfect dataset to magically appear, you can go out and build your own—custom-fit to your domain, and as fresh as the latest blog post or product review.
It’s not just about volume, either. It’s about variety—different writing styles, different image types, different sources. The more diverse your dataset, the more robust your deep learning AI becomes.
How Web Scraping Helps Train Smarter AI Models
If you’ve ever trained a machine learning or deep learning model, you know the drill: garbage in, garbage out. No matter how clever your algorithm is, it can’t do much without good data behind it. That’s why web scraping has become such a valuable tool—it lets you go out and get the data you actually need, straight from the source.
So, what exactly is web scraping? In plain terms, it’s the process of pulling data from websites. You can scrape product descriptions from an e-commerce site, comments from forums, news articles, social media posts, job listings—you name it. If it’s online and publicly accessible, it can probably be scraped.
For AI folks, this opens up a huge opportunity. Most of the interesting stuff online—opinions, conversations, reviews, photos, how-to guides- it’s unstructured. That means it doesn’t live in neat little tables or databases. It lives in messy HTML, scattered text blocks, and sometimes even images or video. But that’s exactly the kind of rich, real-world input that deep learning models thrive on.
Once that data is scraped, you clean it up. You might strip out the HTML, normalize the text, remove duplicates, or crop and resize images. After that, it can be shaped into the kind of format a model can understand—whether that’s a list of tokens for a language model or pixel arrays for a convolutional neural network.
The real benefit here isn’t just volume—it’s relevance. You’re building a dataset that’s made for your specific use case. Want to train a model to analyze consumer sentiment around electric cars? Scrape EV reviews. Trying to improve a resume parser? Grab job listings and candidate profiles. You get exactly what you need.
And because the web is always changing, you can keep scraping to get updated data. That means your model doesn’t just learn once—it keeps learning, stays current, and adapts as new trends or language patterns show up.
In short, web scraping isn’t just some backend data trick. It’s a real strategic advantage, especially when you’re trying to train deep learning AI systems that need to learn from how people think, talk, and interact online.
How Web Scraping Feeds Deep Learning Models: A Step-by-Step Look
So now that we’ve talked about why deep learning needs a ton of data and how web scraping helps get it, let’s walk through what the actual process looks like. Because scraping the web sounds simple, but turning that raw, messy data into something your model can learn from takes a few smart steps.
Identify the Right Data Source
So, you start by figuring out where to get the kind of data your deep learning model actually needs. It could be anything—product pages on e-commerce sites, travel blogs, forums, or social media platforms. If you’re training a deep learning AI to pick up on customer sentiment, for example, scraping user reviews from e-commerce sites or real-time posts from Twitter makes sense. The trick is to focus on sources that have plenty of examples your model can learn from.
Choose the Appropriate Scraping Technique
Scraping the web isn’t always straightforward. Depending on how the website is built, you’ll pick different scraping methods. The most common one is HTML parsing—basically, your code digs through the page structure to grab the bits you want. Sometimes, websites offer APIs that deliver cleaner, more organized data, which makes your job easier. And for sites that load content dynamically with JavaScript, tools like Selenium or Puppeteer act like invisible browsers that capture everything a regular user would see.
Clean and Preprocess the Scraped Data
Raw web data is almost always messy. You get junk like extra HTML tags, broken sentences, repeated info, or errors. That’s where cleaning and preprocessing come in. For text, you break it down into manageable chunks, get rid of filler words, or turn words into numbers that your model understands (like embeddings). For images, you might resize them, convert colors, or normalize pixels so everything fits the model’s needs. The goal is to get your scraped data into shape so the deep learning model can actually learn from it.
Feed the Data into Deep Learning Models
Once your data is cleaned up, you feed it into your deep learning architecture. For images, that’s often a Convolutional Neural Network (CNN). For text or speech, Recurrent Neural Networks (RNNs) or LSTMs do the job. And for more complex language tasks like translation, transformers are the go-to. The better the quality and variety of your training data, the sharper and more reliable your model will be.
Understand the Full Cycle for Better Results
At the end of the day, training a deep learning model isn’t just about scraping data and plugging it in. You have to know what you want your AI to do, pick the right data sources, clean up the mess, and then train the model properly. Nail all these steps, and you go from a model that barely gets by to one that really understands what it’s looking at.
How Web Scraping Powers Deep Learning AI for Sentiment Analysis – A Use Case
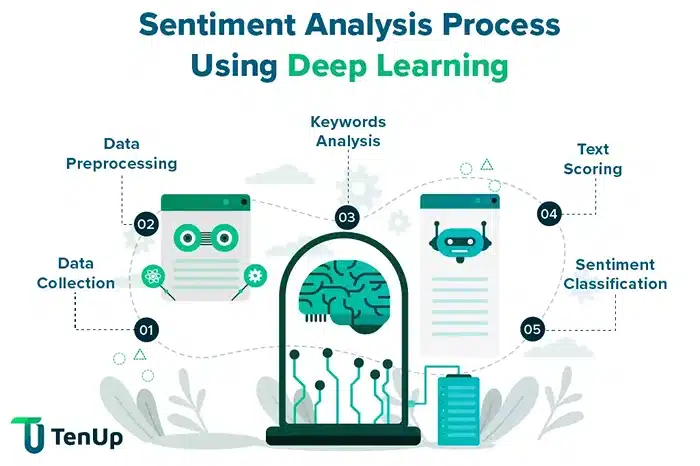
Image SoucrE: tenup
Let’s say you’re building an AI system that can understand how people feel about a product, a service, a movie, maybe even a political topic. This is where sentiment analysis comes in. It’s one of the most widely used natural language processing tasks, and it’s a great example of how deep learning and web scraping work hand in hand.
First off, where do you even get the data? People express opinions all over the internet—on review platforms like Amazon or Yelp, on Twitter, Reddit, blog comment sections, and forums. If you want your model to truly understand human emotion in context, those are the places you want to tap into. And web scraping is how you gather it.
Let’s say you’re focusing on restaurant reviews. You build a scraper that pulls thousands of customer reviews, including the text, star rating, maybe even the date and location. That raw text is your goldmine.
But before a deep learning model can work its magic, you need to clean and prep that text. That might mean removing emojis or special characters, lowercasing everything, and then breaking the text down into tokens (words or phrases the model can understand). You might also use something like word embeddings—Word2Vec or BERT, for instance—to turn those tokens into numbers that capture meaning, not just spelling.
Now, you feed that structured, numerical data into your deep learning AI model—usually something like an LSTM, GRU, or transformer-based model that can understand sequences and context. The model learns not just from keywords like “amazing” or “terrible,” but also from how those words are used in sentences.
Here’s where deep learning really shines. A traditional machine learning model might get confused by sarcasm or subtle tone shifts. But with enough varied training data, a deep learning model can start picking up on context, like the difference between “This place is sick (in a good way)” and “This place made me sick.”
In a real-world project, one team scraped over 500,000 reviews to train a deep learning model that could detect nuanced emotion with over 90% accuracy. That level of performance just wouldn’t be possible without a steady stream of relevant, real-world text data—which, again, web scraping delivered.
So whether you’re building a chatbot that can respond empathetically, a brand monitoring tool, or a product feedback engine, combining web scraping for training models with deep learning is one of the most effective ways to make sure your AI can actually “read the room.”
What Happens When You Feed Web-Scraped Data to Machine Learning vs Deep Learning?
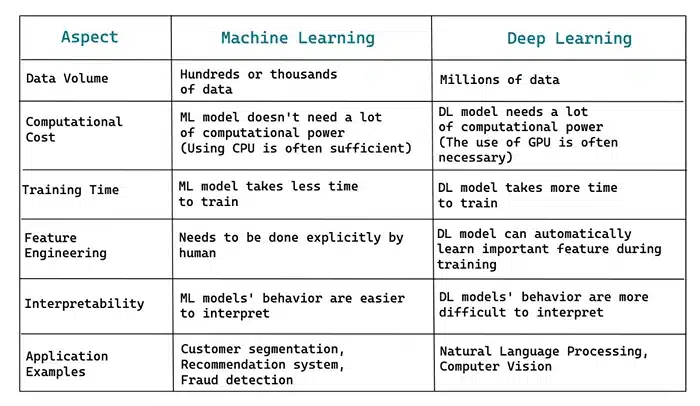
Image Source: stratascratch
By now, you probably see how powerful web-scraped data can be for AI models. But here’s the big question: how do machine learning and deep learning compare when you train them on this kind of data?
Let’s start with traditional machine learning. It’s been around longer, and it works well for structured problems, things like spam detection, basic recommendation engines, or predicting numerical values from clean, labeled data. But here’s the catch: machine learning models usually need a lot of hand-holding. You have to manually choose and engineer the features. For example, if you’re analyzing product reviews, you might have to decide that the number of exclamation points or the presence of certain keywords is important. It’s more rule-based and often less flexible.
Now let’s contrast that with deep learning. These models are designed to learn directly from raw, unstructured data. You don’t need to spend weeks building feature sets or guessing what might matter. Whether it’s text, images, or even audio, deep learning AI models can automatically figure out the most relevant features, especially when trained on large and diverse datasets scraped from the web.
Let’s take a real-world example. Imagine you’re building a model to classify customer feedback. You feed both a machine learning model and a deep learning model with the same scraped dataset, let’s say 100,000 user comments from e-commerce sites. The ML model might perform decently if you carefully engineer the input, but it could struggle with things like sarcasm, slang, or complex sentence structure. The deep learning model, on the other hand, can learn patterns in how people write, even if it’s informal or inconsistent.
There’s also the issue of scale. Deep learning thrives when you give it a lot of data. In fact, most deep learning models start outperforming traditional ML models only when they’re trained on large-scale datasets, often in the hundreds of thousands or millions of examples. That’s exactly where web scraping becomes indispensable. It’s one of the few ways to reliably collect that much real-world AI training data, tailored to your specific domain.
Of course, deep learning comes with its own trade-offs. Training takes more time, requires more computing power, and can be harder to interpret. But if your scraped data is messy, unstructured, or full of subtle context clues, as it usually is, then deep learning almost always delivers better performance.
So, in short: machine learning is fast and efficient, but deep learning is more powerful and adaptable, especially when fueled by rich, diverse web data. And in today’s world of chaotic, user-generated online content, that edge can make all the difference.
Key Challenges in Web Scraping for AI Training
Web scraping sounds like the secret sauce for feeding deep learning models, but trust me, it’s not all sunshine and rainbows. If you want to do it right and at scale, you’re going to hit some real challenges.
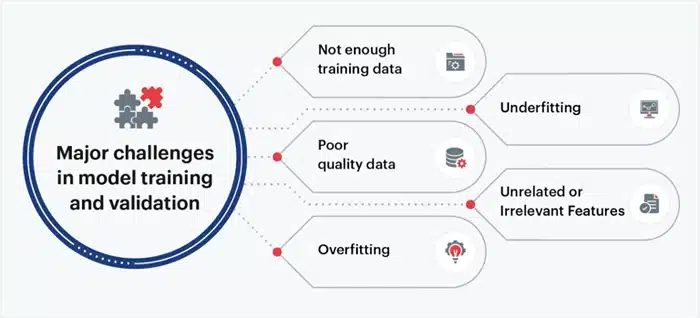
Image Source: sigmoid
Legal and Ethical Concerns
First up, there’s the whole legal and ethical side of things. Not every website wants you scraping their data, some actually ban it in their terms of service. If you ignore those rules, you could find yourself in hot water legally. On top of that, privacy laws like GDPR and CCPA are serious business, especially if you’re scraping personal info. Bottom line? Know the rules and get legal advice if you’re dealing with sensitive data.
Messy, Unstructured Data Is a Pain
Websites are made for humans, not machines. That means the data you grab might be full of annoying stuff like ads, menus, or weird formats. Cleaning all that mess takes time, but it’s non-negotiable. If you feed your model garbage data, it’ll spit out garbage results.
Watch Out for Bias in Your Data
Bias is a sneaky problem. If your scraped data isn’t balanced, your deep learning model will pick up on that and make unfair or inaccurate predictions. For example, if you mostly scrape positive reviews, your sentiment model is going to be overly optimistic. You have to carefully pick where your data comes from and maybe mix in other sources to keep things fair.
Handling Huge Amounts of Data Can Overwhelm You
When you scrape a lot, data just keeps pouring in nonstop. Without a solid system to store, clean, update, and watch over that data, your project can spiral out of control fast. Setting up automated pipelines and monitoring tools is the only way to keep everything running smoothly.
Best Practices for Using Web Scraping to Train Deep Learning AI
If you’re scraping the web to train deep learning models, it’s not just about grabbing tons of data—you gotta do it right so your models actually learn something useful. Here’s what really matters:
Automate Your Scraping
The internet moves fast. Things change every day, so you want your scraping to happen automatically. Setting up a pipeline that keeps pulling fresh data means your models always get the latest info without you lifting a finger. This is super important if you’re working with stuff like reviews, social media posts, or breaking news that changes all the time.
Clean Up Your Data
Web data is messy. You’ll find ads, random junk, broken links—you name it. If you just throw all that at your deep learning model, you’re asking for trouble. Take the time to clean it up. Get rid of the nonsense, fix mistakes, and organize it so the model sees only the good stuff. This is the secret sauce to better training.
Don’t Scrape Alone—Use Other Data Too
Scraping is great, but it’s not perfect. Mix your scraped data with good public datasets that are already cleaned up. This way, you fill in gaps and avoid weird biases from one source. Your model ends up smarter because it learns from different angles.
Think About Your Computing Power
Training deep learning models takes serious computing power, especially with huge scraped datasets. Use cloud services or distributed systems so you can scale up when needed. That way, you don’t get stuck waiting forever or running out of memory when things get big.
Do these things, and web scraping won’t just be a data grab—it’ll be a real edge for building smarter deep learning models.
Web Scraping as a Catalyst for Scalable Deep Learning AI
To wrap things up, the difference between deep learning vs machine learning really comes down to how they handle data, especially the kind of messy, varied information you find all over the web. Traditional machine learning often struggles without carefully crafted features and clean data, while deep learning AI shines by learning patterns directly from large-scale, unstructured datasets.
That’s where web scraping for training models steps in. It’s become a game changer because it opens up access to vast, diverse, and real-time data that you just can’t get from standard datasets. This continuous stream of fresh data fuels deep learning models, helping them improve in accuracy, adaptability, and relevance.
Of course, scraping comes with its own challenges, legal concerns, messy data, bias, and infrastructure demands. But when handled thoughtfully, it’s a powerful tool that can take your AI projects to the next level.
Looking ahead, the future looks even more exciting. Techniques like self-supervised learning, synthetic data generation, and ongoing scraping pipelines promise to make training deep learning models faster, smarter, and less dependent on manual labeling. If you’re serious about building complex AI models, embracing web scraping isn’t just an option—it’s becoming essential.
So, whether you’re a data scientist, AI engineer, or just curious about AI’s possibilities, understanding how web scraping fuels deep learning will give you a big advantage in this rapidly evolving field.
If you want reliable, up-to-date data to train your deep learning models, PromptCloud has you covered. Let’s get your AI projects moving forward with the data they deserve. Contact us today!















