




**TL;DR**
AI pipelines fail more often because of poor data quality and unclear compliance than because of weak models. Web scraping compliance shapes how data enters the system, and quality standards determine whether models can rely on that data later. This pillar breaks down how compliant collection, governance, validation, and structured pipelines work together to create trustworthy training datasets for AI. It is a foundation for any team building large scale, data-driven systems where clean, compliant inputs matter as much as the model itself.
Why Data Quality and Compliance Now Matter in AI
Every AI system rests on one simple assumption. The data feeding it is reliable. Most teams discover the opposite sooner than they expect. A model that looks stable in testing behaves unpredictably in production. A feature that once improved accuracy suddenly introduces noise. A pipeline that ran for months without issue starts producing strange outputs with no clear cause. These symptoms rarely point back to the model. They almost always point back to the data.
The shift toward large-scale AI has made these problems larger, not smaller. Today’s models consume more data, rely on deeper context, and demand stronger consistency. This makes governance and quality control essential. A single weak link in the pipeline can distort model behavior across thousands of predictions. A model that depends on scraped data must understand the boundary between legal access, ethical use, and structured collection practices.
The Data Pipeline Behind Every AI System
Every AI workflow, no matter how advanced, follows a simple truth. The data pipeline determines the ceiling of model performance. Most failures that appear downstream in predictions can be traced back to something that happened upstream in the pipeline. A missing field. A broken selector. A mislabeled attribute. A timestamp in the wrong format. A source that changed structure without warning. These issues may seem small, but they shape how a model interprets the world.
A data pipeline is not a single step. It is a chain of decisions and transformations that begins the moment raw information is collected. Web data makes the chain even more sensitive because structure varies across sources. If the pipeline is not designed with quality and compliance in mind, issues spread silently into feature engineering, training, and evaluation.
Here is the flow most AI teams rely on, whether they build their own pipeline or use managed data.
Ingestion
This is where data enters the system. Scrapers, crawlers, APIs, and feeds all contribute raw inputs. Ingestion is also where most compliance boundaries live. Teams must consider access rules, robots directives, rate limits, and jurisdiction-specific guidelines. When ingestion breaks, every downstream step inherits the error.
Normalization
Raw web data rarely arrives in a compatible structure. Field names differ across sites. Units vary. Formats shift. Normalization aligns these differences into one predictable structure. If normalization is weak, feature creation becomes inconsistent.
Validation
This is the quality gate. Validation checks for type mismatches, missing values, duplicates, and schema drift. Strong validation protects models from absorbing incorrect assumptions. Weak validation lets noise slip through and reshape model behavior without notice.
Enrichment
Additional fields such as metadata, category mapping, identifiers, and derived attributes are added here. Enrichment strengthens context, but it also amplifies errors if earlier stages were inconsistent.
A pipeline becomes trustworthy only when each stage adds clarity instead of distortion. When teams treat quality and compliance as foundational rather than optional, their AI systems behave more predictably. When they ignore these early steps, issues compound and become harder to diagnose later.
See how PromptCloud delivers structured web datasets from your target websites without building or maintaining scraping infrastructure.
Understanding Web Scraping Compliance
Most teams treat web scraping compliance as a legal checkbox. Something to glance at, acknowledge, and return to later. In practice, compliance shapes the entire data pipeline. It determines what you can collect, how you can collect it, how often you can access a source, and what you can use the data for once collected. Compliance is not a side topic. It is the first gate that decides whether your AI training dataset is usable, defensible, and safe to deploy.
The confusion often comes from the difference between public data and publicly accessible data. Public does not always mean free to extract or reuse. Many sites allow viewing but restrict automated extraction. Others permit limited access with clear conditions. Some restrict commercial use or require attribution. Understanding these layers is the first step to building compliant AI pipelines.
Here are the elements that define real web scraping compliance.
Robots directives and access rules
Robots.txt does not carry absolute legal weight, but it communicates access preferences. Compliance-aware pipelines respect these directives, especially for rate limits and disallowed paths.
Authenticated or paywalled content
Accessing restricted areas without permission creates immediate compliance violations. Models trained on such data inherit the risk.
Purpose of use
Training AI models has its own legal considerations. Using scraped data for internal analysis is different from using it to train a commercial model. Teams often overlook this distinction.
A compliant scraping pipeline is transparent, predictable, and well documented. When teams understand compliance as a safeguard rather than a restriction, their data becomes safer to build on. Their AI systems become easier to defend. And their models avoid the risk of being trained on datasets that may later become unusable.
The Compliance Checklist for AI Training Data
Source validation
Before collecting anything, teams need to understand whether the source permits automated access. This includes reviewing access preferences, usage policies, and any limitations on commercial extraction. A dataset is only as safe as its source.
Data ownership and licensing
Some content belongs to the platform. Some belongs to the user. Some is licensed from third parties. Ownership determines whether the extracted data can be repurposed for AI training. Misunderstanding ownership creates long-term exposure for downstream systems.
Privacy and personal data removal
Any trace of personal information requires careful handling. Privacy laws treat identifiable details differently from generic public data. Removing, masking, or avoiding personal data altogether is essential in most pipelines, especially those crossing regions.
Handling copyrighted material
Copyright laws do not end at the scraping layer. Even publicly viewable material may be copyrighted. Some use cases fall under fair use. Others do not. Teams must consider how copyright interacts with model training and dataset distribution.
Data minimization
Compliance is not only about what you collect. It is also about what you avoid collecting. Minimizing unnecessary fields reduces both risk and storage burden. Collect only what the model needs.
Secure storage and retention
Once data enters the pipeline, teams must control how long it stays there. Retention policies enforce deletion timelines. Storage controls ensure that only authorized teams can access raw or enriched data.
A compliance checklist is not a barrier to AI innovation. It is the safety net that allows teams to scale data pipelines without carrying hidden risk. When combined with strong quality standards, it builds an environment where models can improve confidently without unexpected legal or operational setbacks.
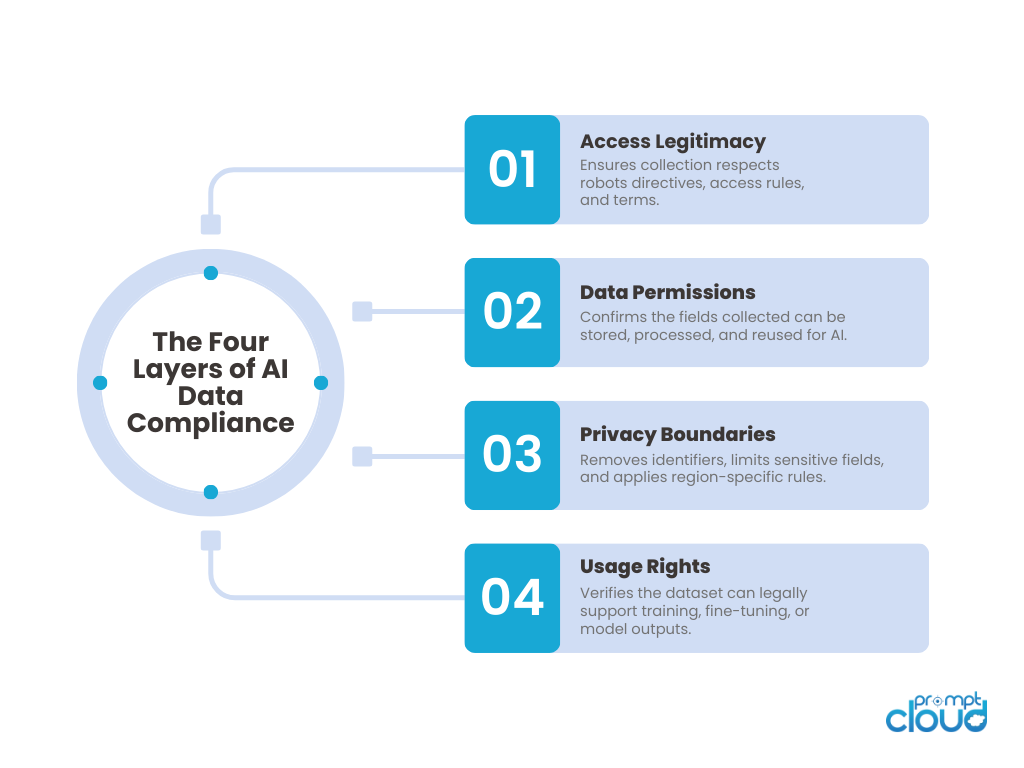
Figure 1. The four compliance layers that govern how AI teams collect, store, and use web data responsibly.
Data Quality for AI: The Five Standards Every Pipeline Needs
Data quality is not one metric. It is a set of interconnected standards that determine whether a model can learn from the data without misinterpreting patterns. When one standard weakens, the entire pipeline becomes unstable. AI systems do not fail instantly when data degrades. They fail slowly, through quiet distortions that accumulate across training cycles. By the time symptoms appear, the damage has already passed through multiple layers.
Strong AI pipelines rely on five universal data quality standards. These standards apply to every dataset, regardless of domain, volume, or model type.
Accuracy
Accuracy determines whether each field reflects the truth. A common example appears in e-commerce data. When sale prices are scraped from dynamic elements and fail to load, the model sees full price instead of discounted price. This single difference reshapes demand curves downstream.
Completeness
Completeness measures how many required fields are present across records. Missing values weaken patterns. A dataset with partial product attributes or missing sentiment labels creates unstable training signals.
Consider a reviews dataset with thirty percent missing ratings. The model tries to infer sentiment-aligned patterns without the primary label. It learns from incomplete context and produces weaker predictions.
Consistency
Consistency ensures that fields behave the same way across sources, regions, and time periods. Without consistency, the model treats equivalent values as different concepts.
A simple inconsistency such as “USD 20,” “20 USD,” and “20$” creates unnecessary variation. The model sees noise instead of price.
Lineage and traceability
Without lineage, debugging becomes guesswork. With lineage, teams can trace anomalies back to specific sources or processing steps.
If a field suddenly drops coverage, lineage can reveal whether a source updated its layout or if internal mapping broke. This clarity keeps the model safe from hidden drift.
Training Data Governance: Keeping AI Datasets Accountable
Here are the core elements that shape effective governance in AI pipelines.
Dataset contracts
A dataset contract sets expectations between producers and consumers. It defines which fields must exist, what types they carry, and how they behave across versions. Contracts prevent surprise changes that break feature engineering or shift model performance.
A simple example is a category field. If the taxonomy changes without notice, downstream models learn misaligned patterns. Contracts avoid these mismatches by enforcing structure.
Retention policies
Governance defines how long data stays in the system. Some regions impose mandatory deletion windows. Some use cases require fresh inputs only. Retention policies remove outdated or non-compliant data before they affect the model.
Strong governance avoids a common risk. Old or irrelevant datasets silently influence training long after they should have been removed.
Access controls
Not every user needs full access to training data. Governance limits who can view, modify, or export datasets. These controls reduce operational risk and help teams maintain privacy boundaries.
A data scientist building a feature may only need enriched fields. An engineer monitoring ingestion may require access to raw input logs. Governance ensures each role sees only what is appropriate.
Drift monitoring
Drift occurs when data moves away from the patterns the model originally learned. Governance includes the processes and monitors that detect drift early. Whether it is a missing field, a new layout, or a shift in category distribution, drift must be caught before it becomes a model-wide issue.
Teams that lack drift monitoring usually discover problems only when predictions degrade.
Governance as an operational safeguard
When governance is strong, AI pipelines behave predictably. When it is weak, small inconsistencies accumulate. Governance is about protecting the model from silent failures that originate upstream. It keeps data accountable, transformations transparent, and outcomes explainable.
Where Web Scraping Breaks Data Quality and How to Fix It
Below is a breakdown of where web scraping typically weakens data quality—and what robust pipelines do to prevent it.
Selector breakage
A minor HTML change can break a selector. When this happens, fields silently return blanks, mismatched values, or fallback defaults. These errors often go unnoticed until the model behaves strangely.
Fix: Automated selector monitoring, fallback strategies, and diff-based layout detection.
Dynamic rendering issues
Prices, ratings, and availability often load through JavaScript. Basic scrapers miss these values entirely.
Fix: Headless browser engines or API-based extraction where available.
Inconsistent labeling
Different sites use different terms for the same concept. “Savings,” “discount,” “deal price,” and “offer price” may all refer to the same field.
Fix: Normalization rules and a central schema registry.
Schema drift across sources
As markets evolve, fields change in meaning. A “discount_price” field may switch from percentage to value. Models cannot detect this shift without careful oversight.
Fix: Schema enforcement, versioning, and automated comparison of historical patterns.
Mixed formats
Currencies, units, dimensions, ratings, and timestamps often arrive in different formats. These inconsistencies quickly weaken downstream features.
Fix: Unified formatting at ingestion, plus type enforcement.
Duplicates and partial duplicates
Websites often surface repeated items with small variations. These distort training distributions and inflate certain feature weights.
Fix: Deduplication logic with hash-based and field-based comparison.
Outliers caused by bad parsing
One broken data point can skew averages, medians, or category-level features.
Fix: Anomaly detection with threshold rules and statistical checks.
Table 1 — How Web Scraping Creates Data Quality Issues
| Scraping Issue | How It Affects AI Models | What a Strong Pipeline Does |
| Selector breakage | Missing or misaligned fields distort feature inputs | Auto-detect layout changes and reroute extraction |
| Dynamic content not captured | Models learn from incomplete or stale signals | Render pages or use structured APIs |
| Label differences across sites | Equivalent values treated as unrelated concepts | Normalize labels under a unified schema |
| Schema drift | Model learns outdated patterns or misinterprets fields | Enforce schema versioning with alerts |
| Mixed formats | Numerical models receive incompatible values | Standardize units, formats, and types |
| Duplicates | Biased training distributions | Deduplicate with rules and fingerprinting |
| Parsing anomalies | Outliers shift model weights unexpectedly | Run anomaly detection and filter |
High-quality data pipelines anticipate these issues before they become model problems. The solution is not to scrape more aggressively. The solution is to collect responsibly, standardize rigorously, validate continuously, and enforce structure at every step. When scraping is paired with strong governance, the dataset becomes predictable and the model becomes far easier to trust.
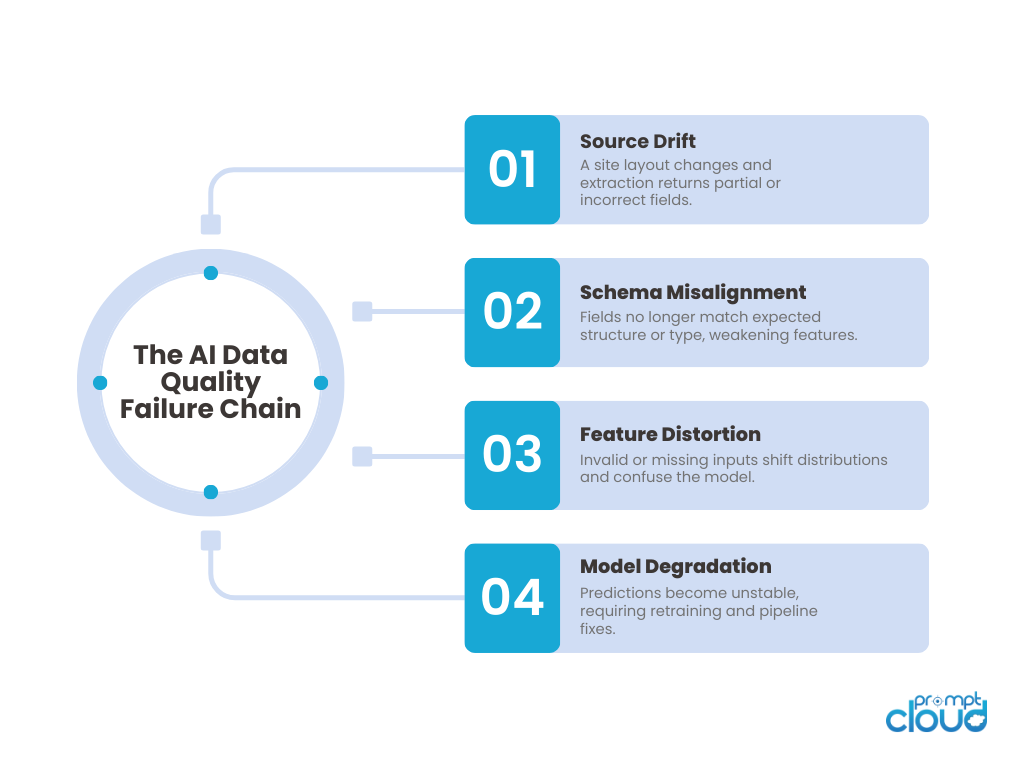
Figure 2. How a single data extraction failure cascades through the pipeline, ultimately degrading model accuracy.
Building an AI-Ready Data Quality Framework
An AI model is only as good as the environment that prepares its data. A data quality framework establishes that environment. It defines the rules, checks, and safeguards that ensure every record entering the pipeline is consistent, correct, complete, and compliant. Without a framework, teams rely on ad-hoc checks that catch issues only after they surface in model behavior. With a framework, data becomes predictable enough to support continuous training and large-scale automation.
An AI-ready framework does not require complex infrastructure. It requires discipline, structure, and a clear understanding of where failure begins. The goal is to build a system that prevents issues rather than reacting to them later.
Below are the key pillars of a strong AI data quality framework.
Standardization
Standardization aligns values, formats, and field structures across every source. When teams standardize early, the model sees consistent inputs regardless of where the data originated.
Common standardization rules include:
- Normalizing currency and units
- Mapping categories into controlled taxonomies
- Structuring prices, ratings, and dimensions
- Using universal date and timestamp formats
These rules remove noise before it enters feature engineering.
Field validation
Validation ensures the pipeline does not accept malformed or incomplete records. It checks types, required fields, length constraints, and expected patterns.
Examples:
- Price must be numeric
- Rating must be within valid range
- Timestamp must follow a specific format
- Category cannot be blank
Validation prevents silent drift from corrupting downstream outputs.
Schema enforcement
A strong schema acts as the backbone of the dataset. Schema enforcement ensures that all records follow the same structure, no matter the source.
This prevents issues like:
- Extra fields appearing unexpectedly
- Required fields dropping out
- Types changing without notice
Schema enforcement keeps the training environment stable across dataset versions.
Metadata taxonomy
Metadata provides the context needed to interpret data accurately. Source, region, parser version, crawl time, and processing steps all help teams understand anomalies.
Metadata also supports reproducibility. If a dataset behaves differently, metadata shows what changed.
Outlier and anomaly detection
Outlier detection catches values that fall outside expected ranges. These anomalies may come from broken selectors, missing fields, or misaligned inputs.
Statistical checks include:
- Price spikes
- Negative values
- Duplicate listings
- Unusual category shifts
Early detection protects the model from absorbing flawed patterns.
Human-in-the-loop review
Automation prevents large-scale failures. Human review prevents subtle ones. Reviewers catch nuances that automated rules miss, especially in complex, multi-source datasets.
Human-in-the-loop checks often cover:
- Category mismatches
- Incorrect mapping
- Formatting inconsistencies
- Interpretation of ambiguous labels
Automated monitoring triggers
Triggers alert teams when coverage drops, types change, fields drift, or patterns shift. These early warnings allow teams to intervene before the model is retrained on compromised data.
Examples:
- Drop in price coverage
- Sudden rise in null fields
- Category distribution changes
- Parser version mismatches
Good monitoring turns unpredictable pipelines into stable systems.
An AI-ready quality framework is not a single tool or feature. It is a layered foundation that keeps the model safe from upstream issues. When teams treat quality as part of the model’s architecture rather than an add-on, they build AI systems that behave predictably, scale confidently, and stand up to real-world scrutiny.
Compliance-First Web Scraping Architecture
A compliant web scraping architecture is not defined by how much data it collects. It is defined by how responsibly it collects that data. Compliance must be a design principle, not an afterthought. When the architecture respects access preferences, legal boundaries, and ethical constraints, the pipeline stays predictable and defensible. When compliance is ignored, even high-quality data becomes unusable in AI systems.
A compliance-first architecture begins at the ingestion layer. It starts with a clear understanding of what the source allows, how frequently it can be accessed, and what purpose the data may be used for. This prevents teams from building datasets that later must be discarded.
Below are the pillars of a responsible scraping architecture.
Respecting access and rate rules
Sources communicate their preferences through robots directives, TOS provisions, and rate guidelines. Ignoring these rules creates unnecessary exposure and introduces instability. A compliant pipeline aligns crawling speed with acceptable load patterns.
Clear separation of permitted and restricted zones
A well-designed system never touches authenticated, paywalled, or user-specific content unless explicit permission exists. This separation protects the dataset from acquiring information it cannot legally store or use.
Ethical collection behaviors
Compliance extends beyond legality. Ethical collection includes limiting volume to what is needed, avoiding disruptive patterns, and refusing to collect unnecessary personal attributes. This protects both the model and the organization.
Jurisdiction-aware routing
Data collected in one geography may be governed by different retention, storage, and consent rules than data collected elsewhere. A compliance-first pipeline routes data into region-appropriate storage and enforces region-specific policies automatically.
Consent and transparency safeguards
Some use cases require clear documentation of why the data was collected and how it will be used. AI teams benefit from traceability not because auditors need it, but because transparency strengthens internal decision-making.
Compliance logging and audit trails
Every ingestion event, parser update, schema change, and deletion must be recorded. These logs form the backbone of audit readiness and help teams explain how a particular dataset was created.
Minimal collection principles
A compliance-first pipeline collects only the fields required for the AI task. Minimalism reduces both legal exposure and downstream noise, improving model performance while keeping the dataset clean.
A responsible architecture protects the model by protecting the data feeding it. As AI becomes more closely regulated, compliance is no longer an optional layer. It is the foundation that ensures data collected today remains usable tomorrow. With strong compliance habits, teams prevent costly rework, maintain public trust, and build data pipelines that scale safely.
Why Clean and Compliant Data Defines the Future of AI
Most AI discussions focus on model architecture, training techniques, or hardware efficiency. Yet the most influential part of an AI pipeline has always been upstream. The data that enters the system determines the limits of what the model can understand. When that data is inconsistent, incomplete, or collected without attention to compliance boundaries, the model inherits those weaknesses in ways that cannot be easily reversed.
High-quality datasets behave like stable ground beneath the model. They make training predictable and create outputs that remain consistent across time, categories, and markets. Compliance adds a second layer of stability. It ensures that every dataset in the pipeline can be used confidently, shared internally, and retained through product lifecycles without regulatory risk. Clean data improves performance. Compliant data protects longevity.
The connection between these two forces becomes clearer as AI systems scale. A model built on weak data works in controlled environments but collapses when conditions shift. A model trained on data collected without compliance safeguards may face forced deletion later, undoing months of work. Data quality and compliance are no longer administrative concerns. They are engineering concerns that directly shape model outcomes.
A modern AI pipeline must do more than extract information.
It must validate it.
Standardize it.
Document it.
Govern it.
And most importantly, it must treat compliance as part of the design, not post-processing.
Teams that embrace this approach build AI systems that last. Their models remain interpretable. Their datasets remain traceable. Their workflows remain defensible. And their organizations earn the confidence to scale AI responsibly without carrying hidden risk.
The future of AI will not be defined only by larger models or faster chips. It will be defined by teams that treat data as an engineered asset rather than an opportunistic by-product. Clean data makes models accurate. Compliant data makes them sustainable. Together, they form the foundation on which reliable AI is built.
Further Reading From PromptCloud
Here are four related resources that connect well with this pillar:
- See how modern infrastructure supports AI-ready workflows in AI-Ready Web Data Infrastructure 2025
- Understand the attributes that make datasets dependable for training in What Makes Data AI-Ready
- Learn how pipelines should be structured for stability and scale in AI Data Pipeline Architecture
- Explore how real-time scraping supports complex marketplaces in Black Friday Web Scraping for Ecommerce
A detailed industry perspective on ethical and compliant data collection can be found in OECD’s Framework for Responsible Data Access and Use which outlines global best practices for governance, transparency, and responsible extraction.
See how PromptCloud delivers structured web datasets from your target websites without building or maintaining scraping infrastructure.
FAQs
1. Why is web scraping compliance essential for AI pipelines?
Compliance determines what can be collected, how it can be used, and whether the dataset remains legally sound over time. Without compliance safeguards, AI teams risk building models on data that may need to be deleted later.
2. How does poor data quality impact AI model performance?
Models learn whatever patterns appear in the data. Missing values, inconsistent formats, or mislabeled attributes distort these patterns, lowering accuracy and making predictions unreliable.
3. Can public web data always be used for AI training?
Not always. Public does not mean unrestricted. Terms of service, licensing boundaries, and jurisdiction laws shape how data can be repurposed. Some uses require explicit permissions.
4. What is the role of metadata in compliant AI pipelines?
Metadata provides traceability. It shows where data came from, when it was collected, and how it was processed. This context is essential for debugging, auditing, and demonstrating responsible use.
5. What is the biggest data quality issue caused by web scraping?
Silent drift. When a site changes structure and the extractor continues running without detection, the dataset accumulates incorrect values that spread into training sets without warning.
6. How often should compliance reviews occur?
Continuously. Compliance is not a one-time check. It should be integrated into ingestion, processing, and storage workflows, with audits performed regularly.
7. Does stronger compliance slow down data collection?
No. When designed well, compliance frameworks improve reliability. They prevent pipeline breakages, reduce rework, and keep the dataset safe for long-term use.















