




**TL;DR** Trying to keep tabs on every change across dozens of websites? Good luck doing that manually. Content shifts constantly, prices jump overnight, reviews pile up, and competitors launch new pages while you’re still refreshing old ones. If you’re still relying on scattered tools or copy-paste scraping hacks, you’re bringing a notepad to a data flood.
A content crawler flips the script. Think of it as your digital scout: moving through websites at scale, picking up what matters, product details, prices, news articles, stock levels, and handing it back in clean, structured data you can use. No mess, no lag. Just real-time visibility.
And this isn’t fringe anymore. A 2023 survey found that 6 in 10 enterprises now automate web data collection, with most reporting faster decision-making and leaner ops. From e-commerce brands tracking thousands of SKUs to travel portals monitoring fare fluctuations, to research firms pulling insights from media sites, automated crawling is how they stay sharp.
Bottom line? A website content crawler isn’t just about scraping websites faster. It’s about scaling your monitoring without burning out your team and getting insights the moment they matter, not weeks later.
The web never sits still. Prices shift overnight, new content goes live every minute, and competitor updates happen while you’re still refreshing yesterday’s pages. If your job depends on tracking all of this, whether it’s product listings, travel fares, or industry research, you know how exhausting manual monitoring can be.
Here’s the reality: over 250,000 new websites are created every single day. Add in the constant edits, stock changes, or fresh reviews on existing ones, and suddenly “keeping track” feels more like chasing shadows. You could throw more people at the problem, or try patching together one-off scripts, but at some point, the scale just breaks you.
That’s exactly why content crawlers exist. Instead of refreshing pages by hand or running fragile scraping hacks, a crawler acts like a tireless digital scout, combing through sites, collecting the updates you care about, and feeding them back as clean, structured data. Think of it as the difference between hunting for needles in a haystack yourself and sending out an automated magnet that brings them straight to you.
In this article, we’ll break down what a website content crawler is, how it works, and where businesses are using it to win. We’ll also look at the practical benefits, from real-time insights to operational efficiency, and what to watch for when choosing the right approach.
What is a Content Crawler?
Think of a content crawler as your digital scout. While you’re busy running product launches or analyzing dashboards, it’s out there, combing through websites, picking up the updates you care about, prices, product details, reviews, news, and neatly dropping them back in your lap as structured data.
Now, you’ve probably heard the term web crawler before (Google’s bots that map the entire internet). A website content crawler is similar, but way more targeted. Instead of wandering across the web, it zeroes in on the sites that matter to you, digs into their pages, and extracts just the information you need.
Here’s the difference in practice:
- With manual methods, you’re stuck copy-pasting or running fragile scripts that break the moment a website redesigns its layout.
- With a content crawler, you get consistency. It doesn’t panic when a button moves or a new filter appears. It adapts, navigates, and keeps the flow of data steady.
And here’s the kicker: the web doesn’t just grow, it explodes. Every single day, well over a quarter of a million new sites go live, and the ones already out there are constantly shifting prices, reviews, stock levels, and entire layouts. There isn’t a team on the planet that can keep pace with that flood by hand.
That’s where a content crawler earns its keep. Instead of throwing people at the problem, you’ve got a system that quietly works in the background, scanning hundreds or even thousands of sites and feeding you the changes as they happen. The real value isn’t just about speed. It’s knowing you won’t be blindsided. Instead of waking up to find your competitor quietly slashed prices, or realizing too late that reviews have spiked overnight, you already have the update in hand. Even if the market shifts suddenly, you’re not scrambling to catch up, you’re ready.
How Does a Content Crawler Work?
So how does a content crawler do its job? Instead of drowning you in technical terms:
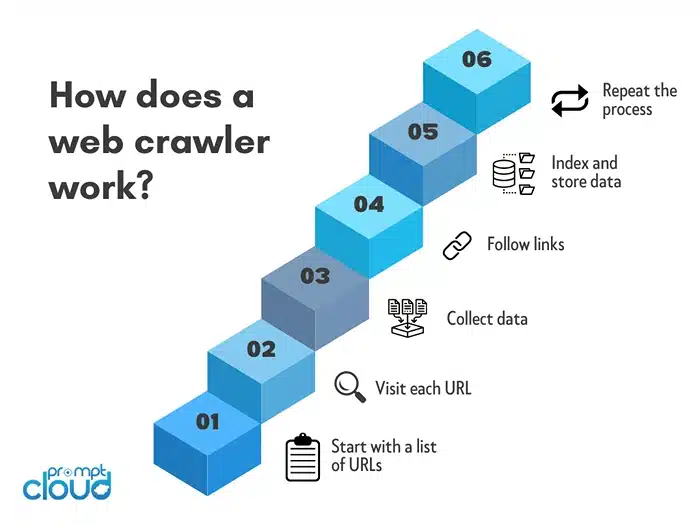
- The Scout Sets Out
First, you tell the crawler where to go. Maybe it’s ten competitor websites, maybe it’s a thousand product pages, maybe it’s a bunch of travel portals. The crawler gets its marching orders and starts moving through those sites like a tireless intern who never needs coffee breaks.
- The Spotter’s Eye
Once inside a page, the crawler doesn’t just see “a website.” It knows how to pick out the pieces that matter: that price tag next to the product, the review count under a listing, the headline on a news article. It’s like giving it a checklist and saying, “Only grab these.”
- The Organizer’s Touch
Here’s the real magic. Instead of dumping messy HTML on your desk, the crawler cleans and structures the data. Think CSVs, JSON feeds, or APIs that slide right into your analytics tools or dashboards. You get usable information, not digital spaghetti.
- The Messenger
Finally, the crawler delivers. You can set the pace however you like, maybe the crawler checks once a day, maybe every hour, or even continuously if the data is that critical. The point is, those competitor price drops, stock changes, or fresh pieces of content show up without you chasing them down. It just happens in the background while you focus on the bigger things.
Now, compare that with doing it manually: you’re clicking around sites, copying numbers, pasting into spreadsheets, and praying you didn’t miss anything. Or worse, you’re running brittle scraping scripts that collapse the second a website tweaks its layout. With a website content crawler, that whole pain disappears.
And here’s the kicker: crawlers don’t get tired, they don’t get distracted, and they don’t overlook details. When you scale from 10 pages to 10,000, they don’t even break a sweat.
Why Manual Monitoring Doesn’t Work at Scale
Trying to keep track of website changes by hand is almost impossible. You might catch a few updates if you’re watching closely, but the pace of change online is relentless. Every day, more than 250,000 new websites go live, and that’s before you count the constant churn on existing ones, prices shifting, stock levels changing, reviews piling up, and fresh content appearing. By the time your team has finished checking one set of pages, the landscape has already shifted again.
Manual monitoring breaks down for three big reasons:

- Human speed vs. web speed
No matter how many interns or analysts you throw at the problem, humans just can’t refresh and track thousands of pages fast enough. Websites change in minutes, sometimes seconds. By the time you spot a competitor’s price drop, they’ve already stolen customers.
- Error and inconsistency
Copy-pasting into spreadsheets sounds simple until you realize how often numbers get skipped, formats get mangled, or links get lost. One mistake in 10 pages might be manageable. One mistake in 10,000 pages? That’s data you can’t trust.
- Zero scalability
Manual methods don’t scale. You might manage five websites today, but what about 500 tomorrow? Or when leadership suddenly asks for daily competitor tracking across an entire region? At that point, you’re staring at an impossible workload.
And the costs of sticking with manual? Slow insights, late reactions, and competitors getting ahead while you’re still piecing together half-broken spreadsheets.
A content crawler changes that dynamic completely. Instead of scrambling to keep up, you’re always ahead, watching changes in real time, across hundreds or thousands of sites, without burning out your team.
Real-World Use Cases of Content Crawlers
So, where do content crawlers make a difference? Pretty much anywhere, the web changes faster than humans can keep up. Let’s paint the picture.
E-commerce: Prices That Never Sit Still
Picture this: you’re running an online store selling headphones. At 9:00 a.m., your competitor drops the price of a best-seller by $20. By lunchtime, their sales are surging and yours are crawling. If you only notice that change at the end of the day, you’ve already lost. A content crawler solves this by constantly scanning product listings, flagging every change in price, stock, or even reviews. No guesswork, no delays. And it’s not just theory, surveys show nearly 3 out of 4 leading e-commerce players now use automated crawlers to track prices and stay ahead.
Travel: Fares That Flip Overnight
If you’ve ever checked a flight at breakfast and found a different fare at dinner, you know how volatile travel pricing is. Now imagine trying to track that manually across thousands of routes and hotels. Impossible. Travel sites rely on crawlers to keep their fare feeds accurate, constantly pulling live data so customers don’t see yesterday’s prices. Without automation, they’d be out of the race before takeoff.
Research and Consulting: Mining the Market
Consulting teams live on fresh data, policy updates, competitor moves, and consumer sentiment. But finding it manually is like scooping water with a sieve. Crawlers let analysts track hundreds of news sites, forums, and regulatory portals in one stream, pulling the signal out of the noise. Deloitte reports that over half of consulting projects now tap automated web data to feed insights that would take weeks to gather otherwise.
Media and Publishing: Staying in the Loop
Editors can’t afford to miss a story. Competitors publish first, and you’re already behind. That’s why so many publishers lean on crawlers. They can keep an eye on news feeds, competitor updates, and fresh stories the moment they land. The point isn’t to replace reporters, it’s to take the tedious monitoring off their plate so they can spend their time writing and shaping stories, instead of sitting there hitting refresh on a browser tab.
In each of these worlds, the pattern is the same: the web is too fast, too vast, and too messy to track by hand. A website content crawler makes the impossible possible, turning floods of raw updates into structured intelligence you can act on right away.
The Benefits of Automating Content Collection with a Website Content Crawler
So why go through the trouble of setting up a content crawler? Because the alternative is slow, messy, and expensive. Let’s talk about what you gain when you let automation do the heavy lifting.

Real-Time Eyes on the Web
Picture this: your competitor changes their pricing at 10:30 a.m. If you only discover it at 5 p.m., that’s a full day of lost ground. A crawler doesn’t nap or wait for someone to hit refresh. It’s constantly scanning, constantly updating, and feeding you the changes as they happen. The result? You’re making decisions on today’s data, not last week’s leftovers.
Scale Without the Headaches
Manually, you might manage to track 10 sites. Push it to 50, and you’re underwater. Push it to 500, and you’re done. A website content crawler doesn’t flinch. Whether it’s dozens or thousands of pages, it keeps pulling structured data at the same steady pace. That means growth doesn’t come with a bigger headache; it just comes with more data.
Structured, Ready-to-Use Data
Here’s a dirty secret: raw website data is a mess. HTML, tags, layout changes, it’s chaos. A crawler handles that chaos for you. Instead of handing you messy code, a crawler gives you clean data you can plug straight into a dashboard, feed into models, or pass to your analytics team. Less fixing, more using.
Lower Costs, Faster Insights
Every hour your team spends copying, pasting, or debugging scripts is an hour not spent analyzing or acting. By automating, you’re not just saving labor costs; you’re shrinking the time between “something happened” and “we reacted.” And in competitive markets, that time lag often decides who wins the customer.
Trust in Your Data
When the data shows up fast and consistently, you stop second-guessing. No more asking if someone forgot to update a spreadsheet or skipped a site; you just trust what’s in front of you. With a crawler, you know your monitoring is systematic and reliable. That confidence lets you move faster, without double-checking every number.
Key Considerations When Choosing a Content Crawler
Here’s the thing: not all crawlers are created equal. Some look great on paper, but crumble the second you throw real-world complexity at them. If you’re evaluating tools, here are the watch-outs that matter.
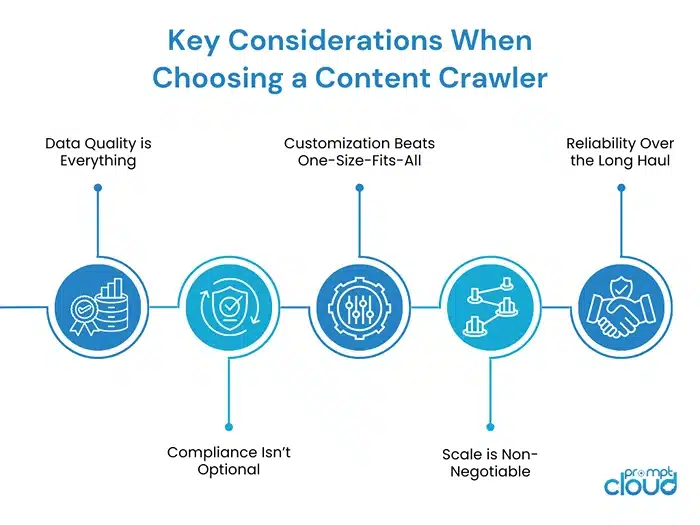
Data Quality is Everything
Imagine you’re tracking competitor prices, and your crawler misses half the listings because it couldn’t handle a dropdown menu. That’s not just a glitch; that’s bad intelligence driving your decisions. A good content crawler doesn’t just grab data; it grabs the right data consistently. Test it on messy, dynamic pages, not just clean ones, and see if the output holds up.
Compliance Isn’t Optional
The line between smart data collection and risky scraping can get blurry fast. The last thing you want is your legal team blowing up your phone because the crawler pushed too hard on a site or ignored its rules. A dependable website content crawler avoids that mess by sticking to the guardrails, things like GDPR, CCPA, and robots.txt, while still giving you the data you need.
Customization Beats One-Size-Fits-All
Off-the-shelf tools can crawl, until you ask them to handle your specific workflow. Need data delivered via API? Want it structured a certain way? Or maybe you’re tracking a niche industry site with odd layouts? If the crawler can’t bend to your needs, you’ll end up hacking workarounds. Look for flexibility, not rigidity.
Scale is Non-Negotiable
It’s easy to crawl 10 pages. It’s a whole other game to crawl 10,000 every day without the system collapsing. A solid crawler is built for scale, distributed crawling, smart retries, and the ability to run around the clock without choking. If a tool promises scale but lags the minute you add volume, you’ll know it’s not ready.
Reliability Over the Long Haul
Here’s a dirty secret: websites change. Constantly. Your crawler should be able to adapt without breaking every time a layout shifts. Otherwise, you’ll spend more time fixing scripts than analyzing data. The best crawlers have built-in resilience, the kind that keeps your data flowing even when the web moves the goalposts.
PromptCloud’s Take on Enterprise-Grade Crawling
Here’s the truth: building and running a crawler at scale sounds simple until you try it. Scripts break. Layouts change. Servers crash under load. Compliance gets tricky. Suddenly, your team is spending more time fixing the crawler than analyzing the data it’s supposed to deliver.
That’s where managed solutions like PromptCloud step in. Think of it less as “outsourcing” and more as plugging into a system that’s already battle-tested at enterprise scale.
- Scale without sweat: We’re talking millions of pages across thousands of websites daily. Our infrastructure is designed for that kind of volume, so you don’t have to reinvent the wheel.
- Customization baked in: Need data delivered via API? Want it cleaned and mapped to your internal taxonomy? Or maybe you need localized crawls for specific markets? The crawler adapts to you, not the other way around.
- Compliance-first approach: With legal frameworks like GDPR and CCPA in play, we’ve built practices that keep crawling above board so you’re never caught in the gray zone.
- Always-on resilience: Websites shift constantly. Our crawlers are built to adjust, which means your data keeps flowing instead of stopping dead the moment a layout changes.
Here’s the kicker: enterprises don’t adopt web crawling services because it’s flashy. They adopt them because it’s the only way to get reliable, structured, real-time web data without burning teams out.
So if you’re evaluating whether to build or buy, ask yourself this: Do you want your analysts spending their days debugging crawlers or using the insights those crawlers are meant to provide?
Stop Chasing Changes. Start Staying Ahead.
The web moves faster than any team can track by hand. Prices drop, competitors pivot, reviews stack up, and breaking news hits while you’re still staring at yesterday’s spreadsheets. Trying to keep pace manually isn’t just inefficient, it’s impossible.
A content crawler changes the game. Instead of chasing changes, you’re watching them in real time. Instead of drowning in messy data, you’re working with structured insights you can act on immediately. And instead of burning your team out fixing fragile scripts, you’re scaling smoothly, across hundreds, thousands, even millions of pages.
Whether you’re in e-commerce, travel, consulting, or publishing, the pattern is the same: automation isn’t a luxury anymore. It’s survival. Enterprises that invest in reliable crawling don’t just save time, they react faster, make sharper decisions, and stay ahead in markets where timing is everything.
Don’t just monitor the web, master it. Schedule a demo and see how real-time crawling keeps you ahead.
FAQs
1. How is a content crawler different from a web crawler?
Think of a web crawler as a tourist wandering through the whole internet, snapping photos of every street for Google Maps. A content crawler is more like a private investigator doesn’t care about every road; it cares about your target: competitor prices, product listings, articles, or reviews. One maps the world; the other brings you the specific evidence you asked for.
2. Can a content crawler really handle complex or dynamic websites?
Absolutely. Modern crawlers aren’t fazed by JavaScript-heavy pages or fancy layouts. If the site loads and a human can see it, a crawler can be taught to navigate it, dropdowns, infinite scrolls, filters, and all. It’s built for the messy reality of today’s web, not just static pages from the 2000s.
3. Is crawling websites even legal?
Here’s the straight answer: yes, when it’s done responsibly. The gray areas usually come from ignoring rules like robots.txt or data privacy laws. That’s why enterprises lean on managed providers; the crawl stays compliant with GDPR, CCPA, and site terms, so you get the insights without the midnight call from legal.
4. How “real-time” are we talking?
Real-time can mean different things depending on your needs. Some teams want hourly checks, others daily. But the point is this: you’re not waiting for someone to manually refresh pages or compile weekly reports. The crawler keeps the pulse automatically, so the moment competitors tweak prices or a new review hits, it’s on your radar.
5. Who actually needs this?
If you’re in e-commerce, travel, consulting, or publishing, you’re already in the game because missing an update means lost revenue or missed opportunities. But truthfully, any business that lives on web data, from fintechs to researchers, benefits. The common thread? If information on the web drives your decisions, a website content crawler keeps you ahead instead of behind.















