


Table of Contents
show
As a DaaS provider, extracting high-quality data from the web for large-scale business requirements has always been our primary focus. Over time, we have equipped ourselves with state-of-the-art technology stack and high-performance infrastructure that can facilitate this with high efficiency. The extensive reach and versatility of our crawling system is something that keeps our clients happy. We’d like to share with you some of the unique value propositions that make enterprises choose us and build a long-term partnership with us. (Some have been with us for more than five years).

Why Our Customers Love Us
Highly Scalable
Big data gets better with its size. The bigger the size of your data sets, the higher your advantage. However, extracting such huge quantities of data requires a robust setup. This is something that sets us apart in the big data game. Our web crawling infrastructure boasts high scalability owing to the dynamic and flexible tools we have integrated along with distributed machines that make complex tasks run smoothly. Since the scale is one of the biggest concerns for most of our enterprise clients, scalability gives us a fair edge in the game.
Vertical Agnostic
As expected from a large scale DaaS provider, our solution is vertical agnostic. It doesn’t matter what industry or domain you need data from, our solution can cater to it all the same. There are several crawling solutions out there that have developed systems that perform well in a particular domain only. The problem with going with such a provider is the chances of getting skewed data. Skewed data refers to the lack of comprehensives resulting from vertical-specific data extraction. However, with our vertical agnostic approach, you get data from any industry vertical with the exact attention to detail that you require.
Fully Customizable
Customization is one of the biggest obstacles when it comes to large-scale web data extraction. Many solutions out there aren’t flexible enough to be adapted to the ever-changing data requirements of organizations. For example, if you were to have a data requirement where one of your inputs keeps changing, we can set up a custom system to fetch your dynamic requirement to be taken in real-time to control the crawls. One example would be when you want to get data for different date ranges. You could update the date ranges on your FTP server and we would perform the crawl by fetching it in real-time. Simply put, our tech stack can be customized to your requirement irrespective of its complexity.
Prompt Support
We understand that prompt and responsive support is essential when something as technically complex as web crawling is the service in question. At PromptCloud, we have dedicated project managers for every client project that we embark upon. Besides having a user-friendly ticketing system where clients can create quick support tickets, they also get to interact directly with the technical team members responsible for doing all the heavy lifting. This eliminates the communication gap to a great extent and helps solve issues within record time.
Low Latency
A lot of projects that we undertake require data with the lowest latency possible. Latency here refers to the time required to fetch new data that was updated in the target site from the time it was updated. This becomes a deal breaker when your data needs are time-sensitive. A good example of this is pricing intelligence. If you’re running an E-commerce portal and using a web crawling solution to get a competitor’s pricing structure, you would want this in minimum latency to be effective enough. Our high-performance machines and the optimal crawling guidelines together make sure that the crawls run smoothly, without any bottlenecks or slowdowns in the lowest achievable latency for a crawler.
Upkeep
Maintenance or upkeep is an essential part of any web crawling project. This is extremely important as the web is highly dynamic in nature. A crawling setup that works today could fail tomorrow even if the target site makes a seemingly small change. This is why we take pride in upkeep as one of our notable advantages. We use dedicated monitoring systems that can track changes in the target sites and send out alerts to notify our tech team to take prompt action. This significantly eliminates the possibility of data loss in the event of something going wrong with the crawls.
Planning to Crawl In-house?
We’ve recently noticed a growing desire in some organizations to take up the difficult road of in-house crawling. There are several reasons why this is a bad idea. For one, in-house crawling would cost you more in the form of hiring expense, infrastructure, maintenance, and time. The real deal-breaker is however the loss of focus that would affect your core business activities. This is because web crawling is a niche process that demands close attention, time, and lots of effort. To give you a better perspective, here are the cost points associated with having an in-house crawling setup.
- Salary of Engineers
- Cost of hardware resources
- Maintenance cost
- Time
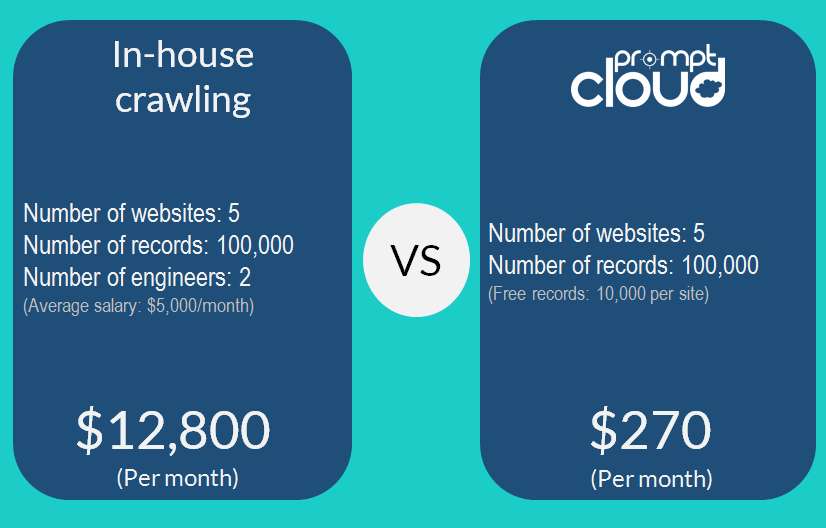
You can use our ROI calculator to compare in-house crawling and our solution.
Why Choose PromptCloud?
You don’t have to take our word on why you should choose our DaaS solution for your web data extraction requirements. We have had several clients who tried in-house crawling in an attempt to cut the costs or availed the services of other providers before reaching out to us. The experiences shared by them reinforce our confidence in our own solution as one of the best ways to acquire data from the web. Here are some snippets from the conversations we had with our clients.
“Other providers that we tried couldn’t handle the complexity of the target site and some important fields were missing.”–Hichem Fadal.
“I have gotten sample CSVs from many of your competitors, and they were extremely poor.”–Daniel Sides.
“On our own, we have tried to crawl this material ourselves. But we find that our efforts are too time-consuming given a large number of resumes, and the computational requirements for speeding up the process is quite challenging. –Robin Quek
Bottom Line
At PromptCloud, we believe in the power of Big data as a business accelerator and understand why our clients reach out to us. This is why we built a system to cater to large-scale requirements that can vary a lot and demand a high level of customization. If you are looking for a web data extraction solution that doesn’t disappoint, it’s time to reach out to us.















