




**TL;DR**
Web scraping at scale is no longer a side project – it’s infrastructure. Enterprises today run thousands of concurrent crawlers across millions of URLs, balancing latency, proxy rotation, and validation while keeping costs and bans under control.
Takeaways:
- Scale introduces complexity – network limits, distributed queues, and memory management.
- Proxies, retries, and headless browsers are essential but need orchestration.
- Observability and schema validation matter as much as data extraction.
- Managed web scraping replaces brittle DIY stacks with reliability and compliance.
What are some prominent Web Scraping Challenges in 2025?
Reality check: what works perfectly for scraping ten pages becomes chaos at a million.
That’s where large-scale web scraping begins – not in code, but in coordination. At enterprise volume, scraping stops being a script and becomes a distributed system. It requires queue management, proxy governance, parallelized rendering, and ongoing validation, all stitched together with observability and fault recovery.
In this article, we’ll break down what makes scraping at scale so difficult, the architectures that can sustain it, and how enterprise-grade managed solutions like PromptCloud handle this complexity so you don’t have to.
Keeping scrapers running shouldn’t take over your week
Get clean, structured web data delivered on your cadence from a managed pipeline built around your specific sources and schema.
The Hidden Challenges of Large-Scale Web Scraping
1. Concurrency Limits and Resource Contention
Common issues include:
- Threads competing for sockets or browser contexts.
- Memory leaks from long-running sessions.
- Race conditions in asynchronous task queues.
Without proper concurrency control: think rate-limited queues and dynamic throttling; you’ll hit diminishing returns instead of higher throughput.
2. Network Instability and Proxy Pool Fatigue
When you scrape at scale, IPs become disposable. Proxy pool challenges include:
- Rotating IPs too fast, triggering CAPTCHAs.
- Reusing IPs too often, causing soft bans.
- Mismatch between proxy location and target region.
The fix isn’t just “more proxies.” It’s about intelligent rotation policies – allocating fresh IPs per session, tagging health metrics, and recycling underperforming endpoints dynamically.
3. JavaScript Rendering Overhead
Modern websites depend heavily on client-side rendering. Every “simple” page request can mean executing dozens of scripts before the data even appears. Running 10 headless browsers is manageable; running 10,000 is not.
Scrapers need:
- Rendering pools that reuse browser contexts efficiently.
- Selective rendering logic that identifies when to render and when to parse static HTML.
- DOM diffing to detect layout changes without full reloads.
4. Rate-Limiting, Retries, and Queuing Logic
Large-scale systems rely on smart backoff strategies. A simplified retry queue looks like this:
| Stage | Condition | Action |
| 1 | Timeout or 403 | Retry with exponential backoff |
| 2 | Repeated block | Rotate proxy + new session |
| 3 | Consistent failure | Escalate for manual validation |
This kind of structured error handling prevents data loss without overloading your infrastructure or the target site.
5. Data Validation and Drift Detection
Scale amplifies small mistakes. A single selector change on one site can silently corrupt terabytes of stored data if it goes undetected. That’s why every large-scale system needs automated validation—schema checks, null detection, and periodic diff-based QA to flag layout drift.
Typical validation rules include:
- Required fields present (title, price, timestamp).
- Field types consistent (string vs. numeric).
- Data within expected ranges (e.g., prices not negative).
When validation fails, the scraper automatically isolates affected jobs and triggers alerts.
6. Observability and Logging
Without observability, large-scale scraping is flying blind.
Teams need structured logging, metric dashboards, and alert systems that track crawler health, latency, and extraction accuracy in real time.
Useful observability metrics include:
| Metric | Description |
| Success rate (%) | Successful scrapes vs. total attempts |
| Error distribution | 403, 429, 5xx ratios |
| Latency | Average response + render time |
| Data freshness | Time between source update and extraction |
Monitoring these metrics helps you identify trends—like when a domain starts blocking you, or when proxies degrade in performance.
The Architecture Behind Scalable Scrapers
When volume grows from thousands of pages to millions, architecture — not code — decides success. A scalable web scraping system must behave like a distributed service: modular, fault tolerant, and self healing. Below is how enterprise-grade systems are structured to handle concurrency, observability, and resilience under pressure, with four internal resources embedded where they add the most value.
1. Layered System Design
The foundation of scalability is separation of responsibilities. Each component manages a single concern: scheduling, fetching, parsing, storing, or validating.
| Layer | Role | Description |
| Controller / Scheduler | Task assignment | Manages job queues and dispatches crawl tasks to worker nodes. |
| Fetcher Pool | Data acquisition | Executes HTTP or headless browser requests with proxy governance and concurrency control. |
| Parser & Normalizer | Data structuring | Extracts fields, validates types, converts to a uniform schema. |
| Storage Layer | Data persistence | Writes clean, timestamped records to databases or warehouses. |
| Monitoring & QA | Health and accuracy | Tracks metrics, error rates, drift detection, and freshness SLAs. |
For a domain focused example of layered design applied to volatile publishers, see How to Scrape News Aggregators which covers deduplication, change detection, and timeline integrity for fast moving feeds.
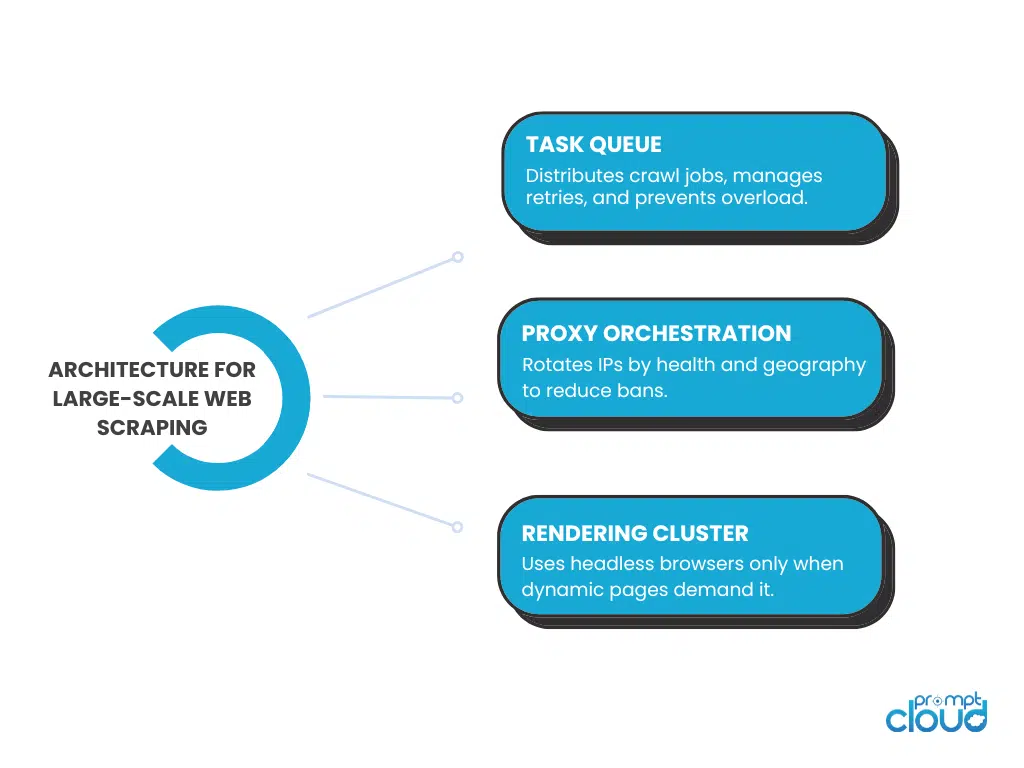
2. Distributed Task Queues
This decouples workload from crawl timing and prevents head of line blocking when a site slows down.
Benefits
- Smooth horizontal scaling across compute clusters
- Built in retry and dead letter queues
- Predictable throughput during volume spikes
News and social workloads are bursty. Queue depth and rate controls are essential when running sentiment pipelines similar to those in Social Media Scraping for Sentiment Analysis where spikes follow events.
3. Proxy Orchestration and Smart Rotation
Proxy management at scale is a strategy problem. A dedicated module tracks proxy health, assigns pools per domain, and rotates IPs using response codes, latency, and ban signals.
| Proxy Strategy | Goal | Outcome |
| Round robin rotation | Avoid reuse patterns | Even distribution of requests |
| Geo mapped pools | Match proxy country to target region | Higher accuracy for localized data |
| Health scored reuse | Prefer stable IPs | Lower error rates and cost |
Automotive marketplaces, for example, often apply regional throttles and variant pages. The rotation and geo mapping approach used in Car Marketplaces Web Scraping Case Study illustrates how per region pools reduce soft bans and missed listings.
4. Rendering Clusters for Dynamic Websites
Modern sites rely on client side rendering. Enterprise scrapers run rendering clusters with Playwright or Puppeteer under Kubernetes to parallelize work while keeping memory predictable.
Each job:
- Loads pages in sandboxed browser contexts
- Extracts DOM or inline JSON once the page is stable
- Tears down the context to release resources
When targets expose JSON endpoints or partial HTML, the system skips rendering to control cost. These selective render rules are vital in real time category trackers like Real Time EV Market Data Scraping where frequent refreshes meet strict latency budgets.
5. Retry, Queueing, and Backoff Logic
Failures are inevitable. Recovery logic decides output quality.
| Retry Attempt | Wait Interval | Action |
| 1st | 2 seconds | Retry the same method |
| 2nd | 10 seconds | Rotate proxy and user agent |
| 3rd | 60 seconds | Switch fetch method to browser render |
| 4th | Escalate | Quarantine job and request manual validation |
This structure prevents cascade failures when a domain starts rate limiting and keeps queues healthy during incident windows.
6. Observability Stack
Large scale scraping without observability is guesswork. Track health, latency, and accuracy with metrics and logs tied to data quality.
Typical stack:
- Prometheus and Grafana for metrics
- ELK for logs and search
- PagerDuty or Slack for real time alerts
Define service level objectives for data freshness, field completeness, and error budgets. For the validation practices that sit under these SLOs, see Data Quality for Scraping.
7. Storage and Delivery Architecture
Persistence and access complete the pipeline.
| Component | Role | Output |
| Data lake | Raw storage | Parquet and JSON |
| Warehouse | Curated tables | Postgres, Snowflake, BigQuery |
| API layer | Programmatic access | REST, GraphQL, Webhooks |
| Export service | Scheduled delivery | CSV, S3, FTP |
Choose batch exports for cost efficiency or streaming for low latency consumers.
8. Human in the Loop QA
Automation handles the 99 percent case. Human review protects the one percent that breaks quietly. Analysts validate critical feeds after major template changes, confirm selector updates, and review anomalies before they reach production dashboards.
How these links fit the reader journey
- Readers who need publisher scale patterns will drill into the news aggregators guide.
- Teams building social sentiment pipelines get queueing and rate control context from the social post.
- Category managers working with regional marketplace data can borrow proxy rotation and geo mapping tactics from the car case study.
- Operators who must refresh fast moving SKUs can see selective rendering and low latency choices in the EV market post.
Smarter Alternatives to DIY: Managed Large-Scale Scraping
At a small scale, building your own scraping system is manageable. At enterprise volume, it’s an operations problem. When you’re juggling proxies, rendering clusters, data validation, and compliance reviews, scraping shifts from a technical task to an ongoing infrastructure cost.
That’s why leading organizations are now migrating from DIY crawlers to managed scraping services that deliver fully validated datasets under SLA. Instead of maintaining fragile infrastructure, teams focus on applying insights; not fixing broken scripts.
1. The Real Cost of Doing It Yourself
| Cost Driver | Description | Impact |
| Engineering Time | Maintaining scrapers, schedulers, and parsers. | Weeks lost each quarter to refactoring. |
| Proxy Management | Renewing IP pools, tracking bans, monitoring rotation. | Unpredictable and expensive. |
| QA & Validation | Schema drift checks, null filters, manual sampling. | Requires dedicated analysts. |
| Compliance & Legal Risk | robots.txt adherence, GDPR, data lineage. | Significant audit overhead. |
What begins as a quick prototype often evolves into a full-time data operations headache. As data volumes grow, even small inefficiencies multiply.
2. Managed Scraping as a Service
Managed scraping platforms take ownership of infrastructure, compliance, and QA. You define your target data, update frequency, and delivery format—everything else is automated.
Advantages:
- Fixed-cost model without proxy or hosting surprises.
- Validated, schema-consistent output on schedule.
- Instant recovery when site structures change.
- Governance-ready audit trails for each domain.
- Dedicated support and real-time performance monitoring.
The result is a predictable data supply chain, not an experimental setup.
3. Scalability Without Fragility
Enterprise-grade managed systems use containerized renderers, distributed task queues, and adaptive retry logic. Jobs scale horizontally across infrastructure, with active load balancing and proxy health scoring to minimize bans and latency.
A 2025 AIMultiple report on data engineering automation found that organizations outsourcing their web data operations reduced failure rates by over 40% while improving dataset delivery speed by 1.6x.
Those gains come not from volume, but from stability.
4. Observability and Data Quality as Guarantees
A managed pipeline isn’t a black box; it’s transparent. Teams can monitor crawl health, schema coverage, and delivery freshness through structured dashboards. Every dataset includes metadata like:
- Fetch timestamp and latency
- Field-level completeness scores
- Validation and retry logs
- Source change tracking
This visibility makes compliance and analytics teams equally confident in the integrity of their data.
5. When Managed Makes More Sense
| Scenario | DIY Setup | Managed Solution |
| Dozens of domains | Multiple scrapers and cron conflicts | Centralized orchestration |
| Frequent updates | Manual rescheduling | Event-triggered streaming |
| Regulated data | Ad-hoc compliance tracking | Automated legal vetting |
| Data consumers | Fragmented output | Unified feed with documentation |
For most enterprise teams, managed scraping isn’t outsourcing; it’s optimization. It turns brittle web crawling into a repeatable, measurable data operation.
Operational Excellence at Scale
At the 10-million-page mark, scale becomes a process discipline rather than a software problem. The teams that sustain large-scale scraping long term treat it like DevOps — measurable, automated, and observable.
1. Continuous Monitoring Instead of Periodic Fixes
Most DIY projects rely on “if it breaks, fix it.” Enterprises need proactive monitoring. The key is to collect metrics at every stage: crawl latency, parser failure rate, schema drift, and freshness delay.
| Metric Type | Example | Target Behavior |
| Crawl Health | Success rate > 98% | Alert when retries exceed threshold |
| Data Drift | Schema change detection | Automatic selector revalidation |
| Latency | < 3 sec per request | Auto-scale rendering pool |
| Freshness | Updates < 24 hrs old | Trigger rescrape automatically |
By automating these checks, large operations reduce manual oversight while maintaining constant visibility.
2. Version Control for Data Pipelines
Source code versioning is standard; data pipeline versioning isn’t — but it should be. Every crawler, selector, and schema should have a unique version tag. When a site layout changes, the system increments its schema version and logs which records were affected.
This creates full lineage traceability, allowing compliance officers or analysts to reproduce any dataset exactly as it appeared on a given date. In financial or retail environments where decisions rely on historical data, this traceability protects both credibility and auditability.
3. Fail-Fast Culture and Feedback Loops
The most successful scraping programs adopt a fail-fast mindset.
Rather than letting silent errors accumulate, they implement:
- Early anomaly detection: Compare live output to expected field counts.
- Automated quarantine: Remove suspect batches from delivery pipelines.
- Continuous feedback: Engineers receive structured error summaries daily.
This keeps drift from turning into data debt and ensures stakeholders always work with clean, verified records.
4. Security and Access Controls
Data at scale is valuable — which makes security non-negotiable.
Scraped datasets often contain commercial intelligence, so enterprises enforce strict:
- Role-based access controls (RBAC)
- Encrypted storage (AES-256)
- Signed data transfers (HTTPS/SFTP)
- Activity logs and alerting for unusual download behavior
PromptCloud’s managed architecture applies the same security posture used in production SaaS systems, ensuring customer data feeds remain isolated, encrypted, and auditable.

Future Architecture: Serverless and Event-Driven Scraping
The next evolution of large-scale scraping is serverless orchestration—systems that allocate compute only when events occur. This approach replaces constant resource allocation with event-driven triggers that scale dynamically.
1. How Serverless Changes the Economics
Traditional scraping clusters are “always on.” Even idle workers consume compute hours.
Serverless platforms spin up crawlers only when needed, completing a job and shutting down instantly.
This model:
- Reduces cost per crawl by eliminating idle time.
- Enables per-event billing, aligning spend with usage.
- Simplifies scaling during news bursts or seasonal demand peaks.
2. Event-Driven Triggers
Imagine a workflow where scraping begins automatically when:
- A new product appears in a sitemap.
- A keyword trend exceeds a defined threshold.
- A competitor updates their investor FAQ page.
Event triggers link the data-need moment to the collection moment, reducing lag between insight and action.
3. Observability in Serverless Environments
Monitoring serverless jobs differs from cluster logging. Since functions are ephemeral, you need centralized telemetry:
- Capture execution metrics (duration, errors, memory) in external observability tools.
- Aggregate logs per crawl session for historical reference.
- Retain success/failure counts for cost forecasting.
This visibility allows teams to measure cost-per-record, a metric increasingly used by enterprise data teams to benchmark vendor efficiency.
4. Integrating Scraped Data with AI Pipelines
Modern organizations rarely use scraped data in isolation. Large-scale scraping now fuels:
- LLM fine-tuning — feeding structured datasets to domain-specific models.
- Real-time RAG (Retrieval-Augmented Generation) — updating knowledge bases with live web data.
- Predictive analytics — combining pricing, review, and trend signals.
For example, combining web-scraped automotive listings with charging-infrastructure data enables EV sales forecasting in real time. This fusion of structured web intelligence and AI modeling defines the next generation of competitive analytics.
5. Vendor Selection and Performance Benchmarks
When evaluating managed scraping providers, enterprise data leaders increasingly benchmark on five quantifiable metrics:
| Evaluation Metric | Ideal Benchmark | Why It Matters |
| Success Rate | ≥ 98% | Measures reliability of extraction pipelines. |
| Latency | ≤ 5 sec per request | Affects freshness of time-sensitive data. |
| Schema Drift Response | < 24 hrs | Determines agility when site layouts change. |
| Compliance Documentation | 100% coverage | Required for regulated sectors. |
| Audit Log Retention | ≥ 90 days | Supports traceability and SLA enforcement. |
Managed systems that meet or exceed these thresholds consistently outperform DIY setups in both cost efficiency and reliability.
6. The Future: Data Feeds, Not Crawlers
The ultimate trajectory of large-scale web scraping is clear: From scripts to feeds. Instead of running and maintaining crawlers, enterprises will subscribe to topic-based or category-based feeds that deliver continuously refreshed, normalized datasets—ready to plug into analytics or LLM workflows.
These feeds won’t just provide data; they’ll come with contextual metadata, quality metrics, and compliance logs by default. For most enterprises, this is the endgame; where web scraping becomes invisible infrastructure, delivering insights as effortlessly as cloud storage delivers files.
Keeping scrapers running shouldn’t take over your week
Get clean, structured web data delivered on your cadence from a managed pipeline built around your specific sources and schema.
FAQs
1. What qualifies as large-scale web scraping?
Large-scale web scraping refers to extracting data from thousands or millions of URLs in a coordinated, distributed way. It involves parallel crawlers, proxy pools, rendering clusters, and monitoring systems that can handle concurrency, retries, and validation automatically. At this level, scraping becomes infrastructure, not just a script.
2. Why do small scrapers fail when scaled up?
Most scripts aren’t designed for concurrency, memory limits, or proxy fatigue. When you multiply requests, tiny inefficiencies—like unclosed browser sessions or slow parsing—grow into full-scale failures. Without queueing, rate control, and observability, even a simple job can overload servers or get IP-banned within minutes. Large-scale systems use task queues, adaptive throttling, and distributed monitoring to stay stable under load.
3. How do enterprises ensure compliance at scale?
Compliance starts with responsible sourcing: scraping only public, non-authenticated data, respecting robots.txt, and documenting every access pattern. Managed providers maintain audit trails, schema versions, and GDPR-aligned data handling practices. Each dataset includes metadata—timestamp, source, and validation logs—so legal and compliance teams can verify lineage at any time.
4. What technologies power scalable scrapers?
Enterprise pipelines typically combine:
Distributed message queues like RabbitMQ or Kafka for orchestration.
Containerized headless browsers (Playwright, Puppeteer) managed by Kubernetes.
Proxy orchestration engines for rotation and geolocation.
Observability stacks such as Prometheus, Grafana, or ELK for live telemetry.
Validation frameworks for schema and freshness checks.
Together, these tools create a self-healing, observable data service rather than a set of ad-hoc scripts.
5. When should a company switch to a managed web scraping solution?
The tipping point usually arrives when internal teams spend more time fixing crawlers than analyzing results. If uptime, compliance, or cost predictability matter, managed scraping delivers higher ROI. Providers like PromptCloud offer SLA-backed pipelines with full QA, proxy management, and freshness guarantees—removing maintenance headaches while ensuring the data remains accurate and audit-ready.















