



The Future of AI lies in The Hands of Quality Data
Sounds a little absurd doesn’t it? Shouldn’t the future lie in the hands of man? But if you look at the growth of Machine Learning and Artificial Intelligence, you will be able to spot that the latest innovations have piggybacked on the massive amount of data that are generated by humans and machines today. The growth of neural networks and deep learning algorithms that are being used in the latest innovations such as self-driving cars and natural language processing has only been possible due to the growth in the quantity and quality of data. When you have lesser data, almost all AI algorithms produce similar results, but when you have Petabytes of data, you can see the deep learning algorithms shine.
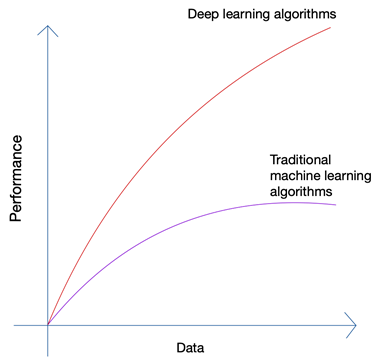
Humans can only produce a limited quantity of data, and the big data revolution was caused mainly due to more and more devices connecting to the internet and producing more data. The IoT revolution has produced more data than ever before. No human can parse through such enormous data, which in turn led to the foundations of deep learning.
The Three Main Issues with Data
Quantity is not the only issue when you are gathering data for your cutting edge AI project. No matter how much data you have, the quality, cleanliness, and variety of the data matter just as much if you want the best results from your algorithm.
a). Quantity
If you are trying to create an algorithm for autonomous cars with only a few thousand rows of data, you are bound to face roadblocks. To make sure that your algorithm produces proper results in real-world scenarios, you need to train your algorithm on tons and tons of training data. Thanks to the ability to access logs from almost any device today along with the almost infinite stream of data from the web, gathering data are not very difficult; as long as you have the right tools and you know how to use them.
b). Variety
When you are training your algorithms to tackle real-world problems using AI, your system needs to understand all the possible variety of data points possible. If you are not able to get a variety of data, your system will have an inherent bias and produce incorrect results.
Such has happened multiple times, including the famous 1936 Presidential Poll held by The Literary Digest in the USA. The candidate that it had predicted would win the presidential race, ultimately lost by a massive margin of more than 20%. However, the magazine had polled 10 million individuals, of which 2.27 million had responded— an astronomical number even by today’s standards. Where had things gone wrong?
Well, they had failed to understand the sentiments of the much larger percentage of readers who simply did not respond along with those who could not afford to subscribe to a magazine when the country was at the depths of a great depression.
c). Quality
While the last two factors are really important and can be kept a check on with some efforts, data quality is easier to miss and difficult to detect even when your results don’t match up. The only way you can know that the data was unclean is if you analyze the data again after it has gone into production.
Some simple ways to maintain the quality of data is to remove duplicates, validate the schema of each row that comes in, have certain hard limits to keep a check on values that enter each row, and also keep track of outliers. If certain factors cannot be kept in check via automation, manual interventions may also be necessary. A major point where errors can creep up is data conversions. Especially when you are accumulating data from multiple sources, not all data points would have the same units. Converting the values using the proper equations is a must, and needs to be implemented across the board.
Data that is scraped from the web may also consist of structured, semi-structured, and unstructured data, and when you want to use these different forms of data in your AI project, you will need to make sure that you convert all of them to the same format.
How does Data Quality Impact AI Projects?
Data quality can impact any machine learning or AI project. Depending on how vast the project is, even simple mistakes in the data can lead to results that are off by a long shot. In case you are creating a recommendation engine, and your training data is not clean enough, the recommendations will not make much sense to the users.
However, getting hold of whether unclean data has played a part in this outcome may be difficult. Similarly, if you are designing a prediction algorithm and the data has certain flaws, some predictions may still hold good while some may be quite a bit off. Connecting the dots to realize the difference that dirty data has brought may be extremely difficult to recreate.
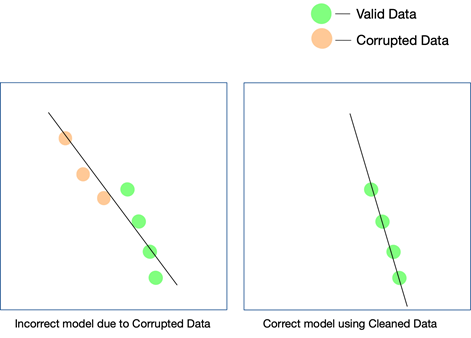
Every AI project grows in phases. An initial algorithmic decision is made— that is which algorithm would work best given the dataset and the specific use case, is decided. If your data has inconsistencies, your choice of the algorithm itself may go for a toss, and you may not come to realize this fallacy until long after.
The only way to ensure that your model works in the real world is to ensure clean data is fed to the AI system and to keep testing it on more and more data. You can also use reinforced learning to correct the model’s path when it strays away.
Can Web Scraping be the Solution?
Web scraping can be a solution, but only if it is used in combination with several other tools to make sure that the variety and quantity of data that comes through the pipeline are thoroughly cleaned, verified, and validated before being used in a project. Even if you are using a web scraping tool, be it in-house or a paid software, to get data from the web, it is unlikely that the tool will be able to perform these post-processing tasks on the data to make it ready to use.
What you will need is an end to end system that takes care of scraping the data, cleaning it, validating it, and verifying it, such that the final output can be directly integrated into business workflows in a plug and play format. Building such a system from scratch is as difficult as climbing the mountain starting from its base.
Our team at PromptCloud provides web scraping service – that is you give us the requirements, and we give you the data, the DaaS (Data-as-a-Service) model. All you need to do is access the data (which will be in the format and storage medium of your choice), and integrate it with your current system. We not only scrape the data from multiple websites but use multiple checks at various levels to make sure that the data that we provide is clean. This data helps empower our clients in various sectors to use cutting edge technologies like AI and machine learning to make streamline different processes and understand their customers better.















