



Carly Fiorina, the former CEO of HP, aptly said “The goal (of any organization) is to turn data into information and information into insight.”
With the tremendous surge of data on the internet via mobiles, social media, and the proliferation of websites, there are big chunks of data waiting for you to be noticed irrespective of the domain you belong to. There are forums to keep a tab on, there are reviews to analyze in order to maintain your feedback channels, and there’s a lot of competitive data in the form of competitor websites and social pages to feed into your marketing efforts.
However, to capture essence of all of this Big data for your business, it needs to be structured. But owing to no standard data formats on the web, of 5.2 zetabytes of data on the internet, only 25% of it is structured. So what exactly is structured and how does it differ from unstructured data?
Here’s a formal definition from Gartner- “Gartner defines unstructured data as content that does not conform to a specific, pre-defined data model,” writes Gartner’s Darin Stewart. “It tends to be human-generated, and people-oriented content that does not fit neatly into database tables.”
Let’s take an HTML page on Amazon as displayed by any browser. That’s unstructured data (note- HTML is still structured or semi-structured, but it’s the rendering that takes away the structure).
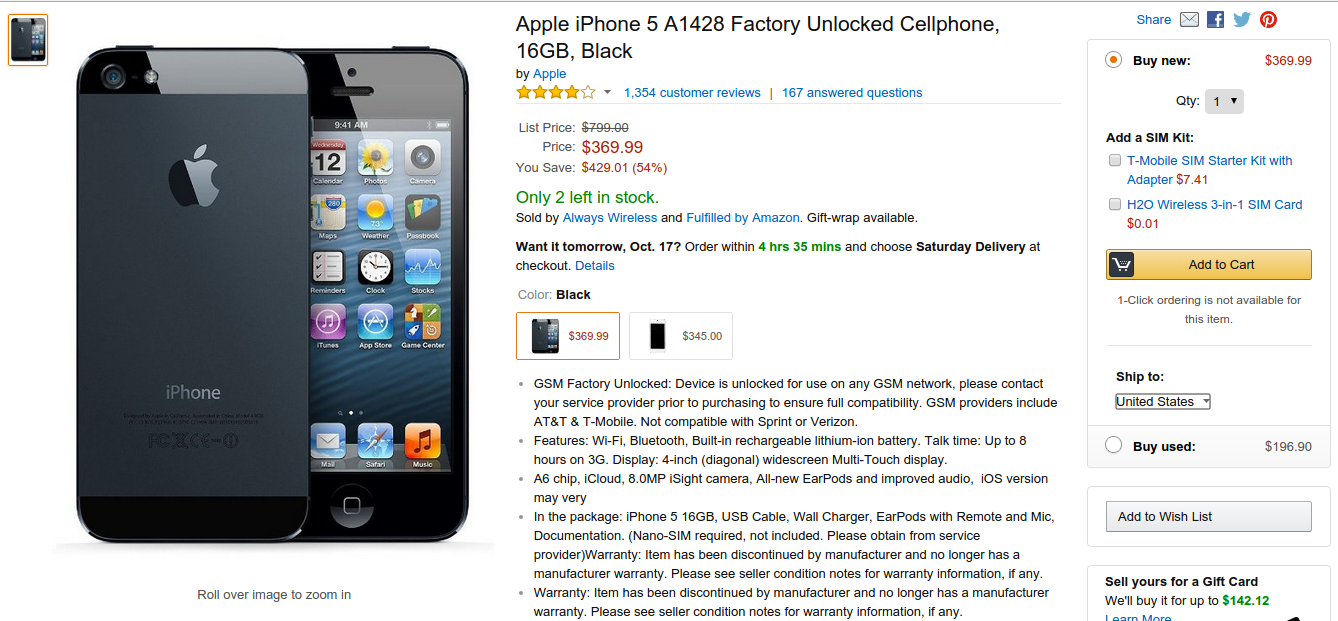
Unstructured because all of this data is only designed for humans to read and process. By looking at the page, you can easily differentiate between the product specifications and the images but can’t expect the same of your machines.
Now look at this same product in the following XML snippet. Each data point is clearly tagged, and it’s easy to entitize each record encapsulating all these data points. That, simply put, is structured data.

The above example is self-explanatory of the lucid difference between structured and unstructured data.
In the context of web, unstructured datasets as displayed on the browser are not machine-ready enough to acquire them at scale, process them into a format that conforms to your relational database, import them into your database tables and later run queries to derive analyses. For that to happen, you need to convert the data in your database-friendly schema i.e. handpick the details you want (like product name, description, price, promotion, etc.) from a page like above, and tag them against their respective field into a format (XML,CSV,JSON, XLS) so that your database can easily read and parse. That, in essence, is structuring of data, also technically known as extraction or scraping of data in the web lingo.
Extraction of data from the web is an equally challenging task as is crawling the web pages at scale. It’s no surprise hence that a lot of effort in the Big Data industry these days is directed towards dealing with the unstructured challenge while acquiring large datasets from the web.















