




How to track changes in Google Docs, RSS feeds have revolutionized the way we stay connected to the websites that matter to us. With feeds, you don’t have to keep checking each of your favorite sites separately as it brings all the news from these sites together at one place – your feed reader. The feed reader takes care of the task of aggregating content from different sites silently, behind the scenes.
Unfortunately, all the websites out there do not provide a feed. For example, imagine you want website changes tracking on an Ecommerce site. Popular Ecommerce portals like Amazon and eBay don’t have RSS feeds that you can subscribe to and stay updated. If you want to track the price of a product that you’ve been thinking of buying when the price goes down, you would have to manually check the product page from time to time. This is not a convenient solution. But we have a solution to this problem and it makes use of Google docs, something that we’re all familiar with already. Make sure you also have a look at our previous Part 1 article on web scraping using Google Docs.
Track Changes in Google Docs
Example problem: Let’s assume you are looking to buy the iPhone 6S. The easiest way to get a rough idea about the price for iPhone 6S across various Ecommerce portals would be to search for ‘iPhone 6S’ on Google. In case the prices don’t look exciting, you would have to repeat this search the next day. Now imagine having to do this for 10 different products on 3 different Ecommerce sites. Sounds like a tiring task, and it obviously is.
Solution: An easy solution to this problem would be to build a Google docs spreadsheet that can monitor prices of different products on these search pages and have it fetched in a document. This enables you to not just track the pricing changes, but also compare them at the same time.
Getting Started
To get started with this handy method, all you need is access to Google docs and some know-how of XPath. If you’re wondering, XPath is an easy way to access data contained in HTML pages. For example, if you want to see all the links present on a given webpage, the XPath expression would be //a[@href].
Examples
//strong denotes items on a page with strong html tags
//@href denotes items on a page with the href element
Not that difficult at all.
Track Changes in Google Docs ImportXML and XPath Functions
This is the Google products search results page for ‘iPhone 6S’. If you check the source code of this page, you will find that titles of the results are using the class name “pstl” and prices are using the class name “price”.
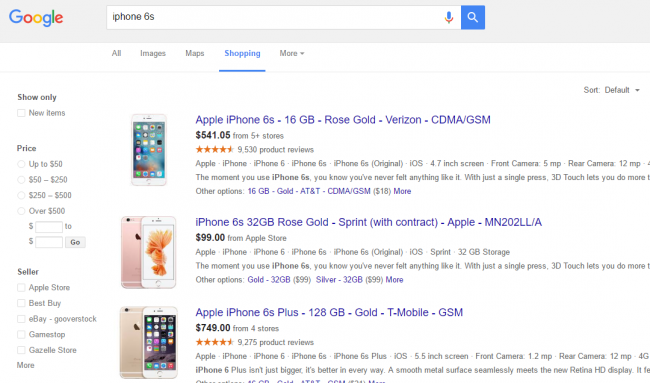
We should now create a table inside the Google sheet with the name, price and URL that would be linked to the product listing.
After creating the table, the syntax for extracting data should be entered into the cells to populate them with the data.
Here is the syntax =ImportXML(“web page URL”, “XPath Expression”)
All you have to do now is to add the respective syntax for fetching required data into their fields in the table that we just created.
This is how the final sheet would look like – this data is live and will get updated automatically as the actual product listing changes on the web. The same approach can be used to crawl product data from sites like eBay, Amazon or any other shopping site.
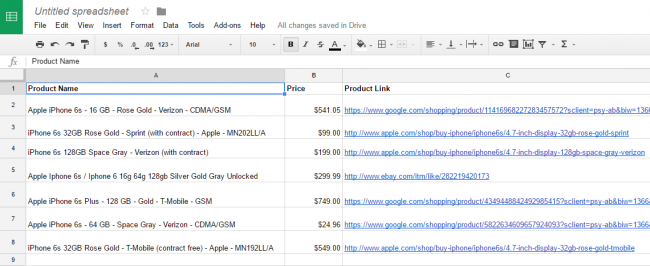
This sheet will update automatically and you can track changes in google docs on a website that goes on in the source websites in the form of price, title or URL. You can also add more data points depending on your requirements.
In Summary
Google docs is a powerful tool with dynamic capabilities. Scraping data from websites and track changes in google docs to a website them is one such great function that we can carry out using Google docs. Since web scraping is becoming a necessary skill for various use cases in business, learning this method will definitely help you along the way.















