




**TL;DR**
AI systems break when teams cannot explain where their data came from, how it changed, or why certain results appeared. Data lineage and traceability frameworks solve this by recording every step in the flow from raw extraction to model consumption. These frameworks make provenance visible, transformations auditable, and outputs reproducible. This blog explains the components of a lineage-driven pipeline and shows how traceability supports compliance, data governance, and AI reliability. You will see how enterprises use lineage to create stable models, safer audits, and cleaner change histories.
What is a Data Lineage Framework?
Most teams worry about model accuracy, freshness, schema quality, or labeling standards. Fewer teams worry about something far more fundamental. Models fail quietly. Audits become stressful. Reproducing results feels impossible. And when the underlying data shifts without warning, no one can point to the exact moment it happened.
This is why data lineage matters. It is the map of your data’s journey. It shows every source, every transformation, every validation step, and every point where a decision or correction occurred. Lineage gives you memory. Traceability gives you proof. Together they create a data environment where nothing is mysterious and every output can be explained.
AI pipelines amplify the importance of these ideas. Web data changes frequently. Extraction logic evolves. Schemas grow. Validation rules update. Even small adjustments ripple through models in ways that are easy to miss. When you track lineage well, none of this becomes a surprise. You can replay a training job, compare models across versions, audit compliance requirements, and understand exactly why an AI behaved the way it did.
Think of this article as your guide to building traceable, reproducible, enterprise grade AI pipelines.
Why Data Lineage Is Needed for AI Pipelines
Data lineage is not a governance checklist item. It is a practical requirement for anyone building AI systems that rely on dynamic or multi sourced data. A simple way to understand its value is to look at where things tend to break.
First, models drift without warning.
Second, debugging becomes slow.
Third, audits become painful.
Fourth, reproducibility becomes unreliable.
Lineage gives clarity by answering questions that matter.
- Where did this record originate
- Which transformations were applied
- Which validation rules passed or failed
- Which version of the schema or crawler was used
- Which dataset version fed the model
When these answers are visible, AI pipelines become predictable. You can test new training runs with confidence. You can audit changes without stress. You can update extraction logic without accidentally breaking downstream models.
Many organizations begin web scraping with internal scripts, but maintaining crawler infrastructure, handling anti-bot protections, and monitoring data quality quickly becomes a full-time operational task.
The Four Layers of Data Lineage
Lineage often feels abstract until you break it into layers.
Table 1
| Lineage Layer | What It Captures | Typical Questions It Answers |
| Source | Where the data originated and how it was collected | Which website, feed, or API did this record come from |
| Transformation | How the data was cleaned, mapped, merged, or filtered | Which rules changed this value and when did that happen |
| Storage | Where the data was stored and in what structure | Which table, bucket, or index holds the current version |
| Consumption | Which jobs, models, or reports used the data | Which model version or dashboard relied on this dataset |
Source layer
This is the entry point. For web data, the source layer tracks the target site, endpoint, or API path, along with crawler configuration, proxy pool, and schedule metadata. If an issue appears, you can immediately see whether it originated from a specific marketplace, region, or crawl job.
Questions you should always be able to answer here:
- Which crawler executed this run
- Which robots rules and collection policies applied
- Which time window and geography did the data cover
Transformation layer
This is where most bugs hide. You should know:
- Which transformation produced this field
- Which validation checks ran on this batch
- Did any records get dropped or corrected along the way
Storage layer
You should know:
- Which table or path contains this record
- When this partition was last updated
- Which retention or compaction rules apply
Consumption layer
Finally, data flows into training jobs, dashboards, APIs, and downstream services. Lineage at this layer ties a model run or report back to a definite dataset version. That link is essential for reproducibility.
Here you answer:
- Which dataset powered this model
- Which model version served this prediction
- Which business process or UI consumed the output
When all four layers are visible, you can trace any anomaly from the user facing symptom back to the original source. That is the core promise of lineage. It turns “something broke somewhere” into a clear, navigable trail.
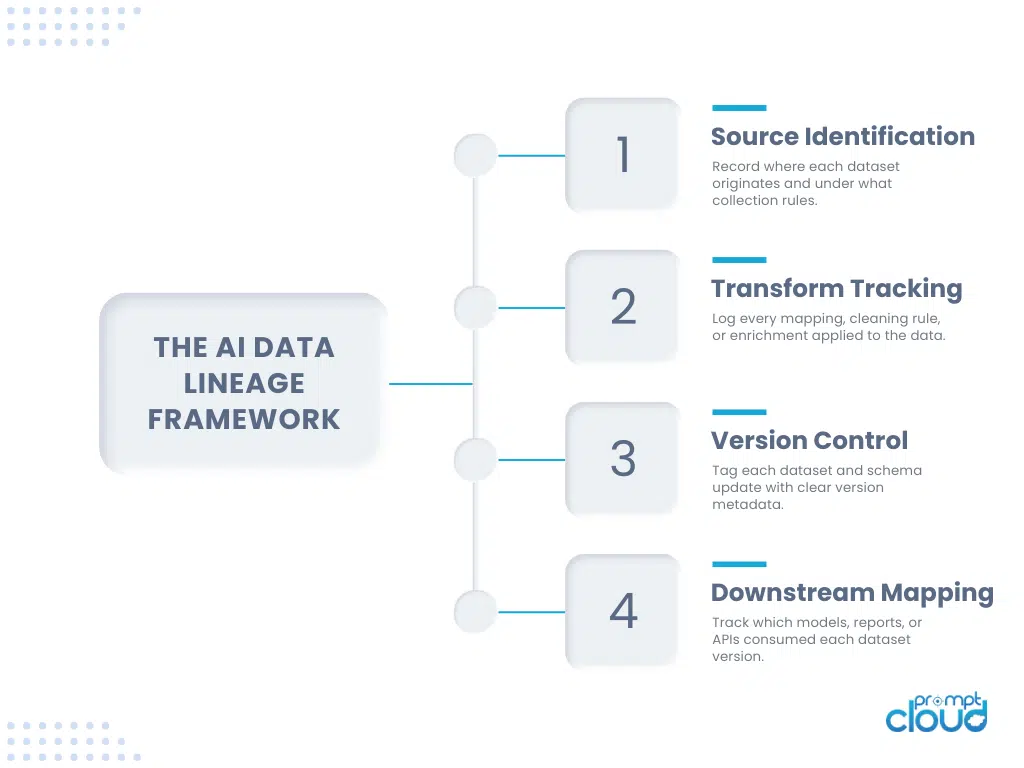
Figure 1. High level view of an AI data lineage framework from source identification to downstream consumption.
Designing a Traceability Framework for Web Data Pipelines
Traceability is the operational side of lineage. If lineage tells you the story of your data, traceability makes sure that story can be verified, audited, and repeated. A strong traceability framework helps teams move beyond loose documentation and gives them concrete, machine readable evidence of how their data evolved.
A good framework is not complicated. It simply records the right things at the right time. You can think of it as three questions you must always be able to answer.
- What exactly happened
- When did it happen
- Why did it happen
If your system can answer these three consistently, you have operational traceability. A practical framework usually includes the following components.
Component one: Event level logging
Every meaningful change in the pipeline should produce a log entry.
What this unlocks: You can replay any event and understand how a value entered or exited the pipeline.
Component two: Transform history tracking
Transformations do not exist until they are tracked. A traceability system stores the exact version of the transformation script, enrichment rules, or mapping logic that touched each batch. This allows you to reproduce any intermediate version of the dataset.
What this unlocks: You can compare multiple runs and spot which transformation introduced divergence.
Component three: Dataset versioning
Each output dataset should have a clear version number. When combined with timestamps and lineage metadata, versioning allows teams to rebuild any snapshot of the data and align it with specific model versions.
What this unlocks: Full reproducibility across training and evaluation cycles.
Component four: Compliance and audit markers
Compliance logs record whether sensitive fields appeared, whether privacy rules applied, and whether retention windows were respected. These markers become vital during enterprise or regulatory reviews.
What this unlocks: You can answer audit questions without reconstructing your pipeline manually.
Component five: Run level metadata
Every batch should carry metadata such as crawler settings, proxy pool used, user agent, schema version, validation results, and error counts. When issues surface, run level metadata lets you pinpoint anomalies quickly.
What this unlocks: Fast diagnosis without hours of manual inspection.
Table 2
| Feature | What It Tracks | Why It Matters |
| Event Logs | Job runs, failures, updates | Enables reconstruction of the pipeline timeline |
| Transform History | Scripts, mappings, enrichment rules | Shows exactly how data changed |
| Dataset Versions | Output snapshots | Supports reproducibility and rollback |
| Audit Markers | Compliance and privacy indicators | Makes external audits easier |
| Run Metadata | Configuration and environment details | Simplifies debugging and anomaly detection |
A good traceability framework does not slow teams down. It keeps them safe. It makes decision making cleaner. It supports compliance without friction. And it gives AI models a stable foundation by ensuring every training run is backed by a verifiable record.
When traceability becomes standard, data engineering and AI development feel less like guesswork and more like controlled, repeatable operations.
Visualizing Lineage: How Teams Make It Actionable
Most teams do not struggle with collecting lineage metadata. They struggle with using it. When lineage sits in logs or metadata tables, it is hard to act on. Visualization turns lineage from a record into a tool. Clear visuals help teams see how data moved, where it branched, which transformations applied, and where errors originated. A visual map is usually the fastest way to debug, audit, or validate any dataset flowing toward an AI pipeline.
A good lineage visualization answers three simple questions at a glance.
- Where did this data start
- Which steps did it pass through
- Where did something unexpected happen
When those answers are visible in a single view, lineage becomes a practical asset rather than a background process. Teams usually use three types of lineage views.
View one: Linear flow view
This shows the straight path of a dataset from source to consumption. It is the simplest representation and works well for pipelines with predictable transformations.
Best for: Debugging step by step failures or validating simple workflows.
View two: Branching dependency graph
This view reflects real world pipelines where transformations branch, enrich, merge, or filter data. Dependency graphs show which tables, scripts, or services feed into the final dataset.
Best for: Spotting upstream issues that affect downstream jobs.
View three: Temporal replay view
This view allows teams to rewind a dataset to a specific point in time and compare versions. It is especially helpful when investigating drift, schema changes, or unexpected model outputs.
Best for: Reproducing experiments and supporting compliance audits.
Table 3
| Lineage View | What It Shows | Why Teams Use It |
| Linear Flow | Sequential steps from input to output | Fast debugging and onboarding |
| Dependency Graph | Branching paths and upstream dependencies | Impact analysis and root cause detection |
| Temporal Replay | Snapshots across time | Reproducible experiments and audit readiness |
Visualizing lineage helps teams understand not just what happened but how it happened. It exposes hidden bottlenecks, failing transformations, unexpected schema changes, or slow moving pipelines. It also shortens investigation time dramatically. Instead of parsing logs, teams can scan a visual trail and pinpoint the root cause in minutes.
Once lineage becomes visual, it becomes actionable. Engineers fix issues faster. Analysts trust the data more. Compliance teams feel confident. And AI models gain a level of transparency that is difficult to achieve in any other way.
Operationalizing Data Provenance for Compliance and Risk Management
When you operationalize provenance, it becomes more than a log. It becomes a compliance asset. Regulators want proof of collection methods, retention decisions, transformation logic, and privacy safeguards. Enterprises want clarity when something goes wrong. AI teams want a stable reference for debugging. Provenance ties all of this together.
The key idea is simple. Every piece of data should carry its own history.
To make provenance practical, teams weave it into standard workflows rather than treat it as separate documentation.
First, capture provenance at ingress.
Record the site, endpoint, and collection policy for each batch. Include timestamps, user agents, crawl settings, and any rules applied for filtering or throttling. This ensures you can always explain how the data entered the system.
Second, attach provenance to transformation steps.
Each change should include the script version, validation results, and any enrichment sources used. If a value was corrected, dropped, or inferred, that information should travel with the dataset.
Third, enforce retention and visibility rules.
Provenance helps you respect privacy constraints by making it clear which fields came from which source and how long they should remain stored. When retention windows expire, you know exactly what to purge and why.
Fourth, use provenance in risk assessments.
If a model shows odd behavior, provenance reveals whether the cause was a faulty crawl, an outdated mapping rule, or a transformation issue. This reduces investigation time and lowers the chance of making unnecessary changes.
When provenance becomes embedded into your pipeline, compliance feels less like a burden and more like a natural side effect of good engineering. Teams gain confidence. Auditors gain clarity. Models gain stability. The whole data stack becomes safer.

Figure 2. Practical traceability checklist covering ingress logging, change monitoring, audit evidence, and reproducibility.
Building Reproducible AI Pipelines with Lineage as the Backbone
Even small inconsistencies produce large differences in model behavior. Lineage is what stabilizes this entire process. It becomes the backbone that lets you repeat experiments with confidence. A reproducible pipeline usually follows a simple philosophy. If you cannot trace it, you cannot trust it. If you cannot trust it, you cannot repeat it. To make reproducibility real, teams embed lineage into each major stage.
Start with versioned datasets.
Every dataset used for training should have a unique version number. When combined with timestamps and provenance metadata, you can always rebuild the exact dataset used for a specific model. Without dataset versioning, reproducibility becomes guesswork.
Track transformations rigorously.
If a model was trained on data processed through a specific mapping script, you should know which version of that script ran. If validation rules changed between runs, the lineage trail should show that. This eliminates hidden differences that distort comparison.
Log model runs and connect them to dataset versions.
A training job should always record which dataset version it used, which hyperparameters applied, and which environment configuration was active. Lineage creates a link between input data, model logic, and output metrics. With these links, you can compare models in a structured way rather than relying on intuition.
Ensure that experiments can be replayed.
Reproducibility is not only about storing metadata. It is about being able to re-execute a training job, re apply transformations, and re generate predictions. Lineage gives you the ability to rewind your pipeline to any moment and repeat the process.
Use lineage to prevent silent drift.
Silent drift happens when a pipeline changes its behavior without explicit updates. A source adds new attributes. A parser breaks. A validation rule shifts its threshold. Lineage surfaces these changes early so your team can intervene before they reach the model.
When lineage becomes the backbone of your AI pipeline, reproducibility stops being a challenge and turns into a habit. Teams can experiment more confidently. Stakeholders trust results more easily. Models stay more stable over time because every run is backed by a clear record of what happened, when it happened, and why the outcome looks the way it does.
The Business Value of Lineage: Governance, Trust, and Scale
Lineage is often framed as a technical safeguard, but its biggest impact shows up on the business side. When leaders question a model’s behavior, they want answers that feel concrete. They want to know whether a prediction came from trusted data, whether a transformation changed meaning, or whether a shift in model performance can be traced to a specific dataset version. Lineage gives them that certainty.
A strong lineage system influences three areas directly.
First, governance becomes practical instead of bureaucratic.
Teams do not rely on hand written documentation or tribal knowledge. Governance workflows become lighter because the lineage trail already records collection rules, schema changes, and transformation steps. You do not enforce standards manually. You simply read the trail.
Second, trust increases across the organization.
When data consumers can verify where information came from, they rely on it more. When model owners can prove how a field changed, stakeholders feel safer deploying results. Trust is built on visibility, and lineage gives teams the visibility they need to feel confident.
Third, scale becomes manageable.
As pipelines expand, new sources join, schemas evolve, and extraction logic adapts. Without lineage, each change increases risk. With lineage, every change becomes traceable. You grow without losing control of the system. Scaling stops being scary because you are never flying blind.
AI adoption is accelerating, but enterprise risk tolerance has not changed. Organizations will only scale AI when they understand the journey of their data and can explain the logic behind every model. Lineage gives them the foundation to move fast without losing accountability. It turns opaque data flows into transparent, audit ready pathways.
Closing the Loop: Lineage as the Heart of AI-Ready Infrastructure
Data lineage is not another task in the pipeline. It is the structure that holds the pipeline together. When every collection, mapping, validation, storage, and training event is recorded, the entire system becomes easier to reason about. The model stops being a black box. Debugging stops being detective work. Compliance stops feeling like an afterthought. And development becomes much more predictable.
When lineage is embedded throughout the pipeline, teams gain abilities that did not exist before.
- They can rewind any training job.
- They can replay any dataset version.
- They can compare two model runs with precision.
- They can show auditors exactly how data flowed.
- They can detect issues long before the model sees them.
- They can scale without losing control of the system.
This is why lineage sits at the core of any AI-ready data infrastructure. It provides memory, structure, and clarity. It closes the loop between extraction and production. And it ensures the decisions your AI systems make tomorrow are grounded in data you understand today.
When you invest in lineage, you invest in the long term stability of your entire AI ecosystem. It is one of the few engineering decisions that strengthens accuracy, compliance, trust, and operational scale at the same time. Good lineage outlives every model and every architecture change, because it reflects the one thing that never goes out of date. The story of your data.
Further Reading From PromptCloud
Here are four articles that support this topic and deepen your understanding of responsible, structured data flows:
- Learn why responsible collection practices strengthen lineage foundations in our guide on Ethical Data Collection
- See how crawlers create the first traceable checkpoint in a data pipeline in Step by Step Guide to Build a Web Crawler
- Compare how delivery formats impact traceability and reproducibility in Data Delivery Formats: Pros and Cons
- Understand how lightweight extraction tools shape early lineage signals in Instant Data Scraper Chrome Extensions: A Complete Guide
Five reasons why data lineage is essential for regulatory compliance — explains how lineage supports transparency, auditability and governance.
Many organizations begin web scraping with internal scripts, but maintaining crawler infrastructure, handling anti-bot protections, and monitoring data quality quickly becomes a full-time operational task.
FAQs
1. What is data lineage in simple terms?
Data lineage is the record of where your data came from, how it moved through your systems, and what changed along the way. It shows the full path from source to storage to model or dashboard, so you can explain any value you see.
2. Why does data lineage matter for AI models?
AI models are sensitive to small changes in data. With clear data lineage, you can trace a weird prediction back to the exact dataset, transformation, or schema change that caused it. This makes debugging, retraining, and auditing much faster and more reliable.
3. How is data lineage different from dataset provenance?
Dataset provenance focuses on origin and ownership, such as which site, API, or vendor supplied the data and under what conditions. Data lineage goes further and tracks every transformation, merge, filter, and load step that happened after ingestion, all the way to the final consumer.
4. Do I really need full lineage if my pipeline is small?
Even small pipelines benefit from traceability. A single schema tweak or crawler change can alter results. Starting with simple lineage now makes it much easier to scale later without losing visibility or spending time reverse engineering how the pipeline works.
5. What tools or practices help maintain data lineage over time?
The most useful practices are versioning datasets, logging each job with configuration and schema versions, and storing transformation history alongside outputs. Whether you use a commercial catalog, a metadata store, or custom logs, the key is consistency so every model run can be tied back to a clear data trail.















