




Big Data is making it hard for the Cloud Servers
Big data is snowballing and with every passing day, cloud storages across the planet and other alike services, generally branded as ‘cloud as a service’(Caas) or Infrastructure as a service(Iaas) are getting burdened with colossal amounts of complex data processing requests. Now, supporting this fact, data-intensive applications which exist far away from its connected data center, slog to get their requests done.
Added to this, technology is marching forward with a substantial speed and cloud service providers are wriggling to maintain their pace with it. Consequently, continuous system refreshes are slashing the overall working life of the cloud servers. Where, the life of a regular web server hardware component is close to 6 years, the lifecycle of the components related to cloud servers is hardly more than 2 years. This is where edge computing steps in. Within an edge computing ecosystem, the lifecycle of regular web server components is around 8 years.

Users are Getting Mobile and more Geographically Diversified
Gone are those days, where the internet of things used to be a hush-hush topic for any discussion as it already has wired our daily lifestyle. Admittedly, we have integrated IOT with our lives and every breath of us, is now getting monitored by this technology, but at the end of the day, cloud storages, the backbone of the IOT, are storing a gigantic amount of diversified data.
Moreover, every node of IOT is not only generating data and pushing it to the cloud storage but also fetching the same amount of data from its connected source. Moreover, enterprises are hiring web crawling and web scraping services to crawl data from specific websites, or from a particular social media site, and analysing the same data to produce actionable insights for designing a better future. So, the efficiency and data processing time of this endless stream of bidirectional data flow heavily depends upon two important factors. Firstly, the data processing requests from the remote nodes depend upon the physical distance between that node and data center. Secondly, the rising amount of data processing requests from geographically scattered places is also making the whole process to chug. Now, users are plugging into the big data clouds from every corner of the earth and this existing efficiency level of cloud computing need to be raised further, with a prime focus to bring in the ability to serve more users, being a geographically distributed data platform.
It’s time to move ahead with the new Edge Computing
It is true that, the tag ‘best’ is not anyone’s copyrighted glory and nothing, in this material world, can own that tag for a lifetime as within no time a ‘better than the best’ will emerge. In this radically changing tech world, every day, the coveted level of ‘benchmark’, associated to anything or any service, is getting broken to touch new heights. Nowadays, technology is really pushing fiction to beat facts. Similarly, a new leader beyond cloud computing has started sneaking into the market and it also boasts the potential to push the traditional cloud computing back to the stone age.
Technologists already have coined a new name for this next phase of cloud computing and it is ‘Fog computing’. It is also known as the ‘Edge computing’. The chief philosophy behind this new technology is to build a better operational connectivity between a server core and the remote, data hungry applications, which are sitting at the farthest point, i.e, at the edge of the network. Moreover, the other chief areas are, data analysis and knowledge generation at the source of distributed data, retrieval of distributed data storages and remote data acquisition process.
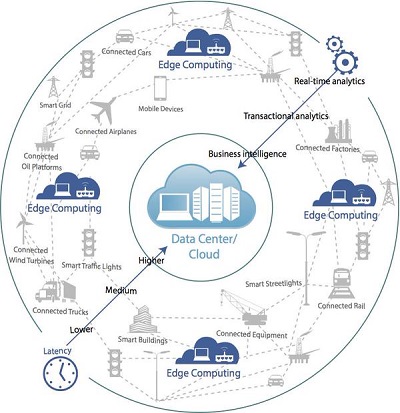
Purpose and Features of the Edge Computing
Technically, Edge computing or Fog computing is primarily focused on the process which delivers an enhanced cloud computing performance to the mobile users. The main prey of the game is to establish a data stream accelerator for mobile network applications using data caching process and to push the same to the geographically farthest located user.
Since, 2010 electronic consumer goods manufacturers shipped more smart handhelds than full functional laptops and the sole reason behind that is, people across this planet seek freedom from getting place and time specific. Now, every single web service is getting mobile smart to serve the modern users, who are drugged with agility. Today, we are wolfing up substantial amount of information, more than ever, in order to stay updated. As a result, a continuous and a thick stream of larger data packets are being delivered to the users and edge computing is here to push the cloud computing exactly to that level, where it needs to be. Below are some of the dedicated features of edge computing:
- Bridging the gap between data and its users.
- Bringing the world from the internet of things to the internet of everything.
- Establishing a superior level of geographical data distribution.
- Making the cloud more versatile to get integrated with the other evolving services.
- Helping other business verticals to harness a better level of efficiency with big data.
- Providing a better data security approach to database administrators.
- Turning live data analysis at the data source into a reality.
Organisations, who deal with big data or with similar kind of data processing solutions and services are really pressing the accelerator to accept and employ this new technology and the sole reason behind that is, they want to enhance the user experience by delivering rich content to them, that too within a blade of time.
Let us consider a popular web service which has its users spread across the globe and they continuously stream a substantial amount of data from that web app. Consequently, to maintain a good user experience, the web app service provider does not rely on 2 or 3 data centers only. Rather, for a glitch less data delivery process more data centers are needed with this newborn edge computing technology which can do most of the heavy lifting of pushing data chunks at the very edge of the network or in other way, closer to the end user.
Image Credit: pfsweb, CiscoEnterprise.















