



**TL;DR** This case study highlights how an AI-driven company improved its model performance by 40% after switching from generic data feeds to a specialized web scraping services provider. The move allowed access to high-quality, real-time, domain-specific training data tailored for their needs. This resulted in better prediction accuracy, faster deployment cycles, and improved business outcomes. If you’re training an AI model, this story is a must-read on the role data quality plays in performance.
The Hidden Link Between Data Quality and AI Model Accuracy
Ask any AI engineer what makes a model succeed, and they’ll likely mention things like architecture, training time, or compute power. But what often goes unnoticed is the actual fuel driving those systems, the data.
When a company sets out to build an AI model, the first focus tends to be on algorithms. It’s only after months of tweaking and testing that many realize: even the most advanced model can’t perform well if it’s trained on poor data.
That’s exactly what one AI company discovered, the hard way. They had built a promising system for e-commerce intelligence. Early results looked good, but after a while, progress slowed. Model accuracy started to plateau, and new features didn’t move the needle. Teams assumed the problem was technical. Maybe the model needed better tuning. Perhaps it was time to explore a new framework.
But after a deep internal review, the issue became clear. The real issue wasn’t buried in the code. It had nothing to do with how the model was built. The problem was with the data they were feeding it. Most of it came from open APIs and widely available datasets. That might sound fine in theory, but in practice, the data just didn’t fit their needs. It wasn’t fresh enough. It missed key details specific to their domain. And over time, the model started learning from examples that weren’t even relevant anymore.
So they made a bold move. They partnered with a custom web scraping services provider to build a data pipeline that could capture the exact kind of real-time, structured information their model needed, at scale.
The outcome? Their AI system improved in ways they hadn’t thought possible. Model performance jumped by 40%, not because they rewrote the code, but because they finally gave the model the right kind of data to learn from.
In this article, we’ll walk through their journey, why they hit a wall, how they made the switch, and what others can learn from it. If you’re serious about training an AI model that delivers real-world value, this is a story worth reading. Because when it comes to AI, high performance starts with high-quality data.
The Company’s Challenge: When Off-the-Shelf Data Isn’t Enough
An e-commerce brand had been investing in AI to better understand the online retail space. They had one main aim: to give the team the insights they needed—spotting market changes, keeping an eye on competitors, and tweaking prices faster—using machine learning.
At first, things looked promising. The model delivered useful trends and surfaced pricing insights that the business hadn’t seen before. But a few months in, something changed. The predictions stopped improving. They started slipping.
The team began to troubleshoot. They checked their code. They fine-tuned hyperparameters. They ran tests on new architectures. Nothing worked. And that’s when they turned their attention to the data.
Most of their input came from public APIs and prebuilt datasets. These sources were reliable, but also limited. The product data wasn’t always up to date. Some competitor listings were missing. Promotional changes, pricing shifts, and stockouts sometimes took days to appear in the system.
Even more frustrating? They couldn’t decide what they were pulling in. They were stuck with whatever the feed gave them—no say in which pages got tracked, how often the data came in, or what product details mattered to their use case. They were stuck with whatever the feed delivered.
This became a serious problem as their model began to make decisions based on old or incomplete information. When a competitor launched a flash sale, their system often didn’t catch it in time. When product availability changed, the model kept suggesting inventory strategies based on outdated listings.
That kind of lag costs money, and in retail, speed matters.
Eventually, the team had to face a hard truth. Their AI wasn’t underperforming because of how it was built. It was underperforming because it was learning from the wrong kind of data. Generic sources were holding it back.
They didn’t need more data. They needed better data. It had to be fresh. It had to be specific. And it had to reflect the real-time movements of a fast-changing market.
That’s when they began to explore custom web scraping services. The idea wasn’t to collect everything, it was to collect the right things, from the right places, at the right frequency.
Why They Chose Custom Web Scraping Services
Once they accepted that the generic data sources weren’t helping anymore, the team knew they had to rethink how they were collecting information. What they needed wasn’t more data, but data that fit what they were trying to build. They wanted to be able to decide what was collected, how often, and in what format—something the off-the-shelf options just couldn’t offer.

The Problem With “Standard” Data
At first, the team figured their data sources were good enough. After all, APIs from well-known marketplaces provided basic product information. It was clean, structured, and ready to use. But over time, cracks started to show.
The feeds missed key product listings. Some prices were outdated. Promotions came and went without being tracked. For a model that was supposed to pick up on patterns in the market, this wasn’t just a gap—it was a blindfold.
The AI was being trained on stale, incomplete snapshots of what was really happening. It made the system slow to react, and even slower to improve. Eventually, it became clear: no matter how many times they adjusted the model, it couldn’t learn what it didn’t see.
Why Custom Scraping Made Sense
They didn’t want more data. They wanted the right data, specific to their market, updated regularly, and detailed enough to reflect how people actually shop.
That’s when they started considering a different route. Instead of relying on whatever limited information the APIs offered, what if they could pull data directly from the websites their customers and competitors were already using?
Custom web scraping offered that control. It let them decide what mattered. Want to track the price of a product every hour instead of once a day? Done. Need shipping costs, customer ratings, and discount history, too? No problem.
They weren’t scraping the entire internet. They were zeroing in on a few high-impact sources and collecting only what their model needed to make smarter decisions.
Data That Mirrors the Real World
One of the biggest shifts came from how current the data was. Before, they might get updates once a day, sometimes less. Now, they could track changes almost as they happened.
If a competitor changed their price at noon, they’d know before lunch. If a product went out of stock in a key region, their model could adapt within hours.
This wasn’t just about speed; it was about keeping the AI grounded in reality. And when the model learned from real, current examples, its predictions started to actually reflect what users were seeing on the ground.
Tailored Data Makes a Better Learner
The most surprising part? They didn’t need to feed the model dramatically more data. They just needed to feed it better data. Cleaner inputs. More useful signals. Less noise.
Custom scraping gave them a way to cut out the fluff and focus on what mattered. The model didn’t have to guess what was relevant anymore. It could be seen directly.
The gains didn’t take long to show up. Accuracy improved. Predictions made more sense. And the model became easier to fine-tune, because the data beneath it was finally working with them, not against them.
Implementation: Building the Right Data Pipeline
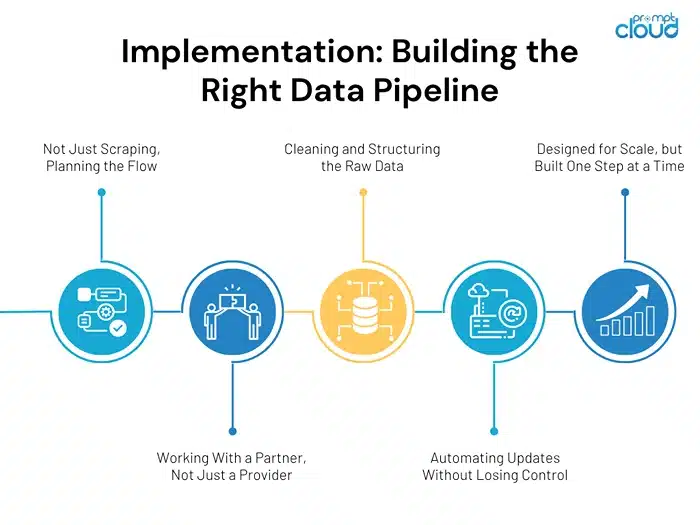
Not Just Scraping, Planning the Flow
Once the team settled on using custom web scraping, the next challenge was putting it into practice. Collecting the right data is one thing. Making sure it flows smoothly into your AI pipeline is another.
They started by figuring out exactly what the model needed to learn from. Not “more data,” but specific fields, from specific pages, on a specific schedule. That meant product titles, prices, availability, discount patterns, and a few less obvious things—like shipping costs and customer reviews.
This wasn’t about collecting everything. It was about collecting what mattered, cleanly and consistently.
Working With a Partner, Not Just a Provider
The company didn’t try to build the scraper internally. Instead, they partnered with a team that specialized in web scraping services.
But it wasn’t just a handoff. It was a back-and-forth. Their data scientists explained how the model worked, what kinds of inputs drove accuracy, and which edge cases to watch out for. The scraping partner, in turn, helped map out how to extract that data without overloading servers or getting blocked.
This kind of collaboration paid off. The scrapers weren’t built blindly—they were shaped by what the AI actually needed.
Cleaning and Structuring the Raw Data
Getting the data was just the first step. Raw HTML can be messy. Different websites display similar information in different ways. Some include multiple prices for a single item. Others bury shipping rules three clicks deep.
So, the team built a layer of logic on top of the scraped content. This cleaned up inconsistencies, filled in missing values, and translated unstructured content into training-ready formats. It was tedious, but worth it.
When they first started, they were spending hours fixing broken inputs. Now, most of the pipeline ran without human touch, and the model learned from clean, trustworthy data every day.
Automating Updates Without Losing Control
One of the most important parts of this new setup was automation. Once the scraping scripts were stable, they were scheduled to run at regular intervals. No one had to manually trigger data pulls or check for changes. The pipeline just worked.
But the team didn’t want to lose visibility. So they built in alerts—if a site changed its layout, if a key field was missing, or if data volumes dropped suddenly, they’d know right away.
This gave them confidence. The model wasn’t learning from outdated or broken inputs. And when something broke, they could fix it fast, often before anyone else noticed.
Designed for Scale, but Built One Step at a Time
What stood out most was how incremental the process was. They didn’t scrape hundreds of sites on day one. They started with five.
Once they had a clean pipeline for those, they expanded. Then again. Each time, they used what they’d learned to improve the next build.
By the time they had full coverage across their target verticals, the system was running like clockwork.
And the AI model? It finally had the kind of environment where it could thrive.
The Outcome: A 40% Boost in AI Model Performance
After months of slow progress and flatlining results, the shift to a custom data pipeline finally gave the model the foundation it needed. It wasn’t just about feeding the system more information; it was about feeding it the right kind of information, in the right format, and at the right time.
With higher-quality inputs, the model didn’t just recover. It improved quickly and noticeably.
The First Signs of Change
The improvements didn’t show up overnight. But within a few weeks of feeding the AI model with better-quality data, the team noticed something different. The predictions weren’t just more accurate—they were more useful.
The model started spotting trends earlier. It picked up on competitor pricing changes almost as they happened. And it began reacting more intelligently to stock shifts, new product listings, and fluctuating demand.
One of the engineers put it this way: “Before, we were teaching the model to guess. Now, we’re helping it see.”
What 40% Improvement Means
Over three months, the team tracked performance across several key metrics. These weren’t just academic benchmarks—they tied directly to how well the model served the business.
The biggest gains came in:
- Prediction accuracy: up 40% compared to their previous setup
- Recall: especially for fast-changing items like promotional SKUs
- Time-to-update: model refresh cycles shortened by nearly 60%
- Data quality confidence: internal validation errors dropped significantly
What this meant in practice was fewer missed opportunities. The model caught flash sales, tracked subtle pricing shifts, and updated strategy recommendations in near real-time. Marketing teams could move faster. Inventory decisions improved. Customers saw better recommendations.
And unlike previous upgrades that offered marginal gains, this one shifted the baseline. The model wasn’t just optimized—it had a new foundation.
How the Business Felt the Difference
Internally, teams noticed a change in how they worked. They stopped second-guessing the data. Fewer manual overrides were needed. Fewer questions about whether the AI’s output could be trusted.
Executives, too, started seeing the ripple effect. Reports were sharper. Insights were more actionable. Campaigns ran with tighter alignment to market conditions.
What had started as a quiet switch in the data pipeline had turned into a measurable business advantage.
Why This Wasn’t Just a One-Time Win
Here’s the important part: this wasn’t a magic fix. The 40% improvement didn’t come from one dataset or one new feature. It came from a structural change in how the team treated data, from a passive feed to an active asset.
By choosing custom web scraping services, they didn’t just solve a short-term problem. They built a system that adapts to the market. One that gives the AI model fresh, relevant input every day. And that’s the kind of advantage that doesn’t fade.
What This Means for AI Teams Evaluating Data Solutions
For AI teams struggling to move the needle, this case offers something valuable: a reminder that no matter how sophisticated your model, its performance will always be limited by the quality of the data behind it.
Algorithms Can’t Fix What Data Fails to Show
It’s easy to blame model performance on the algorithm. Maybe you’ve been tweaking hyperparameters for weeks. Maybe you’re considering switching frameworks or adding more layers. But sometimes, the problem isn’t in the model—it’s upstream.
It didn’t matter how smart the model was on paper. Without the right data feeding it, the results just weren’t there. Once the team stopped focusing on the algorithm and took a closer look at what the model was learning from, things finally started to shift.
Generic Feeds Don’t Support Specialized Use Cases
Off-the-shelf data feeds work fine until your business outgrows them.
At some point, most teams hit a wall. The data sources they started with worked fine in the beginning, but over time, they just weren’t detailed or fast enough to keep up. This kind of gap becomes a real problem in industries where things change quickly—like online retail, financial markets, or travel—places where making the right call often depends on having the latest info, not what was true last week.
Custom data collection, through reliable web scraping services, becomes the edge. It helps your AI model stay in sync with the real world, not a version of it from days ago.
Custom Data Pipelines Don’t Just Help Models, They Help Teams
There’s a practical side to this, too. Cleaner, tailored data makes debugging easier. It reduces manual overrides. It increases internal confidence in the AI system, which matters more than it’s often given credit for.
When teams don’t have to fight their data pipeline, they spend more time building, improving, and innovating. The feedback loop shortens, and iteration becomes easier.
This Isn’t Just About Performance, It’s About Future-Proofing
Data changes. Markets shift. Models evolve.
One of the biggest advantages of moving to a custom web scraping solution is flexibility. You’re not locked into a static feed. You can adapt what you collect, how often you collect it, and where you collect it from.
That means your AI can evolve alongside your business, without rebuilding everything from scratch.
The Future of AI Model Training Starts With the Right Data
For all the talk about AI breakthroughs—new algorithms, faster hardware, bigger models—it’s easy to forget one thing: none of it works without the right data.
This case proves a simple point. You can spend months tuning your AI model. You can try every open-source tool, explore every optimization technique. But if the data going in doesn’t reflect your world, your model won’t either.
That e-commerce team didn’t improve performance by redesigning their system. They didn’t throw more compute at the problem. They changed what their model was learning from. That shift led to real gains. Not small, incremental improvements—but a 40% jump in performance that directly impacted how the business operated.
They did it by working with a custom web scraping services provider, not just to gather data, but to gather the right data. Data that was structured, current, and highly relevant to their domain. It wasn’t the easiest route, but it was the one that worked.
For teams serious about training an AI model that does more than just function—for those building systems that need to stay sharp in dynamic environments—this matters.
Because in the end, the strength of your AI isn’t just about how it thinks. It’s about what it sees.
FAQs
1. Why is the quality of training data such a big deal for AI?
Because the model doesn’t magically understand the world, it learns from whatever you give it. If that data is old, incomplete, or off-target, the model is going to struggle. It’s like teaching someone to drive using outdated road maps—you’ll get a lot of wrong turns, no matter how good the car is.
2. Isn’t using APIs easier than setting up a web scraper?
Sure, APIs are easy—until you realize they only give you part of the picture. If you’re trying to build something smart and specific, like tracking competitor pricing down to the hour, most APIs just won’t cut it. Scrapers take more effort upfront, but you get exactly what you need, the way you need it.
3. Can scraped data really be that fresh?
If it’s set up right. You can pull updates every few hours or even faster, depending on the site and how you build the system. In the case we just covered, the company went from daily lags to seeing market changes in near real-time. That made a huge difference.
4. Is this only useful for e-commerce, or are other industries doing it too?
It’s not just retail. We’ve seen this kind of setup used in travel, finance, job boards, and even real estate. Basically, any field where public data changes quickly and AI needs to stay current—that’s where custom scraping helps a lot.
5. How long before you start seeing actual improvements after switching?
You won’t flip a switch and get results the next day. But within a few weeks, you’ll probably notice the model behaving differently—better, smarter. And by a few months in? You’ll wonder how you ever got by on off-the-shelf data.















