



Introduction To Wikipedia Data Extraction:
Wikipedia, the online multilingual encyclopedia been used by almost everyone since their college days. Today, there are niche websites catering to different crowds. But in the early 2000s, for many students, Wikipedia was all that they used on the internet. It is an open collaboration project and due to this, anyone can contribute to it. With the ever-changing world, webpage content also needs to get updated from time to time. On Wikipedia, it is by the general public. Available in 285 languages, it boasts of more than around 300,000 active users who update the information on it. Even though you cannot use Wikipedia data on your research paper, it remains one of the best online sources of information for general purposes.
Where Is The Code?
Python3.7 or higher is a must for this code, but today we will be using the Wikipedia library in Python instead of the usual BeautifulSoup. Once you have copied and pasted this code in a file, you can edit in using an IDE or a text editor like Atom. But before you actually run this code, understanding it is important.
- We start with importing the libraries required for the code to run and then take the keywords for which we will be extracting info from Wikipedia
- Next, we get the page object using the command “wikipedia.page”. We are running this code for Guido van Rossum who is the creator of Python
- Once we have the page, we can extract different data points from the object. We start with the content. However, the content is in a text format and you cannot separate out the heading and the data under each heading. Hence, we have created a parser that parses the content and converts the content into key-value pairs in a dict. The keys here are the various headings and subheadings in the Wikipedia webpage whereas the content in each of these headings stored as the values
- Once done, we can easily copy other data points and store them in our JSON. These include the title of the page, reference given on the page, links present in the content, images in the content, suggestions (this will be a non-null value when you have spelled your search keyword wrong), search results for the particular topic used, and categories given at the end of the webpage
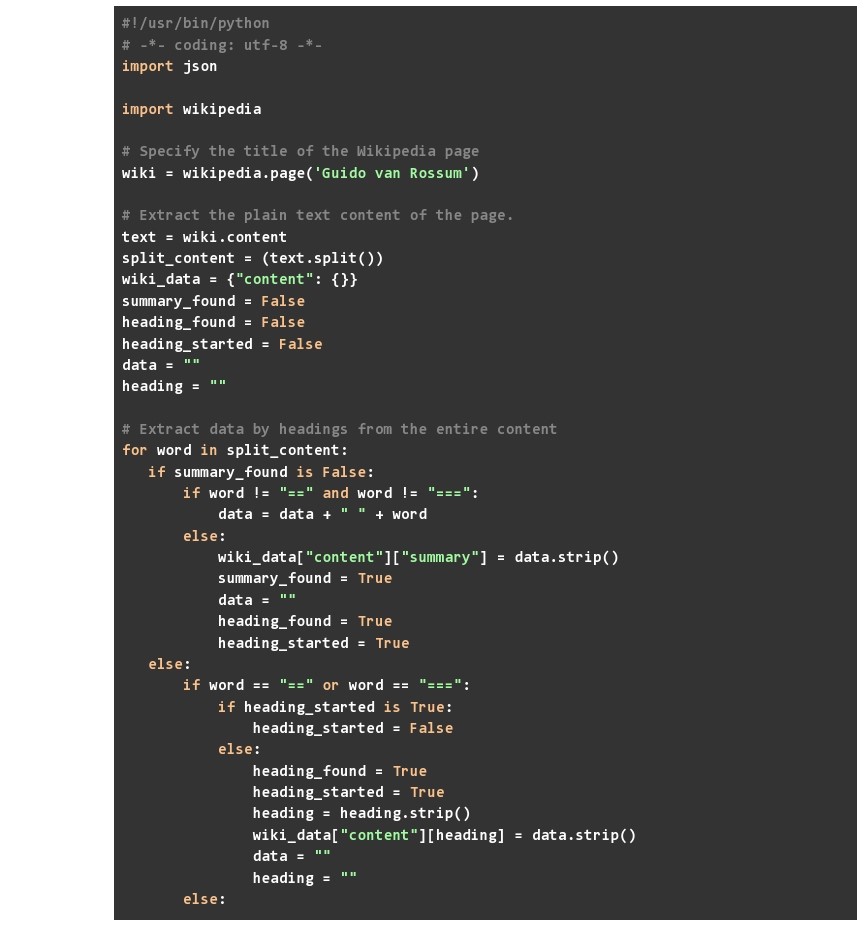
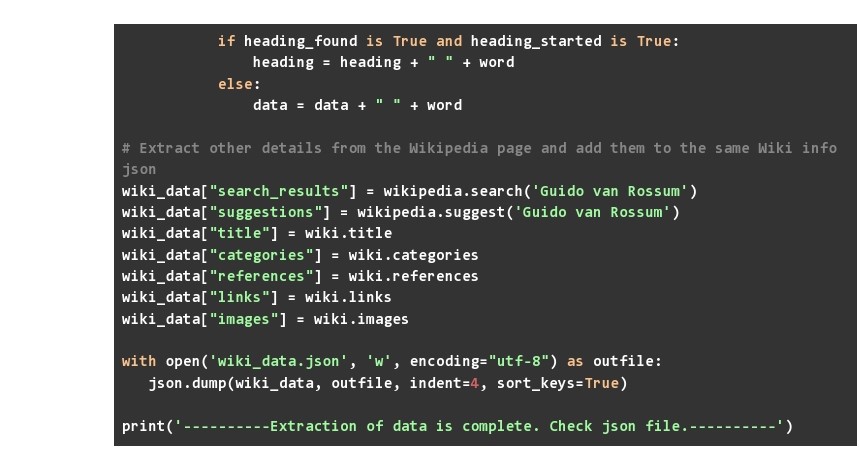
5. We save all this data in a JSON file called wiki_data.json and once the code runs, you will find that this file created in the same directory where you ran your Python code
What Wikipedia Data Did We Scrape?
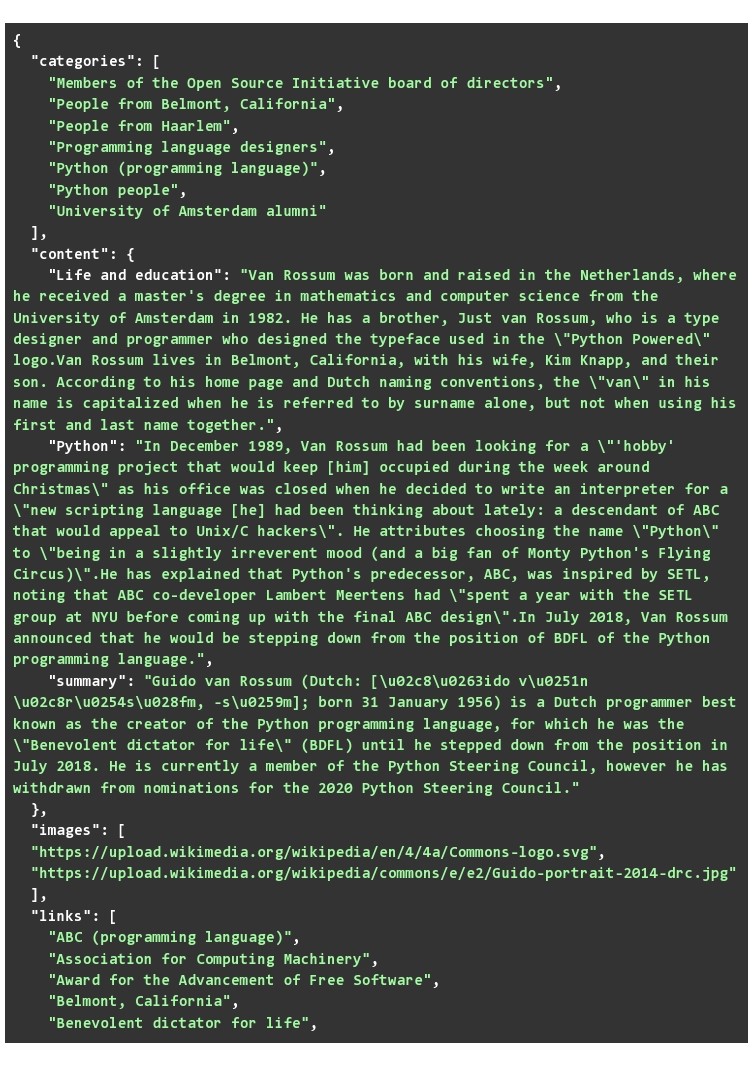
You can use the JSON file below to see what results “Guido van Rossum” fetches you. Run the code on some other keywords as well. It is noted that a number of data points, actually had many more values, but we had to truncate the data to fit it in this blog.
One important data point that needs to be explained is categories. The categories refer to articles that fall under a common topic. So, for the categories that are displayed in Guido van Rossum’s Wikipedia page, you would find some relation with the person. The content is obviously the most important data point and since we parsed it and stored it in a key-value format, there are two benefits:
- You know which topics were covered for a particular Wiki Search
- You can fetch data under a topic easily
The images and links can also be helpful. Useful for someone who wants images on a specific topic. Whereas the links can be traversed by a web scraper to find related topics and create content.
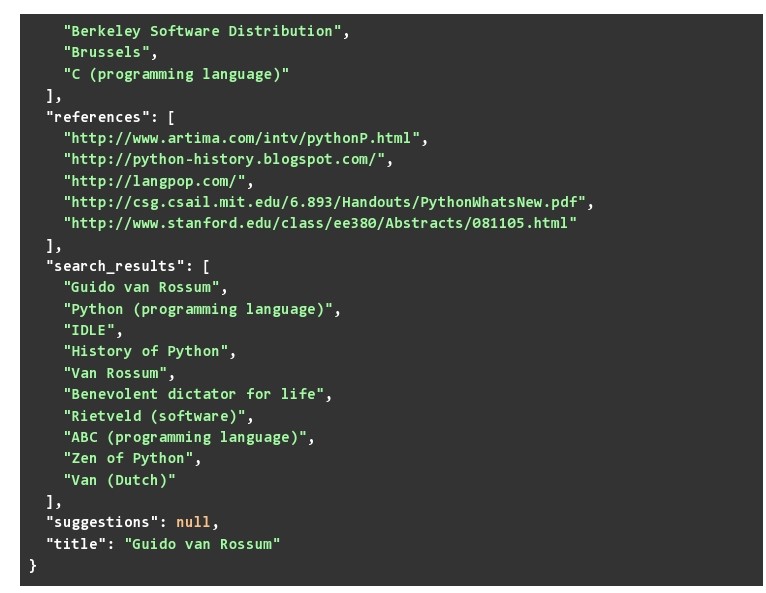
The Suggestion key has a null value since we spelled “Guido van Rossum” correctly and Wikipedia did not have any other string to suggest. The search results are the search results given by Wikipedia. When you put the topic used in a search query on the webpage.
Problems When Running It On A Large Scale:
While this code may look attractive, not all Wikipedia pages are similar. There’s a high chance of your code-breaking. Or you being unable to gather all the data points when you are scraping multiple webpages. Another issue is the problem with HTML data not being converted to UTF or ASCII text formats. Due to this, some places in the output JSON may seem to have unknown characters and symbols.
When it comes to large scale automated data scraping, our team at PromptCloud provides customized solutions to companies. No matter how many websites you need to scrape and how frequently the data needs to get updated. We can help you with your data requirements to enable you to make data-backed business decisions.















