




Over the last year or so, GPT-4 has been showing up everywhere, from helping students finish essays to writing functional code in minutes. Built on the same core as ChatGPT, GPT-4 is part of a family of large language models (LLMs) that are trained on massive datasets. This lets them do all sorts of things: answer questions, generate content, debug code, summarize documents, translate languages, and yes, even write web scraper scripts.
So, it’s no surprise that more and more people, especially data engineers, product managers, and even non-coders, are asking the same question:
Can GPT-4 actually build web scrapers good enough to use in real-world business scenarios?
On the surface, it looks promising. You type in a prompt like “Write a Python script to scrape product names and prices from an e-commerce site,” and boom, you’ve got code that looks like it might work.
But is that enough?
That’s what we’re going to unpack in this article. We’ll take a closer look at what GPT-4 and other LLMs can actually do when it comes to web scraping, where they fall short, and why companies that need reliable, large-scale data still turn to specialized providers like PromptCloud.
What is Web Scraping Using LLMs Like GPT-4?
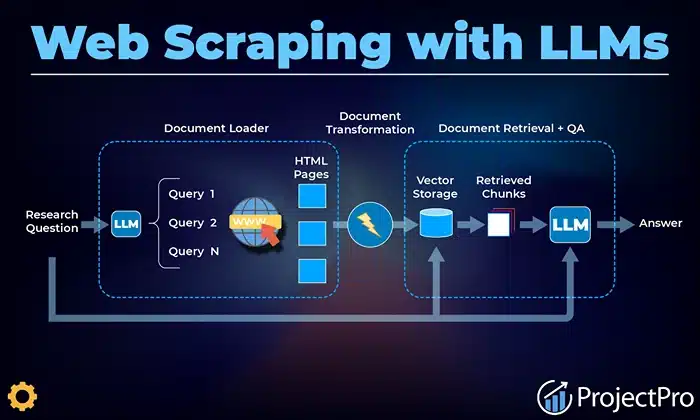
Image Source: projectpro
Web scraping, at its core, is about pulling data from websites, anything from product prices to job listings to social media posts, and turning it into something structured and usable. For years, developers have done this with traditional tools like Python, BeautifulSoup, Selenium, and Scrapy. But now, with models like GPT-4, the game is starting to shift.
So, what does web scraping using LLMs like GPT-4 actually mean?
It means using a language model either directly through ChatGPT or via API to generate code that performs scraping tasks. You give it a prompt describing what you want (let’s say, “Scrape all H1 tags from a webpage”), and it spits out a Python script with all the basics included.
Here’s the kind of thing GPT-4 might give you:
python
CopyEdit
import requests
from bs4 import BeautifulSoup
url = ‘https://example.com’
response = requests.get(url)
soup = BeautifulSoup(response.content, ‘html.parser’)
for h1 in soup.find_all(‘h1’):
print(h1.text)
Not bad, right?
In simple, static use cases, this kind of AI web scraper can be useful, especially for developers who just want to quickly test something out or grab a handful of data points. It’s fast, flexible, and doesn’t require starting from scratch.
Some real-world examples where ChatGPT web scraping might work include:
- Scraping news headlines from a blog or media site.
- Extracting product names and prices from simple HTML pages.
- Grabbing meta tags or links from a homepage.
These are all straightforward tasks that don’t require authentication, JavaScript rendering, or advanced error handling. In these cases, GPT-4 can genuinely save time and effort, especially if you already know a bit of Python and just need a solid starting point.
But, and there’s always a but, once you start pushing into real-world complexity, things begin to fall apart.
The Limitations of Using LLMs like GPT-4 for Web Scraping

Here’s the part most demo videos and blog posts don’t talk about: GPT-4 may be able to write a basic scraper, but that doesn’t mean it’s ready for real-world production use.
There’s a gap, a big one, between writing code that works in theory and running scrapers at scale in real environments. And GPT-4, for all its intelligence, hits that wall pretty quickly.
Let’s look at where it struggles.
1. No Real-Time Execution or Feedback
GPT-4 can write code, but it can’t run it or test it. If there’s a bug in the script, it gives you and there often is, it won’t know until you find out. It can’t see the website you’re trying to scrape, can’t check if the HTML layout changed, and definitely can’t click around to figure out what’s behind a button or menu.
In short, it’s writing code blind.
You can copy-paste that code into your terminal, sure, but as soon as it breaks (and it will), you’re on your own to fix it.
2. JavaScript? Dynamic Content? Forget It.
Modern websites are rarely static. Most are built with frameworks like React, Angular, or Vue, which means the content you want doesn’t actually exist in the initial HTML. It’s loaded in after the page loads, via JavaScript.
GPT-4 doesn’t browse the web. It doesn’t load pages. It doesn’t interact with dynamic elements.
This is a huge limitation. If you’re trying to scrape prices, reviews, or inventory data from a JavaScript-heavy e-commerce site, GPT-4’s vanilla BeautifulSoup script isn’t going to cut it. You’ll need headless browsers, rendering engines, wait conditions, things that go way beyond “write me a scraper.”
3. No Support for Auth, Logins, or Rate Limits
Many websites require a user login before they serve up the data you want. Others have anti-bot systems that check for suspicious activity. And nearly all have rate limits.
GPT-4 doesn’t handle authentication tokens, session management, rotating headers, or timed requests. If you ask it to write code for scraping behind a login, it might attempt something, but chances are it’ll be incomplete or outdated.
And if the site uses a captcha or geo-blocks content?
You’re out of luck.
4. Scaling is a Whole Different Beast
Sure, GPT-4 can help generate code for scraping one page, or maybe even ten. But what happens when you need to scrape 10,000 product URLs across multiple regions, every four hours, and dump it all into a structured format for your internal analytics?
That’s not something you can do with a copy-pasted script from ChatGPT.
GPT-4 doesn’t handle orchestration, concurrency, distributed crawling, retries, or queue-based processing. It doesn’t do robust error logging or recovery. It doesn’t scale. It can help start the process, but it doesn’t stick around to run or manage it.
5. Compliance? Good Luck.
This one’s critical: GPT-4 doesn’t know if your scraper is violating a website’s terms of service. It won’t flag if a script is scraping personal user data. It doesn’t check for GDPR or CCPA compliance, and it certainly doesn’t adjust request frequency to stay under the radar.
For businesses, this isn’t just an inconvenience, it’s a legal and reputational risk.
So, while LLM web scraping might sound appealing, the truth is: GPT-4 can assist with the early part of the journey. But it cannot safely or reliably deliver what most businesses actually need.
Why Expert Web Scraping Providers Still Win Over GPT-4
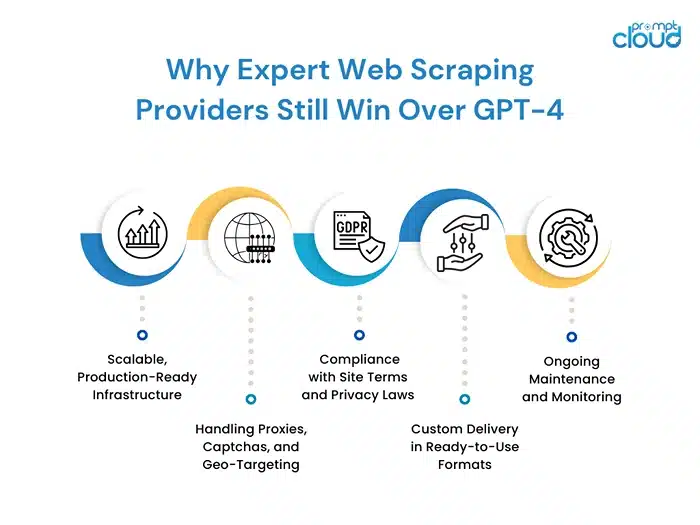
So here’s the honest truth: while GPT-4 is impressive and yes, it can absolutely help with writing and understanding basic scraping code, it’s not built for the real demands of web data extraction at scale.
When companies need clean, structured, high-volume data delivered reliably and ethically, they turn to dedicated web scraping service providers. And there’s a reason for that: scraping isn’t just about writing code. It’s about engineering, maintenance, infrastructure, compliance, and delivery.
Let’s break down why providers like PromptCloud still offer the smarter path.
1. Scalable, Production-Ready Infrastructure
The biggest difference between a GPT-generated script and a professional web scraping solution? Infrastructure.
PromptCloud, for example, operates large-scale crawling frameworks that are built to handle millions of pages per day, across thousands of domains. These systems are engineered for things like concurrency, load balancing, and fault tolerance, things that GPT-4 simply can’t factor into the code it generates.
Want to scrape hundreds of thousands of product listings across multiple websites every day? You’ll need a distributed architecture, dynamic job scheduling, data pipelines, and performance monitoring. That’s what PromptCloud brings to the table.
2. Handling Proxies, Captchas, and Geo-Targeting
If you’ve ever tried to build your own web scraper, you know it the minute you start hitting a website more than a few times, you get blocked. Sites use everything from IP monitoring to JavaScript fingerprinting to protect their data.
Professional scraping services have already solved this problem.
They use rotating proxies, residential IP pools, geo-targeted IPs, and captcha-solving mechanisms to make sure your scraper gets through and stays invisible. It’s not something GPT-4 can just “add to your code” on demand. It requires infrastructure, experience, and ongoing tuning.
3. Compliance with Site Terms and Privacy Laws
This is the part that gets risky for companies that try to do everything in-house using GPT or open-source scripts.
Many websites have terms of service that restrict how their data can be collected or used. Add to the regulations like GDPR, CCPA, or industry-specific privacy laws, and suddenly, web scraping becomes a legal minefield.
PromptCloud builds scraping pipelines that respect robots.txt, honor site terms, and anonymize or structure data in ways that comply with privacy regulations. That level of care isn’t something GPT-4 is trained to handle, and the risk of getting it wrong is significant.
4. Custom Delivery in Ready-to-Use Formats
Another overlooked piece of the scraping puzzle? Delivery.
Once the data is scraped, it needs to be structured, cleaned, validated, and delivered, usually in a format your systems can ingest directly. That might be CSV, JSON, XML, or even integrated into your S3 bucket or database.
GPT-4 won’t manage that. It gives you a script. That’s it.
PromptCloud, on the other hand, delivers complete data pipelines from crawling to transformation to delivery, all tailored to your workflows. Whether you’re feeding it into your BI tools, dashboards, pricing engines, or market analysis reports, the data comes in ready to go.
5. Ongoing Maintenance and Monitoring
Websites change all the time, sometimes subtly, sometimes dramatically. A new layout, a renamed tag, or a different DOM structure can break your scraper overnight.
If you’re relying on GPT-generated code, you’ll need to go back, describe the issue, get new code, and hope it works. And repeat that process every time something breaks.
Providers like PromptCloud monitor all crawlers in production. When a site changes, their systems detect it, flag the issue, and fix it often before the client even knows something broke. That’s peace of mind you just can’t get with AI-generated DIY scripts.
So while using GPT 4 for writing simple web scrapers may seem tempting, professional services offer robust, scalable, and legal solutions that GPT simply can’t replicate — not yet, anyway.
GPT-4 is Smart, But It’s Not a Web Scraping Solution
Here’s the bottom line: GPT-4 is a powerful assistant, not a complete replacement for professional web scraping workflows. It can absolutely help data engineers or product managers prototype code, understand HTML structures, or generate snippets quickly, but it doesn’t replace the engineering, infrastructure, and compliance backbone needed for production-grade scraping.
If you’re a developer trying to learn or a business testing out light scraping tasks, GPT-4 and tools like ChatGPT are great for getting started. They can help you explore how scrapers work, generate ideas, and even debug basic scripts. There’s real value in that.
But once you move beyond toy projects, once you need to scrape millions of pages, extract structured insights, and feed that data into a core business system, you’re in a different league. You need reliability. You need accuracy. You need support. And you need to make sure you’re not accidentally violating site policies or privacy laws.
That’s where professional providers like PromptCloud come in.
With a decade of experience, a battle-tested infrastructure, and a team that understands the legal and technical complexity of modern web data extraction, PromptCloud delivers what GPT-4 can’t:
- Scalable scrapers built for production workloads
- Compliance-ready processes that protect your business
- Flexible delivery pipelines that fit your internal tools
- Ongoing maintenance and support, so you never worry about breakage
Large language models like GPT-4 are incredible tools, and their role in web scraping will absolutely continue to grow. But for companies that depend on accurate, timely, and structured data at scale, the smartest play is still to work with experts who do this every day.
Use GPT-4 to brainstorm. Use PromptCloud to execute.















