




Why Generative AI in Retail Fails Without Real-Time Web Data
Generative AI in retail is only as effective as the data it is trained on. Static datasets limit accuracy, while real-time web data enables AI systems to respond to pricing changes, demand shifts, and competitor actions. Retail leaders are moving from model-first thinking to data pipeline-first architectures, where web scraping provides continuously updated, structured inputs that power personalization, pricing, and decision-making at scale.
Most retail teams assume generative AI is a model problem.
They invest in LLMs, fine-tuning, and prompt engineering. But the results often plateau. Recommendations feel generic. Pricing strategies lag behind competitors. Personalization lacks context.
The issue is not the model. It is the data.
Generative AI systems are only as good as the data they consume. When trained on static, outdated, or incomplete datasets, they produce outputs that fail to reflect real-world market conditions.
Retail is not static.
Prices change daily. Competitors launch new products. Availability fluctuates. Customer preferences shift across channels and time periods.
If your AI is not connected to these signals, it is operating in a simulated environment.
This is where web scraping becomes critical.
Web data provides:
- Real-time pricing and product signals
- Competitive intelligence across marketplaces
- Customer sentiment through reviews and feedback
- Assortment and availability trends
Instead of relying on periodic data updates, retail teams are building systems where generative AI is continuously fed with fresh, structured web data.
The shift is clear:
From model-centric AI → data-centric AI systems
That shift determines whether generative AI becomes a differentiator or just another experiment.
Why Static Datasets Break Retail AI Systems
Retail Data Changes Faster Than AI Can Adapt
Most generative AI systems in retail are trained on snapshots of data. These snapshots quickly become outdated.
Retail environments are highly dynamic:
- Prices change multiple times a day
- Promotions start and end rapidly
- Competitor assortments shift constantly
- Product availability fluctuates by location
When AI models rely on static datasets, they operate on assumptions that are no longer true. This leads to outputs that are misaligned with current market conditions.
The Gap Between Training Data and Market Reality
Static datasets create a disconnect between what the model has learned and what is actually happening.
For example:
- A pricing model trained on last month’s data may ignore current discounting trends
- A recommendation system may promote out-of-stock or irrelevant products
- A content generation system may reflect outdated product positioning
This gap reduces the usefulness of AI outputs and limits their impact on business decisions.
Personalization Breaks Without Fresh Context
Personalization depends on context. Without updated data, AI systems cannot accurately reflect:
- Current user preferences
- Trending products
- Real-time demand signals
This results in generic recommendations that fail to drive engagement or conversion.
Fresh data enables AI to align recommendations with what customers are actively searching for and buying.
Pricing and Inventory Decisions Become Reactive
Static data forces businesses into a reactive mode.
Instead of anticipating changes, teams respond after:
- Competitors adjust pricing
- Products go out of stock
- Demand patterns shift
This delay creates missed opportunities in both revenue and customer experience.
Why This Limits the Value of Generative AI
Generative AI is designed to produce dynamic outputs. However, when it is powered by static data, it becomes a static system.
The limitation is not in the model’s capability.
It is in the data it depends on.
To unlock the full value of generative AI in retail, systems must move from:
- Periodic data updates → continuous data streams
- Historical snapshots → real-time signals
- Isolated datasets → integrated data pipelines
Stop unreliable retail data pipelines. Start making AI decisions with confidence.
Get clean, structured web data delivered on your cadence from a managed pipeline built around your specific sources and schema requirements.
• No contracts. • No credit card required. • No scraping infrastructure to maintain.
What Data Generative AI Actually Needs in Retail
From Raw Data to Decision-Ready Inputs
Generative AI requires more than large volumes of data. It requires relevant, structured, and continuously updated inputs.
The focus is not just on data availability, but on data usability.
Core Data Layers That Power Retail AI Systems
Effective generative AI systems in retail are built on multiple data layers working together.
| Data Layer | What It Includes | Why It Matters |
| Pricing Data | Product prices, discounts, competitor pricing | Enables dynamic pricing and competitive positioning |
| Product Data | SKU details, categories, attributes | Supports accurate recommendations and content generation |
| Availability Data | Stock levels, delivery timelines | Prevents poor user experience from unavailable products |
| Customer Sentiment | Reviews, ratings, feedback | Improves personalization and product decisions |
| Competitive Intelligence | Assortment, promotions, positioning | Helps identify gaps and opportunities in the market |
Why Structure and Consistency Matter More Than Volume
Large datasets do not guarantee better outcomes.
If data is:
- Inconsistent across sources
- Poorly structured
- Missing key attributes
AI systems struggle to generate reliable outputs.
Structured data ensures:
- Consistent interpretation across models
- Better alignment with business use cases
- Improved accuracy in predictions and generation
The Role of Continuous Data Updates
Retail data loses value quickly.
Generative AI systems must be fed with:
- Frequent updates on pricing and promotions
- Real-time availability signals
- Ongoing sentiment inputs
This allows AI to stay aligned with current market conditions and produce outputs that are relevant and actionable.
From Data Inputs to Business Impact
When the right data layers are combined and maintained, generative AI can:
- Adjust pricing strategies dynamically
- Generate personalized recommendations
- Optimize inventory decisions
- Improve customer experience
The outcome is not just better AI performance, but better business outcomes.
Need This at Enterprise Scale?
While building web data pipelines in-house works for limited AI experiments, scaling generative AI across pricing, personalization, and inventory systems introduces challenges in reliability, data consistency, and continuous updates. Most enterprise teams evaluate build vs managed data pipeline trade-offs to determine the total cost of ownership.
How Web Scraping Feeds Generative AI Pipelines
From Data Collection to Continuous Intelligence
Generative AI systems require a constant flow of fresh data to remain effective. Web scraping enables this by extracting real-time signals from ecommerce platforms, marketplaces, and digital channels.
Instead of relying on internal data alone, retailers can capture:
- Competitor pricing and promotions
- Product assortment changes
- Customer reviews and ratings
- Availability and delivery signals
This transforms generative AI from a static system into a continuously learning and adapting engine.
Building the Data Pipeline That Powers AI
Web scraping is not just about collecting data. It is about building a pipeline that ensures data is usable at every stage.
A typical pipeline includes:
- Data extraction from multiple web sources
- Cleaning and normalization across formats
- Structuring data into consistent schemas
- Feeding processed data into AI models
Without this pipeline, data remains fragmented and difficult to integrate into AI systems.
Enabling Real-Time Pricing and Competitive Intelligence
Retail pricing strategies depend on timely and accurate data.
Web scraping provides visibility into:
- Competitor price changes
- Discount patterns
- Product positioning across marketplaces
Generative AI models use this data to:
- Suggest optimal pricing strategies
- Identify underpriced or overpriced products
- Align pricing with market conditions
This allows retailers to move from periodic pricing updates to continuous optimization.
Powering Personalization and Recommendation Systems
Personalization improves when AI systems have access to diverse and up-to-date data.
Web scraping contributes:
- Trending product data
- Customer sentiment signals
- Behavioral patterns inferred from reviews and ratings
With these inputs, generative AI can:
- Generate more relevant product recommendations
- Tailor content based on current trends
- Improve engagement and conversion rates
Improving Inventory and Demand Forecasting
Inventory decisions depend on understanding demand signals across the market.
Web data helps identify:
- High-demand products
- Stock availability across competitors
- Seasonal and promotional trends
Generative AI models can use this data to:
- Forecast demand more accurately
- Optimize stock levels
- Reduce lost sales due to stockouts
From Data Pipelines to AI-Driven Retail Systems
The real value of web scraping lies in how it integrates with AI systems.
When properly implemented, it enables:
- Continuous data ingestion
- Real-time updates across systems
- Consistent data quality and structure
This creates a foundation where generative AI can operate effectively, producing outputs that reflect current market conditions.
Use Cases of Generative AI in Retail Powered by Web Data
1. Dynamic Pricing Optimization
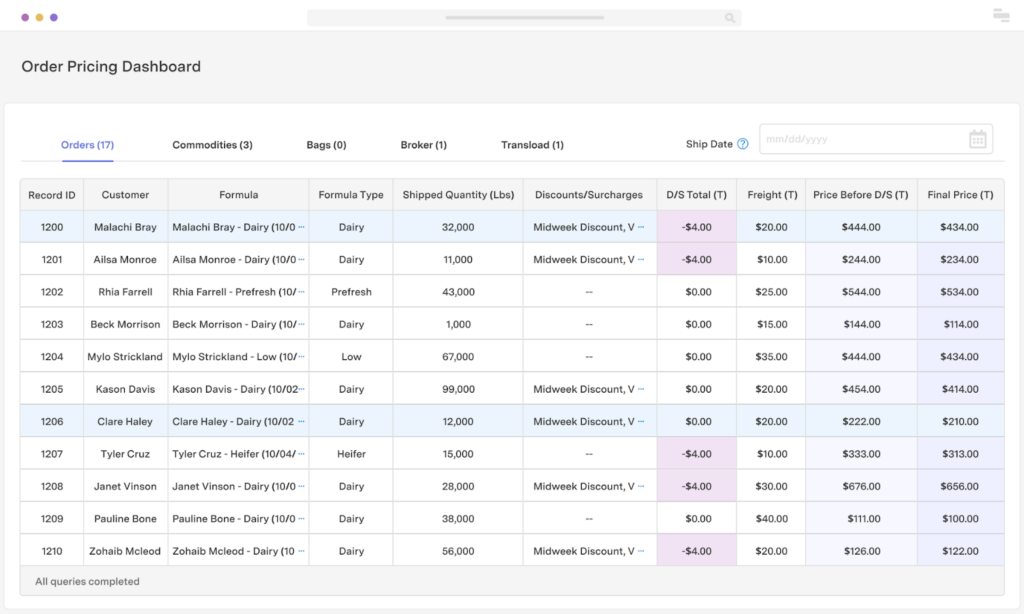
What changes with web data: Pricing moves from periodic updates to continuous optimization.
Generative AI models ingest:
- Competitor price movements
- Discount frequency and depth
- Marketplace positioning
Output:
- Suggested price adjustments by SKU
- Discount timing recommendations
- Margin vs. competitiveness trade-offs
Key insight: Static pricing models optimize for yesterday. Web-fed AI optimizes for current market elasticity.
2. Hyper-Personalized Product Recommendations
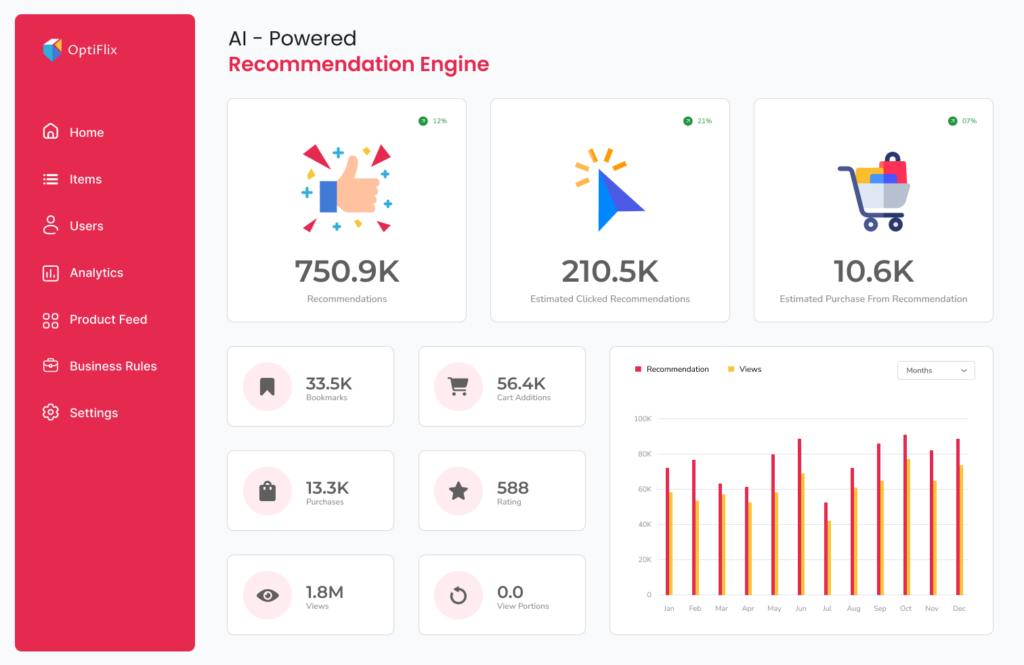
What changes with web data:
Personalization shifts from historical behavior → real-time intent + market context.
Inputs include:
- Trending products across marketplaces
- Real-time reviews and sentiment
- Demand spikes in categories
Output:
- Context-aware recommendations
- Trending-first merchandising
- Dynamic bundling suggestions
Key insight: Without external signals, personalization becomes echo-chamber behavior.
3. Automated Product Content Generation
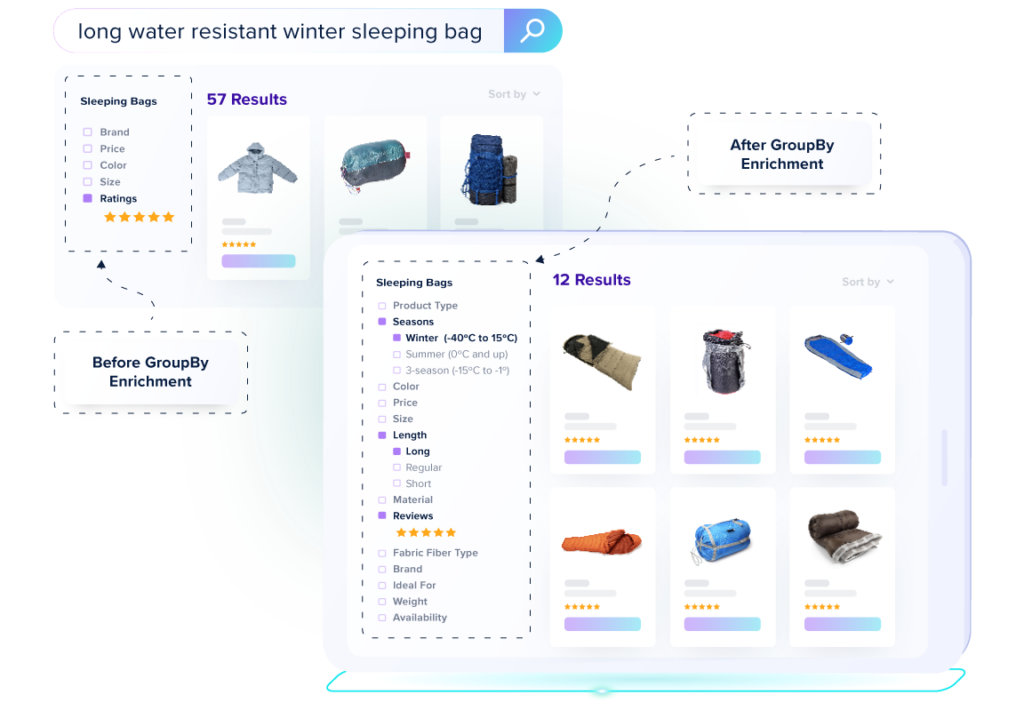
What changes with web data:
Content generation moves from generic → market-aligned positioning.
Inputs:
- Competitor product descriptions
- Feature comparisons across SKUs
- Customer reviews and objections
Output:
- SEO-optimized product descriptions
- Differentiated positioning angles
- Feature-led storytelling aligned with demand
Key insight: AI content without market context leads to commoditized messaging.
4. Demand Forecasting and Inventory Optimization
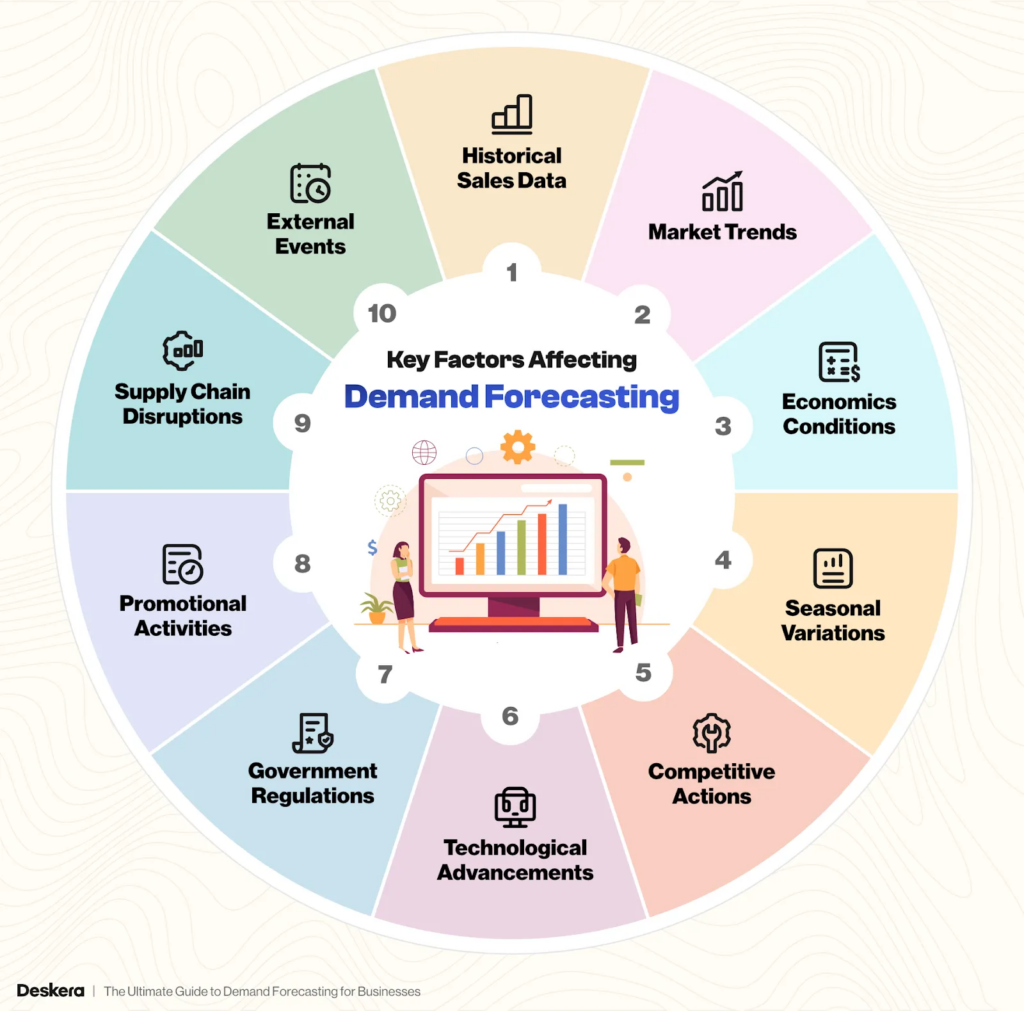
What changes with web data:
Forecasting moves from internal sales history → market-wide demand sensing.
Inputs:
- Competitor stock availability
- Category-level demand signals
- Promotion cycles across platforms
Output:
- Demand forecasts adjusted to market signals
- Inventory allocation recommendations
- Early detection of demand spikes
Key insight: Internal data shows what happened. Web data signals what’s about to happen.
5. Competitive Intelligence and Assortment Strategy
What changes with web data: Assortment strategy moves from gut-feel decisions to market-validated positioning. Inputs: competitor SKU listings, category launches, pricing gaps, assortment changes.
Output: whitespace analysis, category gap identification, positioning recommendations.
Key insight: Without external market signals, assortment decisions optimize for your history, not the market’s future.
Challenges in Using Web Data for Generative AI
The Real Constraint Is Data Reliability, Not Model Capability
Most teams assume that improving generative AI performance is a model problem. In practice, it is a data reliability problem. Retail environments change too quickly for static or fragile data pipelines to keep up.
Retailers that implement real-time pricing intelligence see measurable gains, typically in the range of 3–8% margin uplift and up to 20% faster response to competitor price changes. However, these outcomes depend on one condition: the data must be fresh and continuously available. When latency increases or pipelines break, that advantage disappears.
At the same time, a significant portion of scraping systems fail under real-world conditions. Estimates suggest that 30–40% of pipelines break within weeks due to site changes, rendering complexity, or anti-bot measures. As a result, data teams end up spending most of their time maintaining pipelines instead of generating insights or improving models. This creates a structural bottleneck where AI systems cannot outperform the quality and reliability of their inputs.
Why Web Data Pipelines Break in Practice
Web data pipelines are inherently fragile because they operate on systems that are outside your control. Websites change structure frequently, often without notice. Elements move, class names are updated, and entire page layouts are redesigned. What worked yesterday can silently fail today.
On top of this, modern websites rely heavily on JavaScript rendering, which makes extraction more complex. Anti-bot systems introduce another layer of instability by blocking requests, injecting CAPTCHAs, or serving different content based on geography or behavior.
These issues do not always cause visible failures. In many cases, pipelines continue running but return incomplete or incorrect data. This is more dangerous than outright failure because the system appears operational while feeding degraded inputs into downstream AI models.
Inconsistency Across Sources Distorts AI Outputs
Even when data is successfully collected, it is rarely consistent across sources. The same product can appear with different names, attributes, or category structures depending on the platform. Key fields may be missing in one source and present in another.
Without proper normalization, generative AI systems struggle to interpret this data correctly. Pricing comparisons become unreliable because products are not matched accurately. Recommendation systems degrade because attributes are incomplete or inconsistent. Over time, this leads to outputs that look coherent but are fundamentally misaligned with the actual market.
Consistency is not a formatting issue. It is a prerequisite for any system that depends on structured reasoning.
Latency Turns Good Data Into Useless Data
In retail, the value of data is directly tied to timing. A competitor price drop, a sudden stockout, or a surge in demand creates a short window of opportunity. If your system captures that signal too late, the decision value is already lost.
This is where many pipelines fail. They may deliver accurate data, but with a delay that makes it irrelevant. When pricing systems, recommendation engines, or inventory models operate on delayed inputs, they become reactive instead of adaptive.
Generative AI amplifies this issue. It produces outputs that appear current, but are actually based on outdated signals. This creates a false sense of accuracy and leads to decisions that lag behind the market.
Why Generative AI Amplifies These Failures
Generative AI does not correct data problems. It scales them.
If the input data is incomplete, the output becomes biased. If the data is inconsistent, the output becomes unreliable. If the data is delayed, the output becomes irrelevant. The system still produces results, but those results no longer reflect reality.
This is why many AI initiatives appear to work in controlled environments but fail in production. The model behaves as expected, but the data feeding it does not.
Why PromptCloud Becomes a Critical Layer
The common mistake is treating web data as a tooling problem. Most solutions provide APIs, proxies, or scraping frameworks. These are building blocks, not complete systems. They still require internal teams to manage pipeline stability, handle failures, and maintain data quality over time.
PromptCloud operates at a different layer. It focuses on delivering structured, reliable datasets through managed pipelines. This shifts the responsibility of maintaining data continuity and quality away from internal teams.
Instead of dealing with broken scrapers, teams receive normalized, analysis-ready data that can be directly integrated into AI systems. The emphasis is on reliability, consistency, and scale rather than raw extraction capability.
What This Changes for AI-Driven Retail Systems
When the data layer is stable, generative AI systems start behaving as intended. Outputs align with current market conditions because the inputs are continuously updated and consistent across sources.
This changes how teams allocate effort. Engineering time moves away from fixing pipelines and toward improving models and decision systems. AI outputs become more trustworthy because they are grounded in real-time data.
The difference is not incremental. It is structural. Systems built on unreliable data remain reactive and fragile. Systems built on reliable data become adaptive and capable of driving real business impact.
Bottom Line
Generative AI in retail does not fail because of limitations in the models. It fails because the data layer cannot keep up with the speed and complexity of the market.
The advantage does not come from better algorithms alone. It comes from ensuring that those algorithms are continuously fed with data that is current, consistent, and complete.
Further Reading: Data Pipelines, AI, and Retail Intelligence
- Real-Time Web Data Pipelines for LLM Agents
- Pricing Intelligence 2.0: Event-Triggered Scrapers
- Scraped Data Quality Playbook
- Web Scraping Explained: From Scripts to Systems
McKinsey – The State of AI Global Report: how AI is driving measurable business impact across industries.
Stop unreliable retail data pipelines. Start making AI decisions with confidence.
Get clean, structured web data delivered on your cadence from a managed pipeline built around your specific sources and schema requirements.
• No contracts. • No credit card required. • No scraping infrastructure to maintain.
FAQs
1. Why does generative AI need real-time data in retail?
Generative AI needs real-time data in retail to ensure its outputs reflect current market conditions such as pricing, availability, and demand. Without fresh data, AI systems rely on outdated inputs, leading to inaccurate recommendations and missed revenue opportunities.
2. How is web scraping used in generative AI systems?
Web scraping is used in generative AI systems to collect real-time external data such as competitor pricing, product details, and customer reviews. This data is structured and fed into AI models to improve decision-making, personalization, and forecasting accuracy.
3. What happens when AI models use outdated data?
When AI models use outdated data, their outputs become misaligned with real-world conditions. This can result in incorrect pricing decisions, irrelevant recommendations, and poor customer experience due to stale or inaccurate insights.
4. What is a web data pipeline for AI systems?
A web data pipeline for AI systems is a structured process that collects, cleans, and delivers web data in a format that models can use. It ensures continuous data flow, consistency, and freshness required for reliable AI performance.
5. What are the challenges of scaling web scraping for AI?
The main challenges of scaling web scraping for AI include frequent website changes, anti-bot protections, inconsistent data formats, and maintaining data quality across sources. These issues make it difficult to ensure reliable and continuous data feeds for AI systems.















