



Recently the world started recovering from the FIFA World Cup football fever that ended with France emerging as the winner. Before moving further, let’s check out the context — the final match was contested by France and Croatia and played at the Luzhniki Stadium in Moscow, Russia, on 15 July 2018 at 3 pm (GMT time zone). France won the match 4-2, which included one penalty and own goal from Croatia.
Just like any other social media, Twitter was also abuzz with fans and viewers constantly tweeting about the match as it progressed. The trending hashtag for the event was #WordCupFinal. This study will focus on the tweets extracted in between 3 pm GMT and little over 7.30 pm GMT for the above-mentioned hashtag. The final data set comprises of more than 200,000 original tweets (doesn’t include retweets). Our twitter data analysis will answer the following questions:
1. What were the top hashtags used during the match?
2. Which were the top languages in terms of tweet count?
3. Which twitter handles were mentioned the most?
4. What was the character length for majority of the tweets?
5. What were some popular tweets in terms of retweets and likes?
Note that this study doesn’t cover the text mining techniques; however, they can be applied using the methods already described in Taylor Swift’s song lyrics data visualization post.
[call_to_action title="Download the data set for free" icon="icon-download" link="https://app.promptcloud.com/users/sign_up?target=data_stocks&itm_source=website&itm_medium=blog&itm_campaign=dataviz&itm_term=fifa-tweets&itm_content=data-mining" button_title="" class="" target="_blank" animate=""]Sign up for DataStock via CrawlBoard and click on the 'free' category to download the data set![/call_to_action]
Feel free to download the Twitter data set, if you would like to replicate the code given in this post or experiment with the data.
Top hashtags
Let’s first load the required packages and move to the `hashtags` column for the analysis.
[code language=”r”]
# Frequency of the hashtags
library("dplyr")
library("ggplot2")
library("magrittr")
library("scales")
library("ggrepel")
fifa_tweets <- read.csv(file.choose())
# Optional configuration to show larger numbers without scientific notation
options(digits=22)
# Getting the hashtags from the list format
fifa_hashtags <- unlist(strsplit(as.character
(unlist(fifa_tweets$hashtags)),
‘^c(|,|"|)’))
# Formatting by removing the white spaces
hashtags <- sapply(fifa_hashtags, function(y) nchar(trimws(y)) > 0 & !is.na(y))
# Converting to data frame
hashtag_df <- as_data_frame(table(tolower(fifa_hashtags[hashtags])))
hashtag_df <- hashtag_df[with(hashtag_df,order(-n)),]
hashtag_df <- hashtag_df[2:11,]
ggplot(hashtag_df, aes(x = reorder(Var1, n), y=n)) +
geom_bar(stat="identity", fill="#00D4C9")+
coord_flip() +
theme_minimal() +
xlab("#Hashtags") + ylab("Count") +
ggtitle("Top hashtags used during FIFA World Cup final excluding #WorldCupFinal") +
theme_minimal()
[/code]
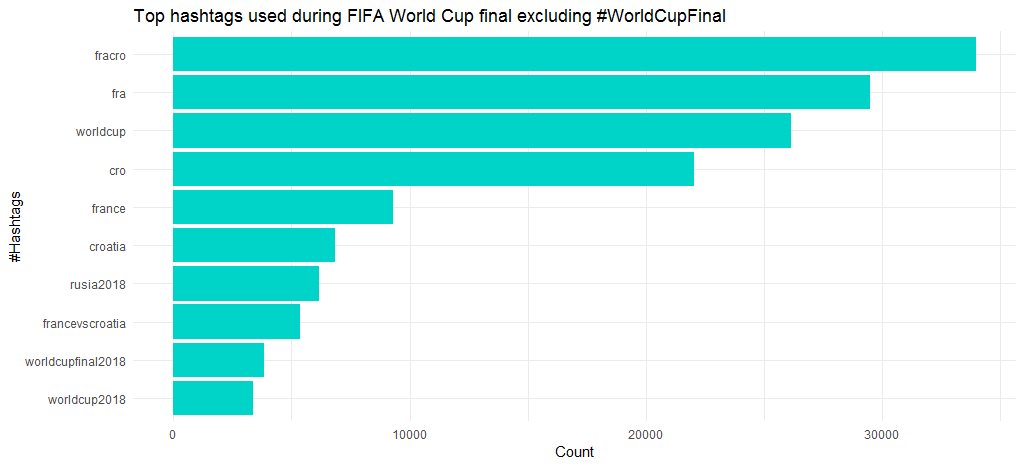
The following chart shows that other popular hashtags apart from #WordCupFinal are #fracro, #fra, #worldcup and #cro. It is certain that the buzz for France was more than Croatia, especially since they won the match.
Top Languages
Let’s now check out the languages in which tweets were posted.
[code language=”r”]
lang_df <- count(fifa_tweets,lang) %>%
arrange(desc(n)) %>%
slice(1:15)
ggplot(data=lang_df, aes(x = reorder(lang, n), y=n)) +
geom_bar(stat = ‘identity’, fill="#00D4C9") +
coord_flip() +
xlab("Languages") + ylab("Count") +
ggtitle("Top languages used in tweets for FIFA World Cup Final") +
theme_minimal()
[/code]
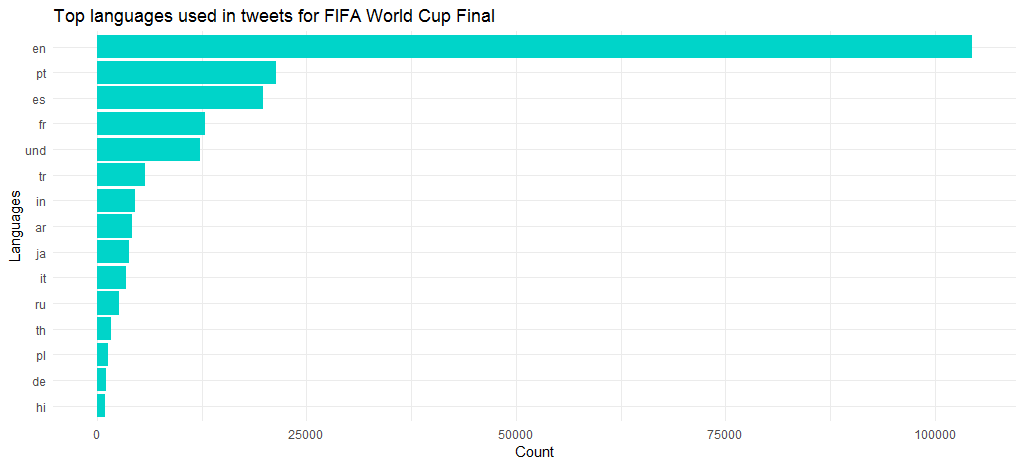
Apart from English, other popular languages were Portuguese, Spanish, French and Turkish. Note that `und` stands for undefined.
Top Twitter handles
Now, let’s find out the popular twitter users who were mentioned in various tweets.
[code language=”r”]
# Getting the mentions from the list format
mentions_split <- unlist(strsplit(as.character
(unlist(fifa_tweets$mentions_screen_name)),
‘^c(|,|"|)’))
# Formatting by removing the white spaces
mentions <- sapply(mentions_split, function(y) nchar(trimws(y)) > 0 & !is.na(y))
# Converting to data frame
mentions_df <- as_data_frame(table(tolower(mentions_split[mentions])))
mentions_df <- mentions_df[with(mentions_df,order(-n)),]
mentions_df <- mentions_df[1:10,]
ggplot(mentions_df, aes(x = reorder(Var1, n), y=n)) +
geom_bar(stat="identity", fill="#00D4C9")+
theme_minimal() +
coord_flip() +
xlab("Twitter handles") + ylab("Count") +
ggtitle("Top Twitter handles mentioned during FIFA World Cup final") +
theme_minimal()
[/code]
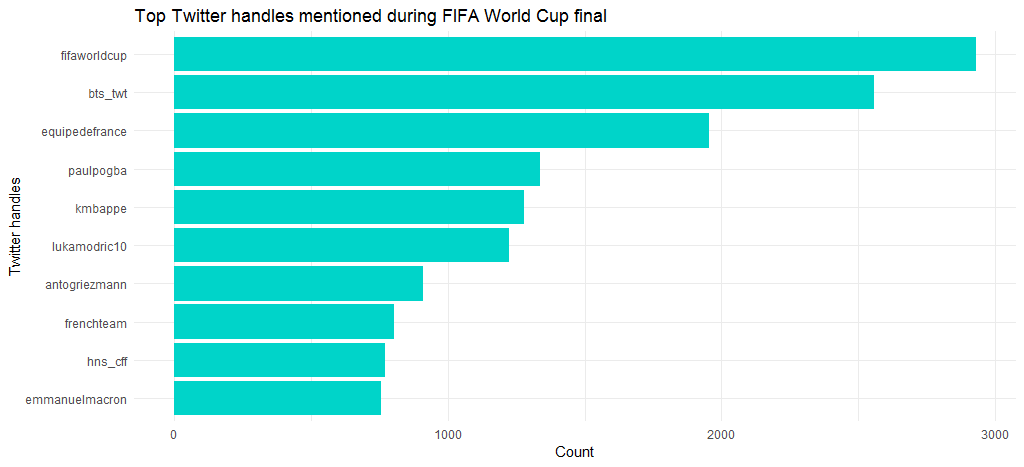
This shows that Korean band BTS garnered more than 2500 mentions owing to their song for the final match. And players like Paul Pogba (French), Kylian Mbappé (French), Luka Modrić (Croatian), Antoine Griezmann (Antoine Griezmann) were among the top 10 mentioned users. Note that Kylian Mbappé became the youngest since Pele to score in World Cup final.
Character length distribution
What was the most common range for character length in tweets? Let’s find out!
[code language=”r”]
ggplot(fifa_tweets) + aes(x=display_text_width,y = ..count../sum(..count..)) +
geom_density(stat=’bin’, binwidth=15, alpha = .4, fill = "#1ed7d1") +
scale_y_continuous(labels = percent,name = "Percentage") +
scale_x_continuous(breaks = scales::pretty_breaks(n = 20),name = "Character length") +
ggtitle("Distibution of character length of the tweets during FIFA World Cup final") +
theme_minimal()
[/code]
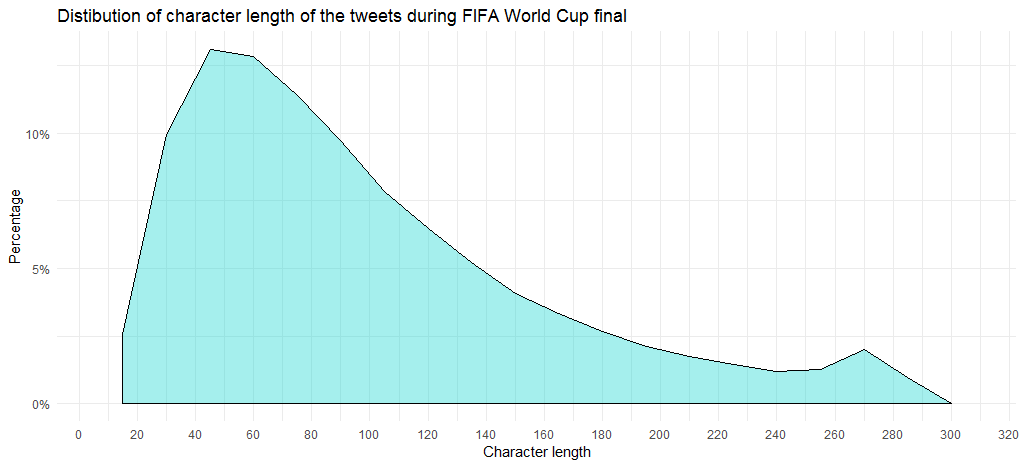
The chart shows that majority of the tweets have 45-60 character length. Note that the average length stands at 99.
Popular tweets
Now we would find out some of the most popular tweets posted by the users.
[code language=”r”]
ggplot(fifa_tweets, aes(x=favorite_count, y=retweet_count)) +
geom_text_repel(data = fifa_tweets[fifa_tweets$favorite_count > 5000 | fifa_tweets$retweet_count > 2000,],
aes(label = name),
box.padding = unit(0.45, "lines")) +
geom_point(color = "#00D4C9") +
xlab ("Favorite count") + ylab("Retweet count") +
ggtitle("Top tweets posted during FIFA world Cup final") +
theme_minimal() +
theme(plot.margin=unit(c(.2,.5,.2,.2),"cm"))
[/code]
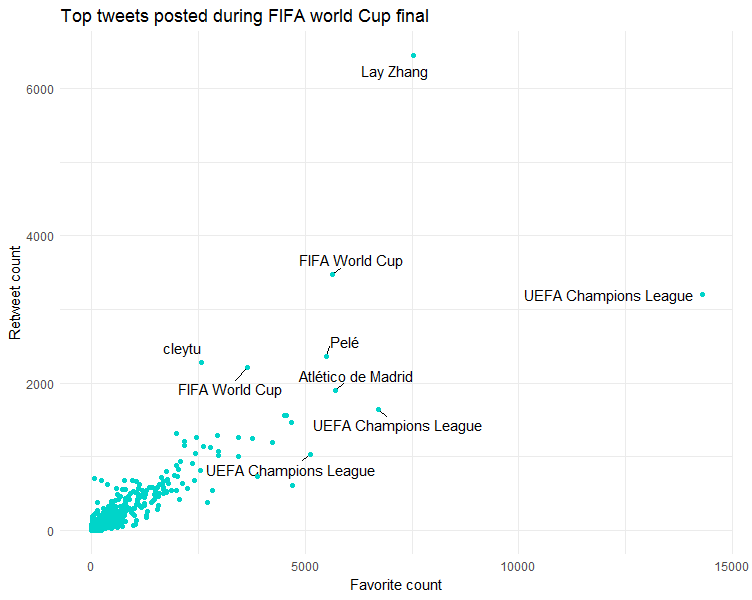
This shows that the top tweets in terms of favorites and retweets were posted by UEFA Champions League, Lay Zhang, FIFA World Cup and Pelé who is regarded as the greatest footballer of all time.
Let’s check out the tweet posted by Pelé:
If Kylian keeps equalling my records like this I may have to dust my boots off again… // Se o @KMbappe continuar a igualar os meus records assim, eu vou ter que tirar a poeira das minhas chuteiras novamente…#WorldCupFinal
— Pelé (@Pele) July 15, 2018
Over to you
We performed exploratory data analysis on the Twitter data set to find out the most used hashtags, popular tweets, character length of the tweets along with language and most mentioned twitter account.. Now, it’s time for you to download the data set and perform your analysis — text mining techniques can be applied on the tweet text for n-grams, word cloud, sentiment analysis and more.
















