



Table of Contents
show
Data for most machine learning projects are collected through multiple sources such as data scraping, getting people to fill survey forms, etc. Usually, a high percentage of this data is unlabelled or mislabelled. By unlabelled data, here we are referring to data which has not been tagged with labels specifying their characteristics, classification or properties. But all this data needs to be labelled properly before going on with your ML project. And this task does take a lot of time. As per a report by analytics firm Cognilytica, as much as 25% of the time allocated to a machine learning project is spent in data labeling. 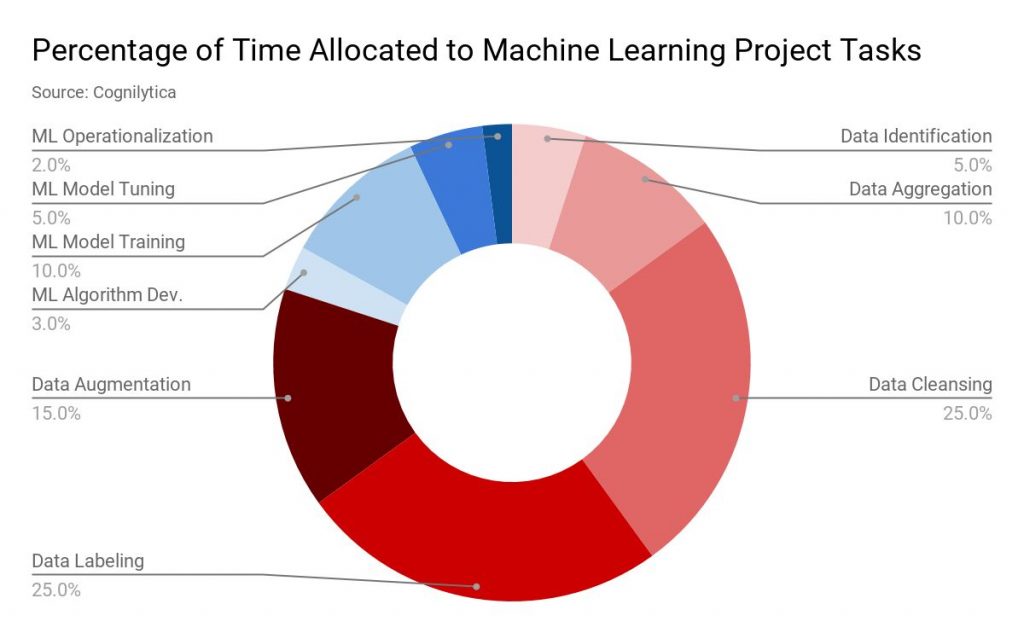 data labeling” width=”1200″ height=”742″ />
data labeling” width=”1200″ height=”742″ />
Who should perform data labeling?
Getting data-scientists in your team to label raw data might not be a good idea. For one, they have a lot of other work to do, and their time is best spent working on algorithms and coming up with solutions to problems. Instead, you should have a separate team that should have two parts- 1. Data Labelling Teaming 2. Quality and Assurance team.
The first is self-explanatory, but the second is even more important since you would not want poorly labelled data ruining your entire research project or skewing the results. When it comes to keeping a check on the labelled data, two factors must be taken into account-
- Accuracy- This measures how close the labelling is to the ground truth. That is, are all horses marked as horses and are all cats labelled as cats.
- Quality- When working with a large data labeling team this is very important. When multiple people are classifying parts of the same dataset, it is a must that all of them use the same yardstick. If one labels a 2 BHK flat as small, 3 BHK as medium and 4+ BHK as large, then all should be following the same.
The numerous problems of low-quality data
First, when you train the model, you would be getting an incorrect model. Again when validating the model, you would face the ire of unclean data. Whoever is labelling data must have both domain and contextual knowledge. This would help you create high quality and structured datasets for your machine learning projects. In certain scenarios, two or more words might mean the same thing. If the people doing the labelling do not have context, they may label the items under different tags. For the best quality data labelling, people should have domain knowledge as well as a fundamental understanding of the industry which is served by your data.
Machine Learning, as we all know is an iterative process. Data labelling may change or evolve as you test your models and learn from its results. So for future iterations, you might need to prepare new labels or enhance existing ones. Hence, your data labelling team should have the flexibility to enhance labels for changes in the ML algorithm.
When you have a lot of data being labeled there are certain things that you would need to keep your eyes on, and maintain.
- Gold standard – For every labeling question, there’s a correct answer. You can measure correct and incorrect labels to find how good your data is.
- Sample review – You can collect a small sample of labeled data and check it for accuracy. Its accuracy percentage would be expected to be spread across the entire dataset itself.
- Consensus – When there’s a debate while labeling a particular debate-able piece of data, whatever opinion is the most popular, should be taken as the common consensus.
Some common and important mistakes to avoid with data labeling
When delving into the labeling of data for a machine learning project, it is very easy to get carried away and build castles in thin air. You have to keep your foot on the ground and think realistically, have a limited and fixed set of labels and follow certain rules when you go about your labeling business.
WhiteSpaces, punctuations and case sensitivity
When labelling data, whitespaces, and some other punctuations must be handled with care. Say one person tags an image as- “African elephant”. Someone else tags it as “African-elephant” And yet another person tags it as “African elephant”. Now you see where we are getting. Hence it is very important to make sure that you finalise the tags that are to be used, as well as their formats beforehand and any new tags that are added should be communicated to all. At the same time, single spaces should not end up becoming more than one space, and this can be taken care of by a simple Python script.
Another problem that can crop up is the scenario of nested tagging. Say you have the sentence- “The King of England, Edward the third …”. Now one may tag it as a. {1: “king”, 2: “England”, 3: “Edward the third”}
While it may also be tagged as-
b. {1: “England”, 2: “king”, 3: “Edward the third”}
The first one is correct since we used the tags in the order in which it appeared in the sentence. But then the same words can appear in a different order, meaning the same thing, and end up with a completely different order of tags. This is why it would be better to use the second format in all scenarios. This kind of decision needs an understanding of both the subject and the topic. Different people labeling the dataset must use the same format when using nested labels.
Adding new label to your list, midway
Midway through your labeling task, you might realize that you would be needing a new label, not present in the master list. You might go on to add it to the master list and inform everyone to use this label as well as and when required. This is highly discouraged. The simple reason being that the data that has already been labeled by you and the others would have to be rechecked as well, to see if the label fist in the already processed data. It’s always best to get the list of labels ready before starting with the labeling of any dataset.
Having a long list of labels in your master-list
A great way to increase project costs and decrease data quality is to have a long list of labels. Say you are labelling data as reptiles and mammals. That should be simple and fast. Now say you have the names of 100 reptiles and mammals and you are using those for labeling. There are bound to be errors in the labeling. It will also be slow and your problems will only get compounded once the errors are made. It is always recommended to keep the list of tags small and conduct separate studies on separate datasets.
Start data labeling
It is not enough to have amazing data scientists and machine learning engineers when you are tackling problems related to artificial intelligence. It is just as important to have an efficient data collection team, as it is to have an intelligent data cleaning system and some experienced hands labeling the data that will ultimately be the food for the ML models.















