




Sentiment Monitoring has been used for Brand Monitoring or to spot trends in retail customers for a while now. In the Financial Sector, Sentiment Monitoring has seen a recent surge. This is due to the increase in the number of retail investors who often debate on social media pages and discussion boards. Opinions and statements made on these platforms have resulted in massive volatility in the market and have broken risk models.
Tools of the Game
Python is the most commonly used language when it comes to natural language processing as well as sentiment analysis. This can be attributed to its easier learning curve and the presence of multiple third-party libraries. These libraries come with built-in functionalities that you just need to run on top of your data. Understanding the math behind these functions is optional. Anyone can use these functions based on the outcome that is to be derived and the available data.
Some of the common functionalities that we use while breaking down the text to evaluate it are–
- Tokenization– Breaking a large sentence into individual words.
- Stemming– Converting words to their base forms, for example walking will be converted to walk.
- Lemmatization– This is used to find related words, and it differs from stemming due to higher complexity and requires more time. An example of this would be converting best to good, or corpora to corpus.
- Tagging parts of speech– This involves the use of inbuilt functionality that labels parts of your texts grammatically.
The process of opinion mining
Sentiment Analysis or Opinion Mining is a sub-branch of natural language processing that deals with the classification of text into different headings like happy, sad or neutral. Often Positive or Negative replaces happy or sad. In the case of a large amount of data, you might even see 5 headers with 2 in between being moderately positive and moderately negative.

It is usually used on short texts like tweets or comments to have higher accuracy. In case you use it on a large paragraph, which may have multiple emotions in it, the algorithms tend to get confused and produce inaccurate results. Also, for larger pieces of text, the final sentiment that is expressed can be a subjective interpretation– something that NLP – based tools can’t handle yet.
Sorting Tweets based on Sentiments
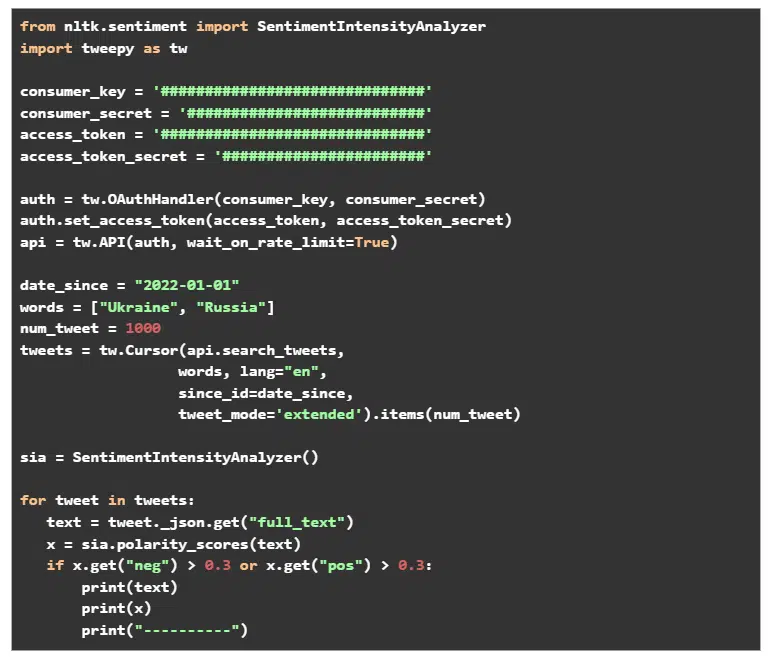
The most common data that is analyzed for conducting sentiment analysis is tweets. Hence, we will be showing the use of one of the most common sentiment analyzer functions in Python on a series of tweets. The 4 keys that have been defined right after importing nltk and tweepy, are provided by Twitter once you apply for developer access, by answering a few basic questions.
We search for tweets containing Ukraine or Russia, the two countries that are at the forefront of World News today and which are likely to find tons of mentions in tweets. For each tweet, we analyze the sentiment associated with it and print the tweet and the sentiment metrics only if the positive or negative sentiment related to it is greater than 30%. You may choose a different value based on your use case.
We have shown some of the results that we obtained below. As you can see, the ‘neg’ value related to each text is higher than 0.3 (or 30%). The ‘pos’ or positive value is almost 0.0 for all of these tweets. This is expected since tweets discussing war or its effects are almost always negative.
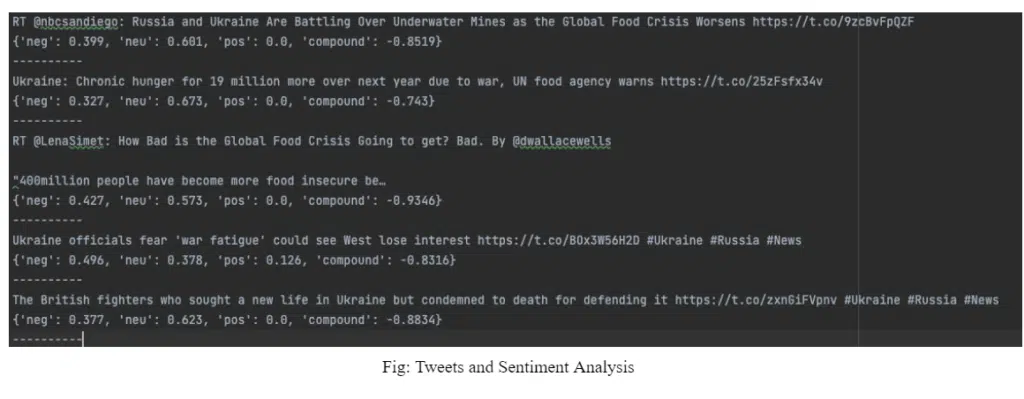
Similarly, one could find online texts like tweets or comments or articles with mentions of company names, CEOs, affiliates, and more, to figure out if any negative or positive content has been published. In case such content is found, the next step would be to evaluate its possible effect on the stocks of that brand.
Impact on the Financial Market
Reddit, a news aggregation and discussion , has recently had a large impact on the financial sector and the stock market. In January 2021, retail investors decided to take on Wall Street in an event which was later termed the “GameStop short Squeeze”. Users of the subreddit wallstreetbets participated heavily in buying stocks of GameStop and a few others and raising the stock prices, thereby “squeezing” the short positions held by Wall Street.
This was supposed to be a retaliation for Wall Street betting against GameStop, a brick-and-mortar gaming store that was affected by the Covid pandemic like many other businesses. To cover up the losses, hedge funds had to buy GameStop stocks themselves, thus pushing the prices even higher. So much volatility in the market resulted in popular retail brokers like Robinhood having to stop trading in certain stocks since they did not have collateral at clearing houses for executing the trades. All this resulted in a further frenzy, accusations and lawsuits.
Since Social Media wasn’t being actively monitored nor were its effects factored into the risk models employed by financial institutions, events like these could not be predicted. While institutional buyers are expected to have a large hand in how the stock market behaves, social media trends and discussions can have an even larger impact. Also, the volatility due to such changes may cross thresholds that might be deemed to be hard barriers. Companies specializing in building financial models will need to use sentiment analysis on social media data and the latest news articles to better judge the markets.















